from sklearn.cluster import MeanShift, estimate_bandwidth
from sklearn.externals import joblib
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
import datetime
import xlrd
import csv
import random
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
os.chdir(r'E:\葡萄牙波尔图市出租车分析')
#用pandas直接读取csv文件到df
df=pd.read_csv('train.csv')
traj_sample=random.sample(list(df.POLYLINE),100000) #随机从170w条数据中选取10万
del df #由于上一步读取了太多数据,删除该变量从而释放内存空间
#将读取的10w条轨迹数据重新用CSV文件保存
import csv
with open(r'E:\1_traj_10000_sample.csv','w') as f:
writer=csv.writer(f,lineterminator='\n')
for i in traj_sample:
writer.writerow([i])
print(len(traj_sample))
import csv
import re
haRegex=re.compile(r'\[.*\]')
dest_point_adj=[]
#traj_sample_adj=[]
with open(r'E:\1.5_traj_adj_10000_sample.csv','w') as f:
writer=csv.writer(f,lineterminator='\n')
for i in traj_sample:
if haRegex.search(i) and len(eval(i))<1000 and i!='[]' and eval(i)[-1][0]<=-8.5 and eval(i)[-1][0]>=-8.7 and eval(i)[-1][1]<=41.24 and eval(i)[-1][1]>=41.04: #引入正则表达式对空数据,轨迹过长的数据以及不在波尔图市的数据进行一些处理
dest_point_adj.append(eval(i)[-1])
#traj_sample_adj.append(eval(i))
writer.writerow([i,eval(i)[-1]])
with open(r'E:\2_dest_point_adj_10w.csv','w') as f:
writer=csv.writer(f,lineterminator='\n')
for i in dest_point_adj:
writer.writerow([i[0],i[1]]) #这里重新处理各轨迹终点数据到excel里,方便后面在excel里进行一些格式调整
#统计每个标签有多少数
arr_flag=np.zeros(4000)
for i in clf.labels_:
arr_flag[i]=arr_flag[i]+1
print(arr_flag)
k=0
for i in arr_flag:
if (i>0):
k+=1
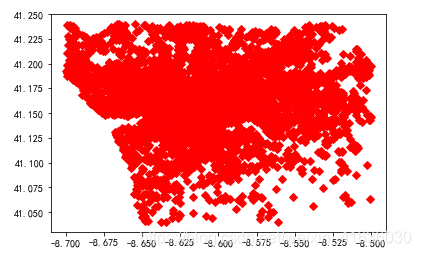
print(k) #一共有3235个簇
centroids_centres=clf.cluster_centers_
#print (centroids_centres) #显示中心点坐标
for i in range(k-1):
plt.plot(centroids_centres[i][0], centroids_centres[i][1], 'Dr')#mark[i], markersize = 6)
plt.show() #画出簇在图上的投影
with open(r'E:\CDA培训\CDA项目数据\葡萄牙波尔图市出租车分析\4_cluster_dest_point_10w_0.001.csv','w') as f:
writer=csv.writer(f,lineterminator='\n')
for i in centroids_centres:
writer.writerow([i[0],i[1]]) #将聚类出来的各个点输出到excel表中
cluster_dic={} #创建一个空字典
cluster=[]
for i in range(0,len_cluster):
cluster.append([df.longtitude[i],df.latitude[i]])
cluster_str=[str(i) for i in cluster] #将前面簇的经纬度结合成一个字符串,方便后面用0,1,2来进行标记
print(cluster_str)
for i in range(0, len_cluster):
cluster_dic[cluster_str[i]]=i #用0,1,2来区分各个簇的点,更加方便
print(cluster_dic)
with open(r'E:\5_labels_10w_0.001.csv','w') as f:
writer=csv.writer(f,lineterminator='\n')
for i in clf.labels_:
writer.writerow([i]) #将每个点的labels输出到excel表中







 本文通过随机抽取10万条出租车轨迹数据,使用MeanShift算法进行聚类分析,最终确定了3235个热点区域,并详细记录了整个数据处理流程。
本文通过随机抽取10万条出租车轨迹数据,使用MeanShift算法进行聚类分析,最终确定了3235个热点区域,并详细记录了整个数据处理流程。























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









