







安装前提:
1、在linux虚拟机中已经安装好了jdk
Linux软件安装命令,在Linux虚拟机中安装jdk
2、使用MobaXterm连接Linux虚拟机
如何用MobaXterm连接Linux虚拟机
3、在虚拟机中新建一个software文件夹,放入以下的安装包:

本篇实际上只会用到以hadoop开头的那两个安装包,但其他的安装包暂时放在那,后面都会一个一个安装的,本篇也会先简单安装。
开始安装hadoop
使用MobaXterm连接Linux虚拟机后,在software目录下,执行以下安装命令:
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/
tar -xvf hadoop-native-64-2.6.0.tar -C /opt/hadoop-2.6.0-cdh5.14.2/lib
tar -xvf hadoop-native-64-2.6.0.tar -C /opt/hadoop-2.6.0-cdh5.14.2/lib/native/
tar -zxf hbase-1.2.0-cdh5.14.2.tar.gz -C /opt/
tar -zxf hive-1.1.0-cdh5.14.2.tar.gz -C /opt/
tar -zxf zookeeper-3.4.6.tar.gz -C /opt/
执行完成后,opt目录中应该是这样的

jdk8文件夹是我jdk的安装路径,其他的都是刚刚解压安装的。
为了以后的操作方便,我们将刚刚安装的几个文件夹重新命名:

然后输入命令:vi /etc/profile 配置环境变量:
在最后一行输入:
export JAVA_HOME=/opt/jdk8
export JRE_HOME=/opt/jdk8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export HADOOP_HOME=/opt/hadoop
export HBASE_HOME=/opt/hbase
export HIVE_HOME=/opt/hive
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
以上的这些包含了jdk的环境变量的配置,如果你的jdk安装的路径跟我不一样,可以保留JAVA_HOME,JRE_HOME这两行,其他的都跟我写的一样
保存退出后执行:source /etc/profile
再输入以下这几个命令看看是否配置成功:

如上图,目前为止的配置是成功的。
配置Hadoop
首先,我们输入命令:
hostnamectl set-hostname hadoop01 修改主机名为hadoop01
然后输入命令:cd /opt/hadoop/etc/hadoop 进入文件夹
可以看到这些文件:

用红色框出来的是我们接下来要进行配置的文件:
vi hadoop-env.sh
(这里只需要改这一行,即jdk的安装路径)
vi core-site.xml

vi hdfs-site.xml

我们把mapred-site.xml.template改名为mapred-site.xml:
mv mapred-site.xml.template mapred-site.xml
然后:
vi mapred-site.xml

vi yarn-site.xml
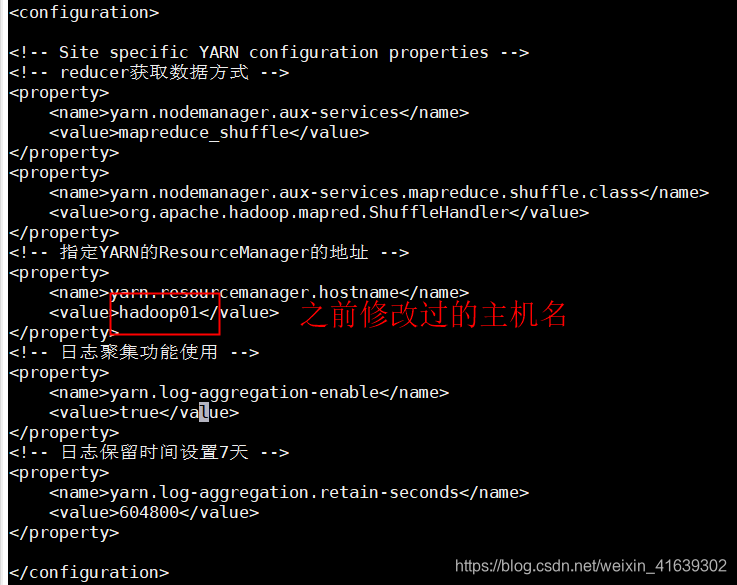
vi slaves

到此为止,hadoop的文件算是配置完成
然后我们:
vi /etc/hosts

然后执行以下两个命令:
ssh-keygen -t rsa -P “”
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
这两个命令是为了产生密钥,并让虚拟机信任密钥
输入命令:
hadoop namenode -format 格式化namenode
输入命令:
start-all.sh 启动hadoop所有节点
输入命令:
jps
应该出现:

jps后出现红框中的6行,就说明在一台虚拟机上安装hadoop成功。
输入命令:
stop-all.sh 关闭所有节点
搭建hadoop集群
上面的虚拟机安装hadoop成功后,关闭虚拟机,复制此虚拟机两次,每次复制时都要重新生成所有网卡的MAC地址,这样我们就用复制出来的两台加原来的一台搭建一个hadoop集群。
复制完成后,修改复制出来的两台虚拟机的IP地址:
192.168.21.112
192.168.21.113
(重新启动network服务后生效)
同时启动三台虚拟机,都用MobaXterm连接
修改复制后的两台主机的主机名:
第二台:hostnamectl set-hostname hadoop02
第三台:hostnamectl set-hostname hadoop03
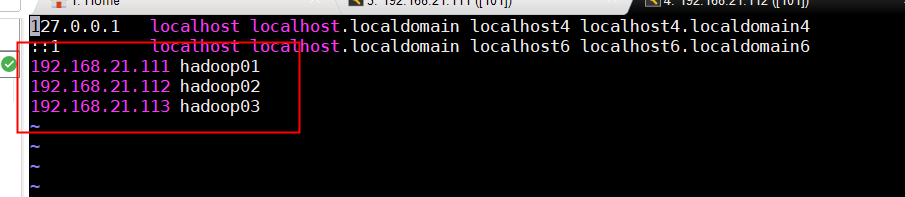
在三台虚拟机中都修改hosts:
vi /etc/hosts
改成如下图所示:
在三台虚拟机中都重新执行以下两个命令:
ssh-keygen -t rsa -P “”
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
到此为止,我们已经建成了三个linux虚拟机,主机名分别为:
hadoop01,hadoop02,hadoop03
IP地址分别为:
192.168.21.111
192.168.21.112
192.168.21.113
现在,我们要实现这三台虚拟机之间的免密连接。
在hadoop01上执行两个命令:
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.112
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.113
在hadoop02上执行两个命令:
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.111
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.113
在hadoop03上执行两个命令:
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.111
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.21.112
要求在任何一台虚拟机上使用"ssh root@[主机名或IP地址]" 连接另外两台时都不用输入密码

以下是三台虚拟机都需要的操作:

然后,在hadoop01中修改hdfs-site.xml和slaves
vi /opt/hadoop/etc/hadoop/hdfs-site.xml

vi /opt/hadoop/etc/hadoop/slaves
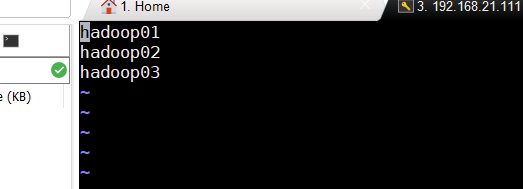
这里的hadoop01作为主节点,可以不加。
然后使用scp命令把改好的hdfs-site.xml和slaves传到hadoop02和hadoop03上

到此为止,hadoop集群算是建成了。
下面在hadoop01中
输入命令:
hadoop namenode -format 重新格式化namenode
start-all.sh
启动完成后分别在三台虚拟机中执行jps命令:
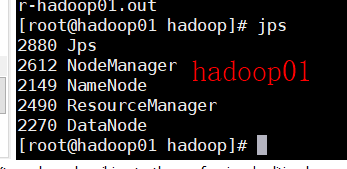
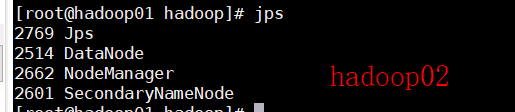

三台虚拟机如上图所示即成功搭建hadoop集群。















 6547
6547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









