







 博客讨论了在存储时间段数据时如何判断与已有记录是否存在时间冲突。提出了四种冲突情况,并指出只需检查startDate小于等于table_end_date且endDate大于等于table_start_date即可判断冲突,简化了检测条件。欢迎对算法优化有兴趣的小伙伴留言交流。
博客讨论了在存储时间段数据时如何判断与已有记录是否存在时间冲突。提出了四种冲突情况,并指出只需检查startDate小于等于table_end_date且endDate大于等于table_start_date即可判断冲突,简化了检测条件。欢迎对算法优化有兴趣的小伙伴留言交流。
项目中会有遇到这种情况,存储时间段时,需要判断已存在记录中是否有时间段冲突,
例: 要存储startDate,endDate 这个时间段,需要判断与mysql数据库表中的table_start_date,table_end_date是否有冲突
总共分四种冲突情况
1、 startDate >= table_start_date 且 endDate<=table_end_date
2、 startDate <= table_start_date 且 endDate<=table_end_date
3、 startDate <= table_start_date 且 table_end_date<=endDate
4、 startDate >= table_start_date 且 table_end_date<=endDate
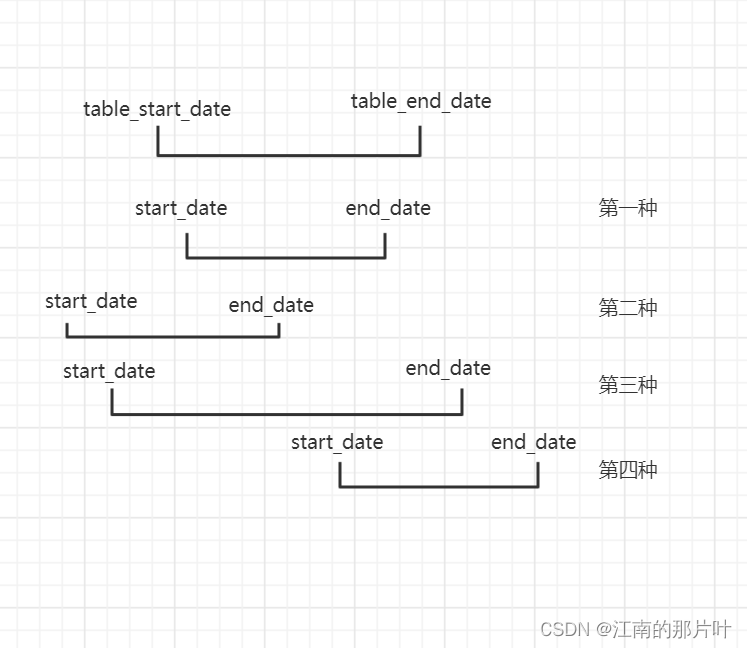
我们可以发现
这四种情况中无论哪种情况 startDate <= table_end_date且endDate>=table_start_date
那我们判断有冲突的时候就可以写
startDate <= table_end_date AND endDate>=table_start_date
没有冲突就反向
startDate > table_end_date OR endDate < table_start_date
个人见解,如果有不同意见的小伙伴可以留言交流哦


















 3195
3195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











