









一种是for循环方式,一种是 stream 方式;在处理数据量很大是会相差上千倍。
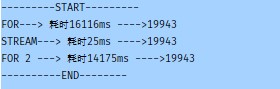
处理数据量大时,使用stream 方式,很小的数据用for就可以;
处理100000条数据处理结果:
| 方式 | 耗时 |
| for循环 | 16683ms |
| stream 方式 | 26ms |
处理100条数据处理结果:
| 方式 | 耗时 |
| for循环 | 1ms |
| stream 方式 | 3ms |
示例代码:kotlin
import java.util.*
import java.util.stream.Collectors
import kotlin.collections.ArrayList
class Test {
companion object {
private var i0 = 0
private var i02 = 0
private var i1 = 0
@JvmStatic
fun main(args: Array<String>) {
println("---------START---------")
val i=99999
// val i = 99
val r = Random()
val sList = ArrayList<String>()
for (i in 0..i) {
sList.add(java.lang.String.valueOf(r.nextInt(500000) + 1))
}
val cList = ArrayList<String>()
for (i in 0..i) {
cList.add((i + 1).toString())
}
val s1 = System.currentTimeMillis()
doubleForMethod(sList, cList)
val e1 = System.currentTimeMillis()
println("FOR--->" + (e1 - s1) + "ms ---->" + i0)
val s2 = System.currentTimeMillis()
streamMethod(sList, cList)
val e2 = System.currentTimeMillis()
println("STREAM--->" + (e2 - s2) + "ms ---->" + i1)
val s3 = System.currentTimeMillis()
doubleForMethod2(sList, cList)
val e3 = System.currentTimeMillis()
println("FOR 2 --->" + (e3 - s3) + "ms ---->" + i02)
println("----------END--------")
}
private fun streamMethod(sList: List<String>, aList: List<String>) {
// 把班级列表转成map,那么班级id就是唯一的id
val noClassMap: Map<String, String> =
aList.stream().collect(Collectors.toMap({ t -> t }) { t -> t })
sList.stream().forEach { h: String ->
if (noClassMap.containsKey(h)) {
i1++
}
}
}
// for双层循环的方式
private fun doubleForMethod(sList: List<String>, aList: List<String>) {
for (i in sList.indices) {
val student = sList[i]
for (j in aList.indices) {
val noClass = aList[j]
if (student == noClass) {
i0++
}
}
}
}
// for双层循环的方式
private fun doubleForMethod2(sList: List<String>, aList: List<String>) {
sList.forEach {
if (aList.contains(it)) {
i02++
}
}
}
}
}
示例代码:Java
public class Run {
private static int i0=0;
private static int i1=0;
public static void main(String[] args) {
Random r = new Random();
ArrayList sList = new ArrayList<String>();
for (int i = 0; i < 100000; i++) {
sList.add(String.valueOf(r.nextInt(500000) + 1));
}
ArrayList cList = new ArrayList<String>();
for (int i = 0; i < 100000; i++) {
cList.add(String.valueOf(i + 1));
}
long s1 = System.currentTimeMillis();
doubleForMethod(sList, cList);
long e1 = System.currentTimeMillis();
System.out.println("FOR--->" + (e1 - s1) + "---->" + i0);
long s2 = System.currentTimeMillis();
streamMethod(sList, cList);
long e2 = System.currentTimeMillis();
System.out.println("STREAM--->" + (e2 - s2) + "---->" + i1);
)
// for双层循环的方式
private static void doubleForMethod(List<String> sList, List<String> fList) {
for (int i = 0; i < sList.size(); i++) {
String student = sList.get(i);
for (int j = 0; j < fList.size(); j++) {
String noClass = fList.get(j);
if (student.equals(noClass)) {
i0++;
}
}
}
}
private static void streamMethod(List<String> sList, List<String> fList) {
// 把班级列表转成map,那么班级id就是唯一的id
Map<String, String> noClassMap = fList.stream().collect(Collectors.toMap(t -> t, t -> t));
sList.stream().forEach(h -> {
if (noClassMap.containsKey(h)) {
i1++;
}
});
}
}

















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











