






 本文详细介绍了GPT系列(特别是GPT2和GPT3)的生成式预训练Transformer模型,包括其工作原理(embedding、attention、MLPs和unembedding),以及如何在语音识别和图像处理等AI场景中通过概率分布预测文本。着重讲述了GPT2与GPT3的神经网络参数差异和ChatGPT的工作流程。
本文详细介绍了GPT系列(特别是GPT2和GPT3)的生成式预训练Transformer模型,包括其工作原理(embedding、attention、MLPs和unembedding),以及如何在语音识别和图像处理等AI场景中通过概率分布预测文本。着重讲述了GPT2与GPT3的神经网络参数差异和ChatGPT的工作流程。
GPT:genrative pre-trained transformer(生成式预训练transfomer模型)
Transformer:一种特定类型的神经网络,一种机器学习模型
- 当前主要应用于语音识别生成、图像处理等ai场景中
- 可用来预测后续内容,主要基于概率分布形式对后续可能出现的文本片段给出概率分布
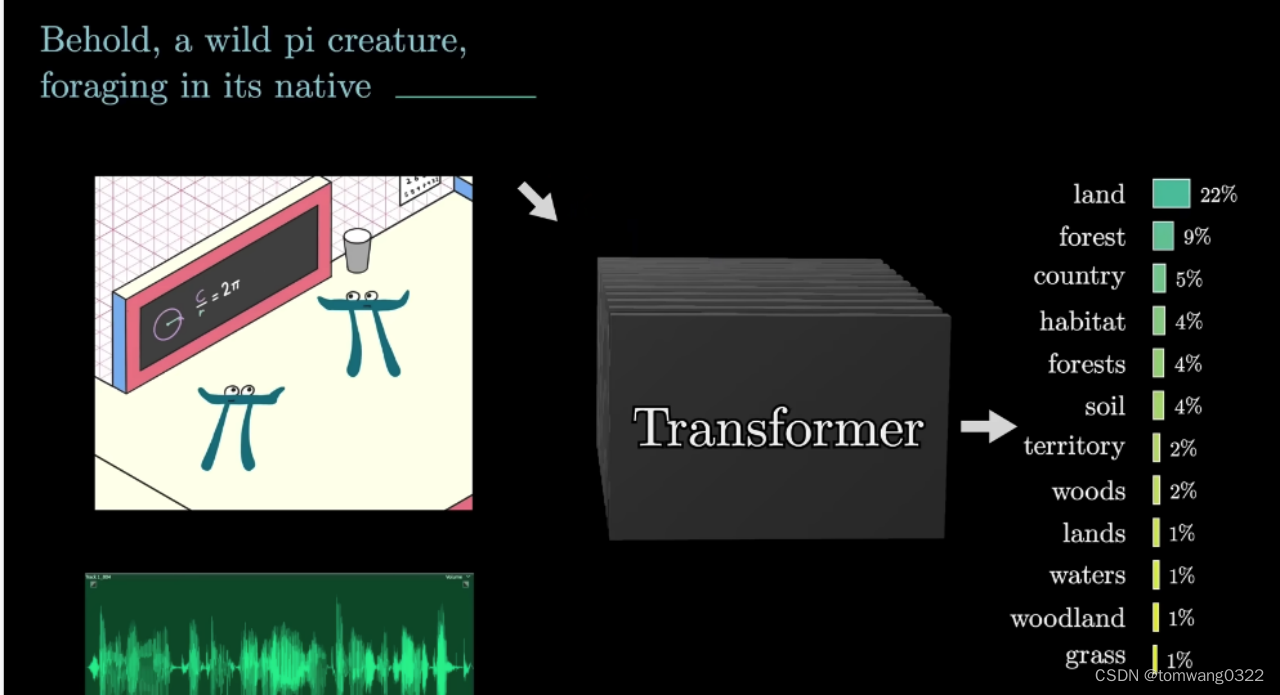
GPT2和gpt3的区别在于
1.gpt2的神经网络参数较gpt3较小
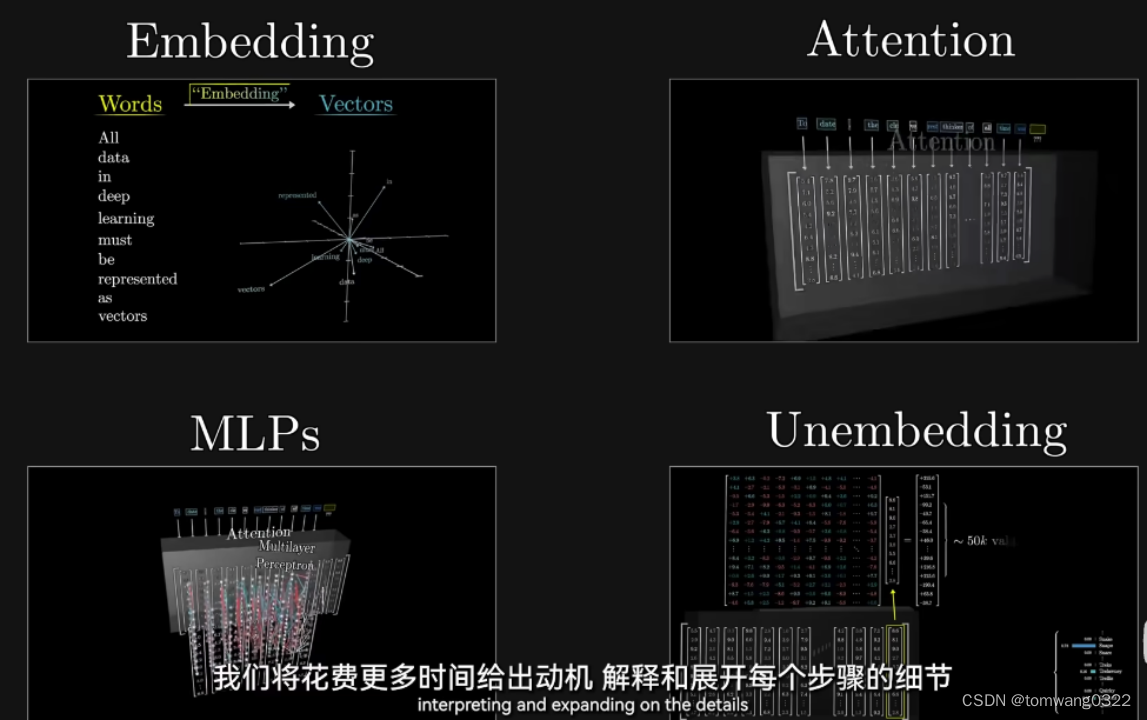
chatgpt运行流程:
embedding->attention->MLPs->unembedding
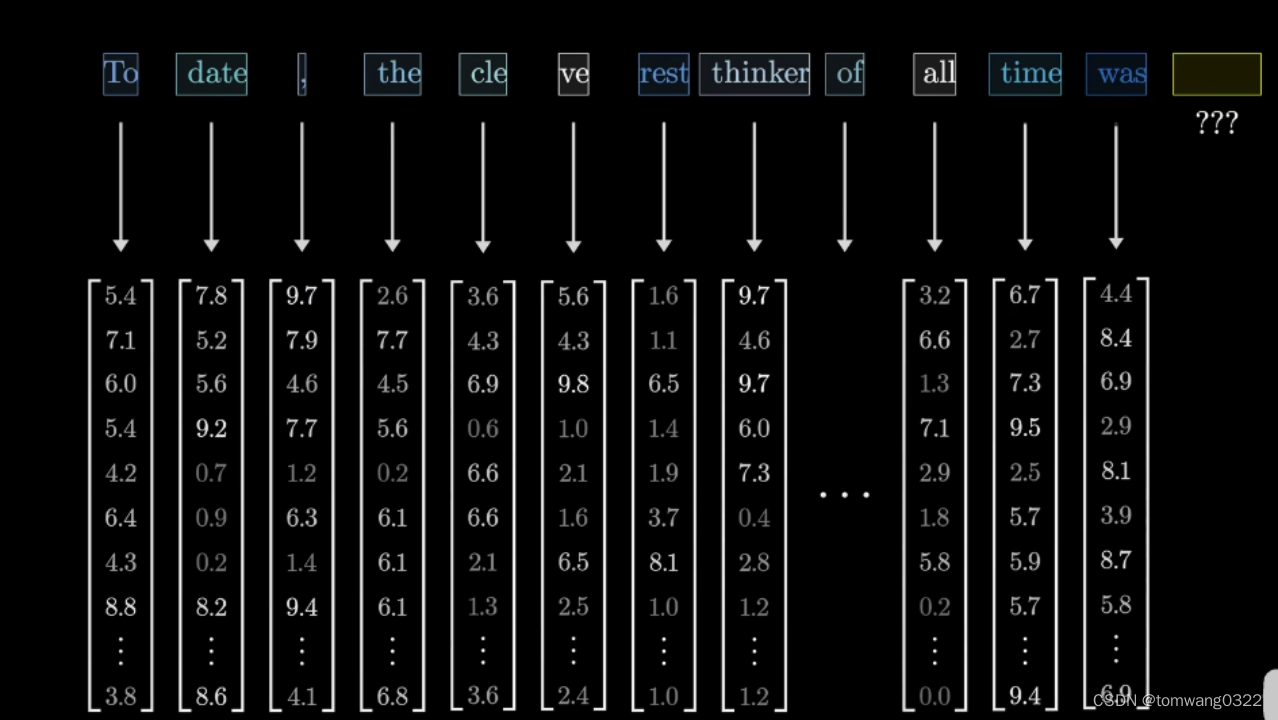
1.embedding(编码):将单词转换成对应向量的过程,就叫embedding
-
文本会被分割成不同的片段,这些片段被称作token,且每个token都会与一个向量所关联,即某些数字列表,换句话说,每个单词对应一个token,每个token又对应一个向量,共计有50257个token(或向量)组建了embedding matrix
-
-
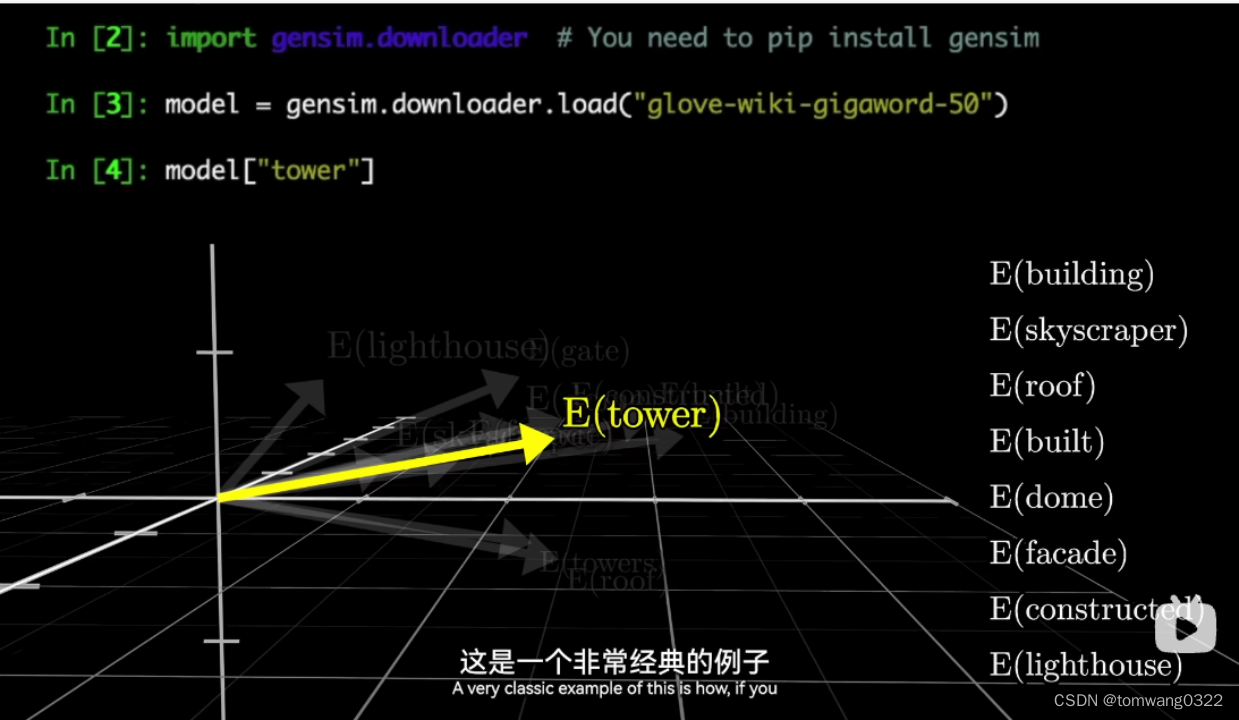
这些向量也会在高维空间中被投射,主要根据向量里的元素个数来决定维度的多少
-
通常相近的词语在投射到高维空间中的位置也是接近的
-
通过所有单词对应编写好的编码矩阵(embedding matrix),文本会从编码矩阵中按顺序转换成对应的向量
-
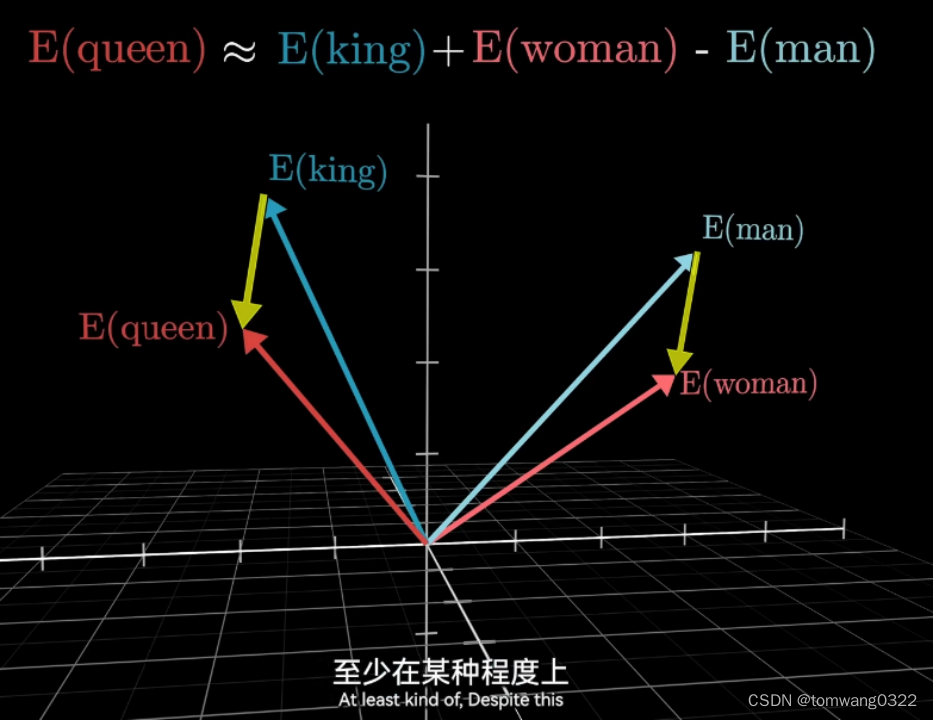
值得注意的是,某一类型正反义的向量差与近似类型正反义向量差基本一致,如国王-王后在空间中对应的向量差基本和男人与女人的向量差一致【这取决于从某一个切片的横截面或者说某一权重矩阵与该高维向量的点积计算后的结果,如v(国王)点乘某一权重矩阵 - v(王后)点乘该权重矩阵 约= v(男人)点乘该权重矩阵 - v(女人)点乘该权重矩阵 】
2.attention模块
-
将上述的编码后的文本块代入到attention模块中,使得这些向量构成的文本块能够相互交流并且传递信息及更新他们的值

-
通过这些attention模块,能够进一步明确某个单词在上下文中具体的含义,如model在fasion model和machine learning model中的含义就可以依据上下文来明确此处model所指的具体含义。
3.MLPs(多层感知器)
- 之后,经过attention模块更新后的文本块将经过多层感知器(multilayer perception)进行加工,需要注意的是,此处这些向量彼此之间将不会相互交流

4.unembedding(解码)
- 在经过不断的attention-MLPs的组合迭代后,到了最后一层会将最后一个末尾词进行概率预测,并进行解码输出
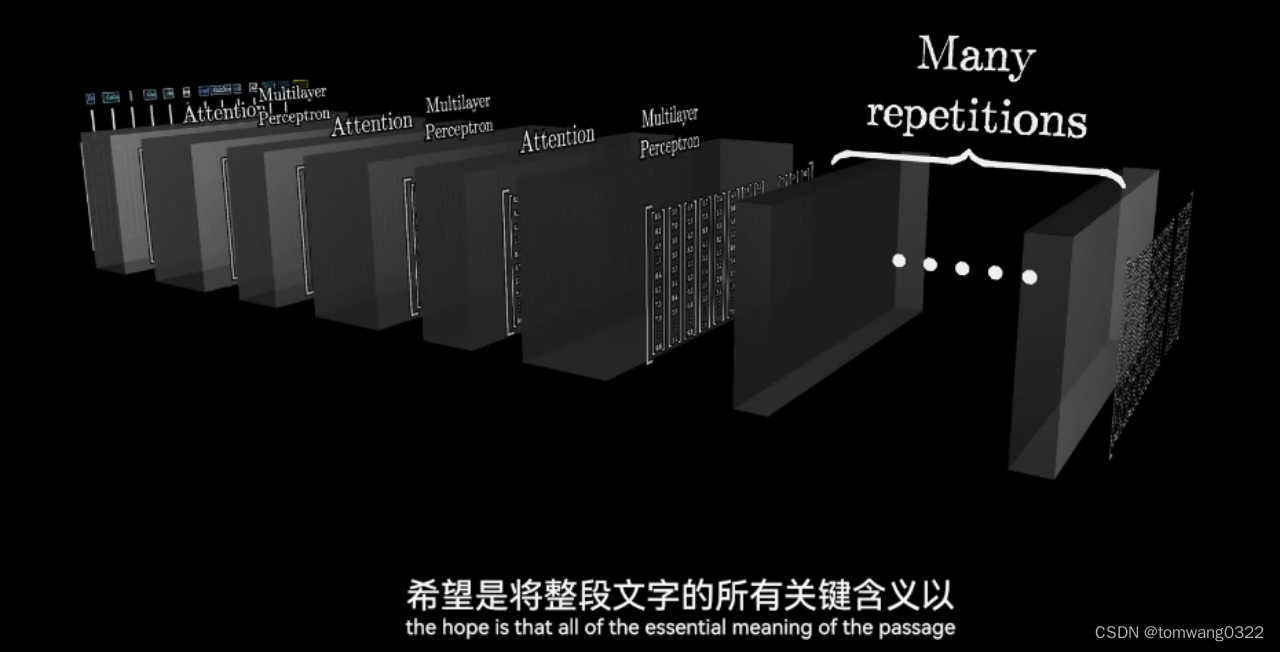
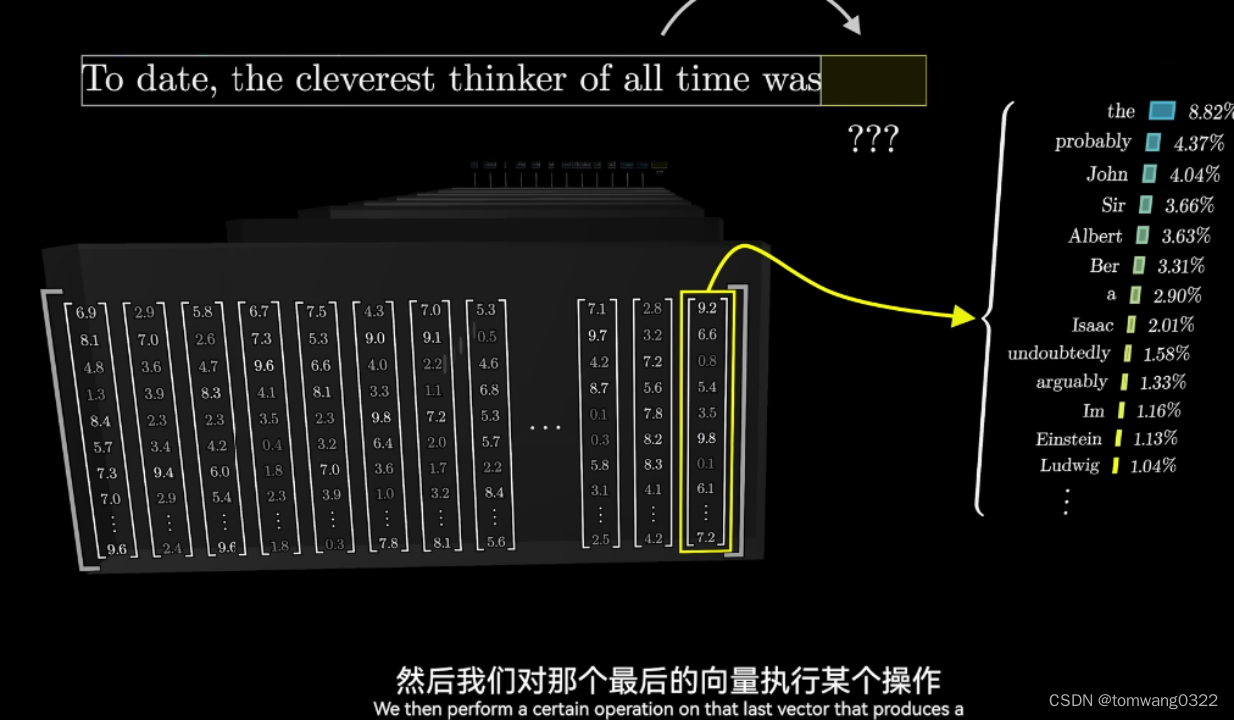
* 最后将新生成的词再返回到新的流程里,重复进行1-4的动作并生成新的词汇















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









