







1.下载开源项目:https://github.com/PaddlePaddle/PaddleOCR
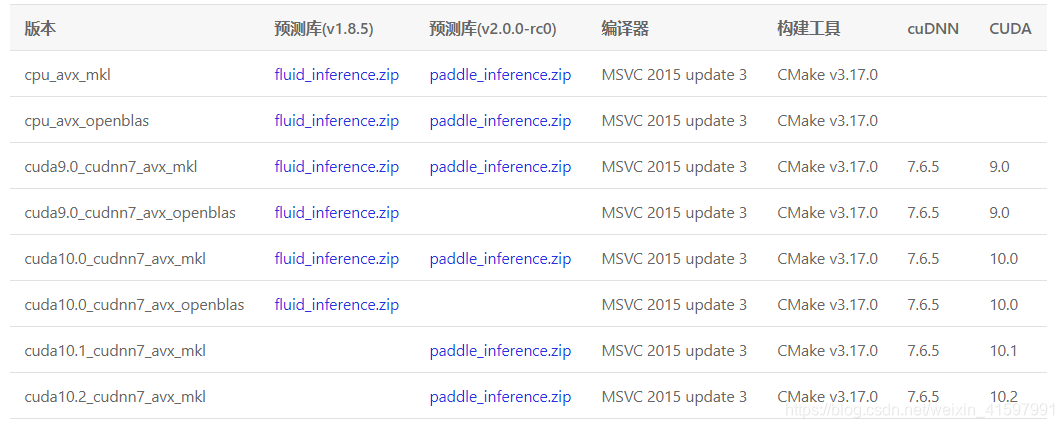
我下载的是预测库v2.0-rc0版本(paddle_inference.zip)
将项目和预测库解压到同意目录下,便于后续进行编译。

2.使用vs2015进行编译,我使用的是vs2015 update3版本。编译运行参考:
官网教程:
1.下载开源项目:https://github.com/PaddlePaddle/PaddleOCR
我下载的是预测库v2.0-rc0版本(paddle_inference.zip)
将项目和预测库解压到同意目录下,便于后续进行编译。
2.使用vs2015进行编译,我使用的是vs2015 update3版本。编译运行参考:
官网教程:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























