









Prompt-Tuning 是近年来自然语言处理(NLP)领域的核心技术之一,其通过设计提示词(Prompt),让预训练模型(如 GPT、BERT)更加高效地适配下游任务,逐渐替代传统的 Fine-Tuning 方法,成为参数高效微调的解决方案。本文将以案例结合技术发展历程,带你深度解析 Prompt-Tuning 的核心思想与演进过程。
下面是一个传统的任务微调的Fine-Tuning(微调)过程:
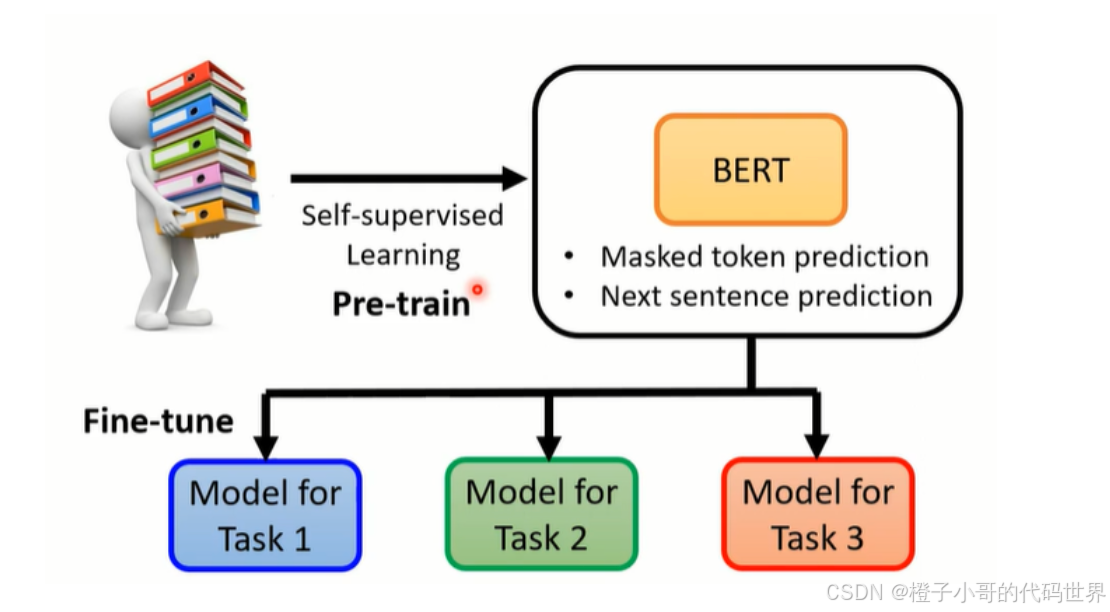
Prompt-Tuning(提示词微调)主要解决传统Fine-Tuning(微调)方式的两个痛点:
- 降低语义偏差:预训练任务主要以MLM(Masked Language Model,即“掩码语言模型”)为主,而下游任务则重新引入新的训练参数,因此两个阶段目标差异较大。因此需要解决Pre-Training(预训练)和Fine-Tuning(微调)之间的Gap(差异)。
- 避免过拟合:由于Fine-Tuning(微调)阶段需要引入新的参数适配相应任务,因此在样本数量有限的情况下容易发生过拟合,降低模型泛化能力。因此需要解决预训练模型的过拟合能力。
一、什么是 Prompt-Tuning(提示词微调)?
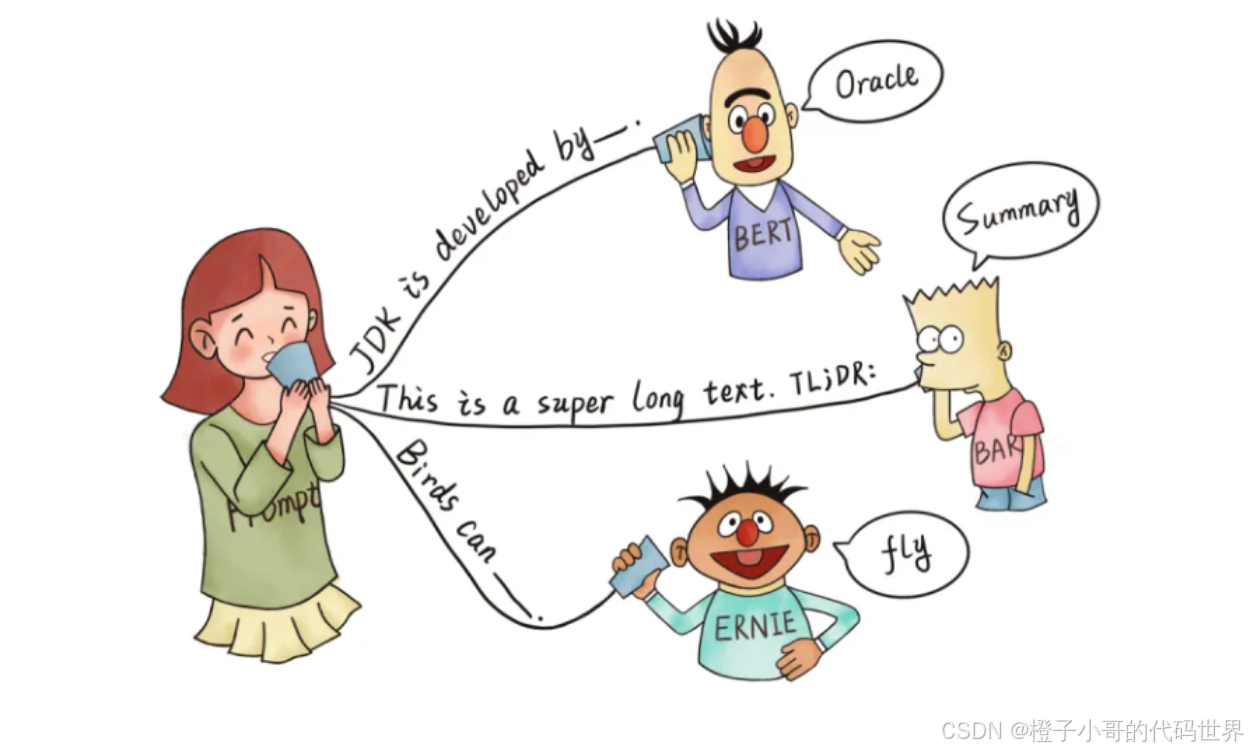
Prompt-Tuning(提示词微调)是一种通过提示(Prompt)与模型交互的技术,其核心在于将下游任务转化为预训练任务(如掩码语言建模 Masked Language Modeling, MLM)。根据提示的表达形式,可分为两类:
1. 离散模板(Discrete Prompt / Hard Prompt)
• 定义: 通过人为设计的固定文本模板,通过语言形式直接表达任务意图,将下游任务转化为预训练任务(如 Masked Language Modeling, MLM)。
• 特点:
• 简单直观,适合小规模任务。
• 强依赖领域知识,扩展性差。
• 离散模板(Discrete Template):用离散 Prompt 构造的规则框架,将任务格式化。
• 案例:情感分类任务
• 任务:电影评论情感分类
• 输入:我很喜欢迪士尼的电影。
• 模板:这部电影真是[MASK]。
• 拼接后:我很喜欢迪士尼的电影。这部电影真是[MASK]。
• 输出:如果 [MASK] 预测为 棒极了,则是正向情感;如果预测为 糟透了,则是负向情感。
2. 连续提示(Continuous Prompt)
目前基于连续提示的Prompt-Tuning的实现方法,以下列三篇论文为代表,分别作简要介绍:
- 《The Power of Scale for Parameter-Efficient Prompt Tuning》:代表方法为Prompt Tuning
- 《GPT Understands, Too》:代表方法为P-tuning
- 《PPT: Pre-trained Prompt Tuning for Few-shot Learning》:代表方法PPT
• 定义: 用可训练的连续向量表示任务提示(Prompt),将其嵌入到输入数据中,通过优化向量来适配任务。
• 特点:
- • 自动化程度高,减少人工干预。
- • 更适合大规模复杂任务。
案例:情感分类任务
• 输入句子: “我喜欢这部电影。”
• 拼接: [可训练的连续Prompt 向量] + 我喜欢这部电影。 + [MASK]
• 模型预测: [MASK] = “棒极了” → 分类结果为“正向”。
二、Prompt-Tuning 的技术发展历程
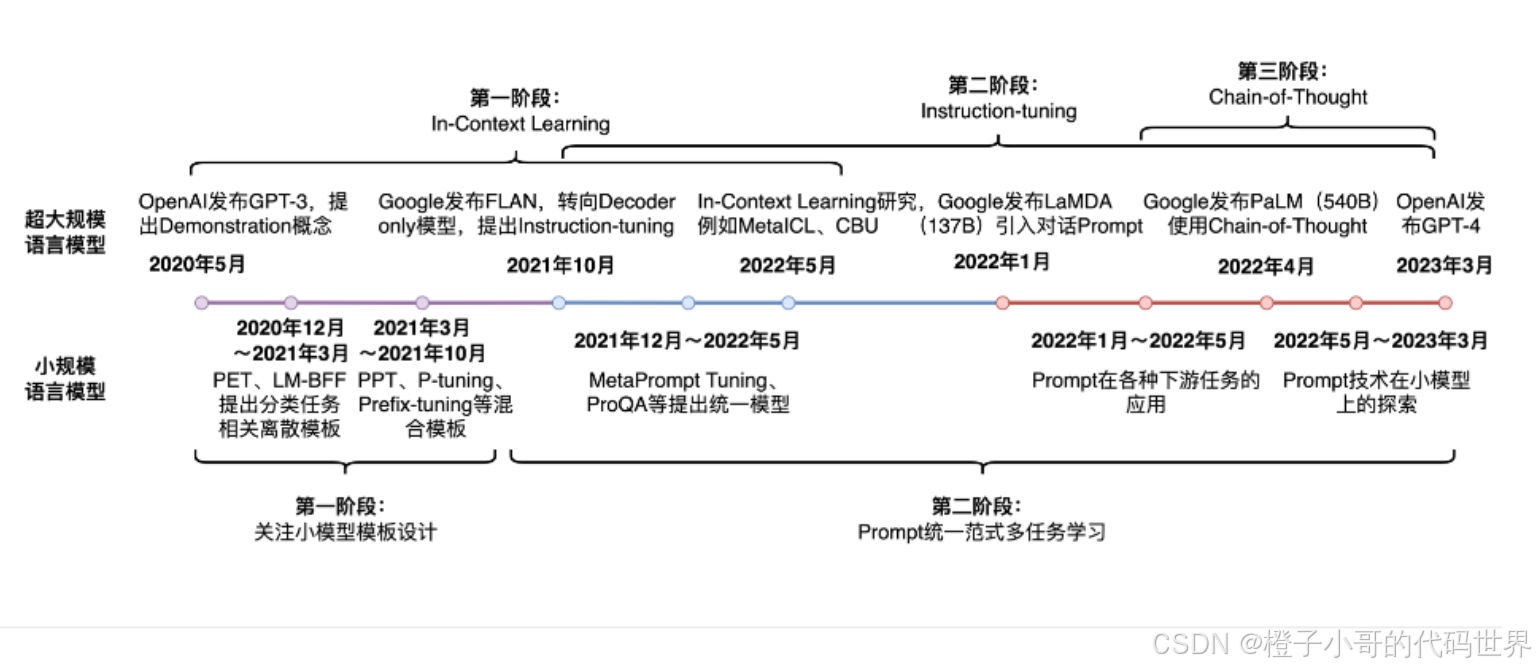
Prompt-Tuning自GPT-3被提出以来,从传统的离散、连续的Prompt构建、走向面向超大规模模型的In-Context Learning、Instruction-tuning和Chain_of_Thought.。以下是其发展历程的四个主要阶段:
第一阶段:In-Context Learning(上下文学习)
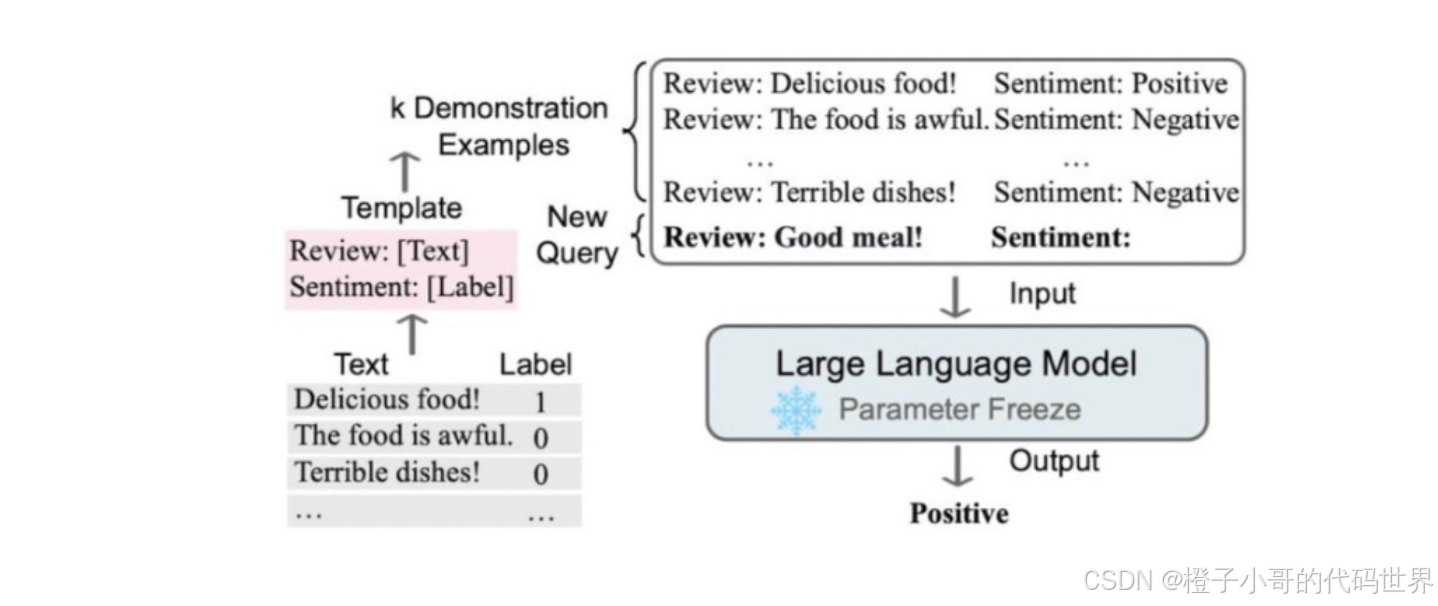
• 时间: 2020 年 5 月
• 背景: OpenAI 发布 GPT-3,提出 In-Context Learning(上下文学习) 概念。让模型通过上下文示例推断任务结果,无需修改模型参数。
• 核心技术:
• 示例学习(Demonstration Learning): 通过在输入中加入 <输入, 输出> 示例对,让模型“学习”如何完成任务。
案例:翻译任务:将中文翻译为法语。
• 输入:
示例:你好 -> Bonjour
示例:再见 -> Au revoir
示例:苹果 ->
• 输出: Pomme
• 特点:
- • 无需微调参数,直接基于上下文预测。
- • 适合大规模模型,但对小模型效果有限。
优缺点:
• 优点:无需训练即可处理任务,尤其适合超大规模模型(如 GPT-3)。
• 缺点:
- • 依赖大模型:小规模模型无法充分利用上下文示例。
- • Prompt 设计简单:泛化能力有限,难以适配多样化任务。
第二阶段:离散模板设计与分类任务应用
• 时间: 2020 年 12 月 - 2022 年 5 月
技术目标:通过设计离散 Prompt 和模板,将下游任务转化为模型擅长的完形填空任务。
• 技术亮点:
1. PET(模式利用训练,Pattern Exploiting Training)
PET(Pattern-Exploiting Training)出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021),根据论文题目则可以猜出,Prompt-Tuning启发于文本分类任务,并且试图将所有的分类任务转换为与MLM一致的完形填空。
• 概念: 将分类任务转化为完形填空任务,使用离散模板和标签词映射进行分类。
• 案例:
• 输入: “这部电影让我感到 [MASK]。”
• 模型预测: [MASK] = “棒极了” → 分类结果为“正向”。
PET模型提出两个很重要的组件:
- Pattern(Template) :记作T, 即上文提到的Template,其为额外添加的带有
[mask]标记的短文本,通常一个样本只有一个Pattern(因为我们希望只有1个让模型预测的[mask]标记)。由于不同的任务、不同的样本可能会有其更加合适的pattern,因此如何构建合适的pattern是Prompt-Tuning的研究点之一; - Verbalizer :记作V, 即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。例如情感分析中,我们期望Verbalizer可能是 (positive和negative是类标签)。同样,不同的任务有其相应的label word,但需要注意的是,Verbalizer的构建需要取决于对应的Pattern。因此 如何构建Verbalizer是另一个研究挑战 。
下面是常见下游任务的Prompt设计:

2. LM-BFF(语言模型与数据增强,Language Model with Best Friend Forever)
概念:
LM-BFF 是一种结合数据增强与离散模板的方法,通过构建多样化的数据样本,优化模型在少样本场景下的分类任务性能。
关键点:
• 数据增强: 通过随机替换或扩展句子,增加数据多样性。或者使用不同的句式和表达方式生成更多训练数据,使模型更具鲁棒性。
• 离散模板: 构建任务相关的固定模板,将输入数据转换为预训练任务格式。
案例:情感分类任务
1. 原始数据输入:
训练数据中只有少量评论,例如:
- • “这部电影很好看。”
- • “我讨厌这个角色。”
2. 数据增强:
使用同义词替换、句式扩展等方式生成更多样本,例如:
- • 原始输入:这部电影很好看。
- • 扩展数据:
- • 这部电影真的不错。
- • 我觉得这部电影非常棒,推荐给大家!
- • 这部电影超出了我的期待,很喜欢。
3. 离散模板转换:
将增强后的数据转换为固定的离散模板,构造成类似完形填空任务:
- • 模板:这部电影让我感到 [MASK]。
- • 输入示例:
- • 这部电影让我感到 [MASK]。
- • 扩展后的输入:
- • 这部电影真的让我感到 [MASK]。
- • 我觉得这部电影实在是 [MASK]。
4. 模型输出:
基于 BERT 的 Masked Language Model (MLM),模型会预测 [MASK] 的值:
- • 对于“这部电影让我感到 [MASK]”,可能的输出为:
- • “开心” → 分类为“正向”。
- • “无聊” → 分类为“负向”。
- • 对于“我觉得这部电影实在是 [MASK]”,可能的输出为:
- • “优秀” → 分类为“正向”。
- • “糟糕” → 分类为“负向”。
完整流程对比
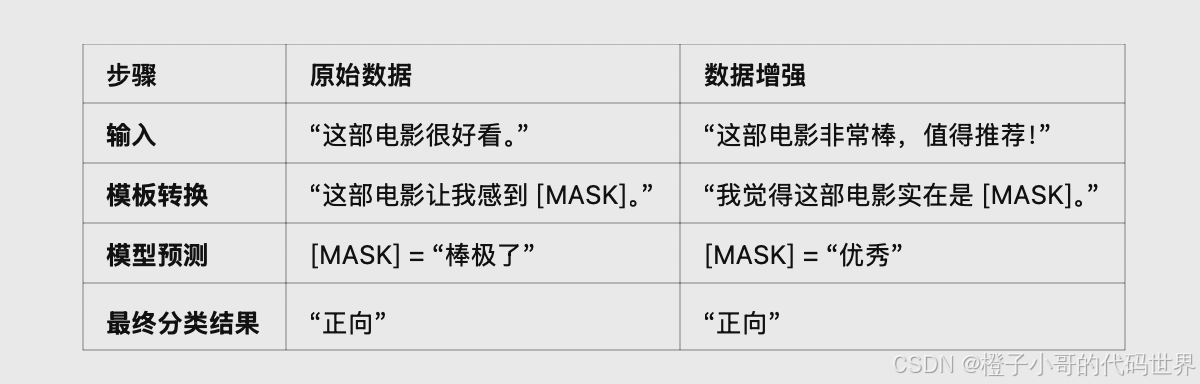
补充说明:
• 数据增强的意义:
- 通过生成多样化的数据,弥补少样本场景下数据不足的问题。
• 离散模板的作用:
- 通过固定模板将任务结构化,使模型能够直接复用预训练任务(如 MLM)的能力,提升预测准确性。
• 输出案例的对比:
- 随机扩展后的句式提供更多上下文信息,使模型更容易预测 [MASK] 的值,从而优化分类性能。
3. Prefix-Tuning(前缀微调)
• 概念: 在输入前加入一段可训练的连续向量(称为前缀向量Prefix),通过优化前缀参数来适配任务。
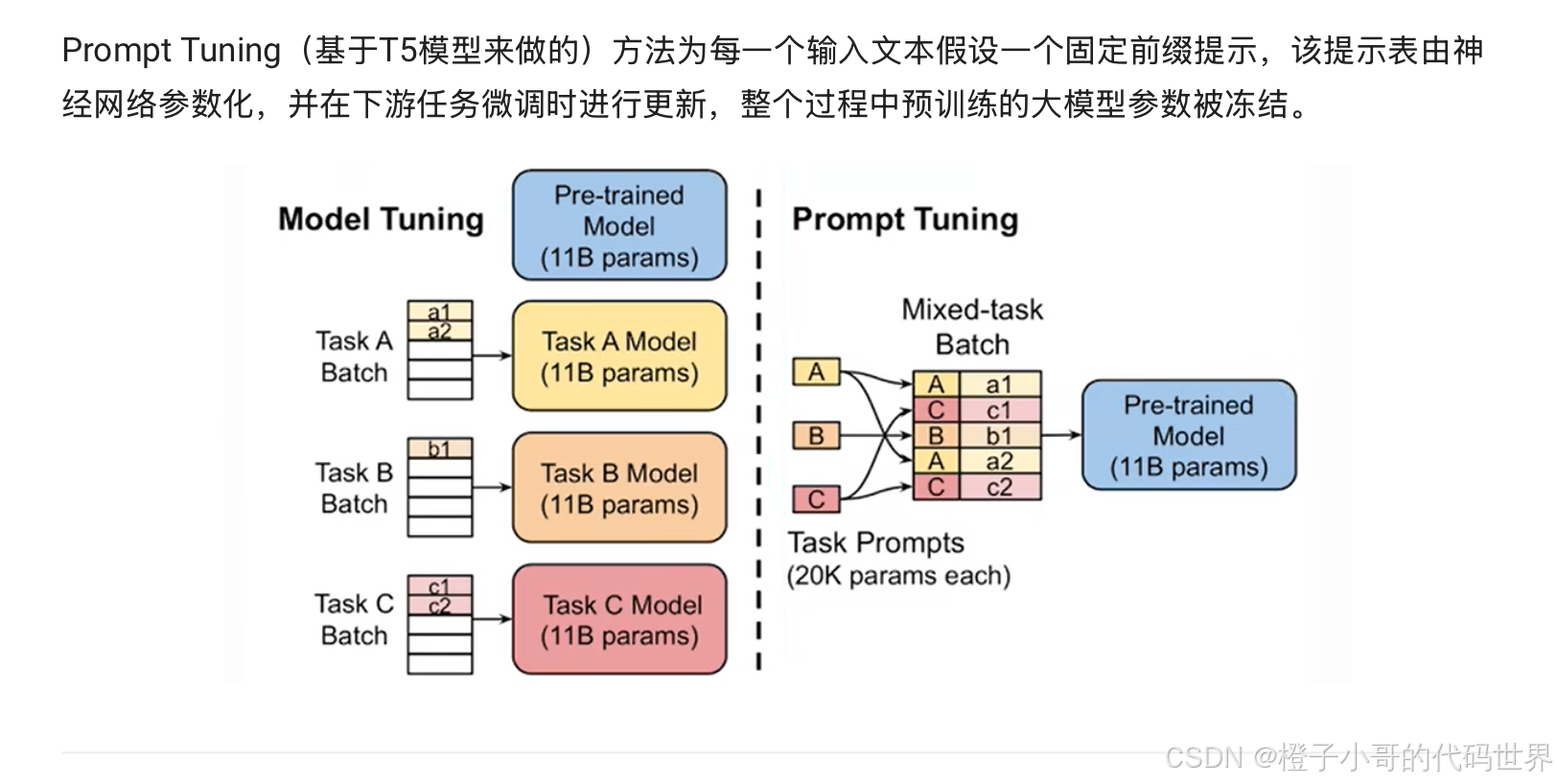
• 工作原理:
• 输入由 前缀向量 + 原始输入数据 拼接。
• 前缀向量在模型的每一层中参与计算,通过训练优化这些参数,而模型其他部分参数保持冻结。
Prefix-Tuning 的本质:
- 前缀是连续向量,表示任务意图,通过训练优化这些向量实现任务适配。
- 什么是前缀向量? 使用类比来说明,比如“就像给模型一个指令清单,让它知道输入的文本方向”。
-
前缀向量类比 :导航中的“路线指示”
假设你使用 GPS 导航从 A 点到 B 点,前缀向量就像导航的起始指令,比如:
• “向东行驶 500 米。”
• “在第一个路口右转。”
这些指令虽然不是最终的路线,却影响了你后续的选择。同样,前缀向量虽然不直接提供任务的答案,但它们为模型计算提供了明确的方
• 案例:表格转文本
输入:
• 前缀: 摘要:[咖啡店简介]
• 表格: 名称:星巴克;类型:咖啡店;位置:上海
• 输出: 星巴克是一家位于上海的著名咖啡店。
问题:Prefix-Tuning(前缀微调)中的“前缀”是向量还是人类输入的摘要?
• 核心解释:
• 在 Prefix-Tuning 中,前缀实际上是连续向量,而不是人类可读的自然语言文本。你看到的例子中的“摘要:[咖啡店简介]”只是为了便于理解的描述,并不是模型直接使用的。
• 实际中,“摘要:[咖啡店简介]”这样的语义信息会被嵌入为一组可训练的连续向量(虚拟 token),通过优化这些向量,模型可以理解任务需求并生成目标输出。
• 技术细节:
• 输入拼接:前缀向量是固定长度的连续向量,与原始输入数据(如“名称:星巴克;类型:咖啡店;位置:上海”)拼接。
• 训练:
• 前缀向量初始化为随机值。
• 在训练过程中,优化这些向量,让它们逐渐学会如何引导模型完成任务。
• 推理阶段:
• 优化后的前缀向量会作为模型输入的一部分,不需要人工干预。
• 总结:
• 所谓“摘要:[咖啡店简介]”的文本部分只是为了说明任务意图。实际中,这部分语义是通过连续向量形式输入模型,并非人类手动输入。
4. P-Tuning(连续提示微调)
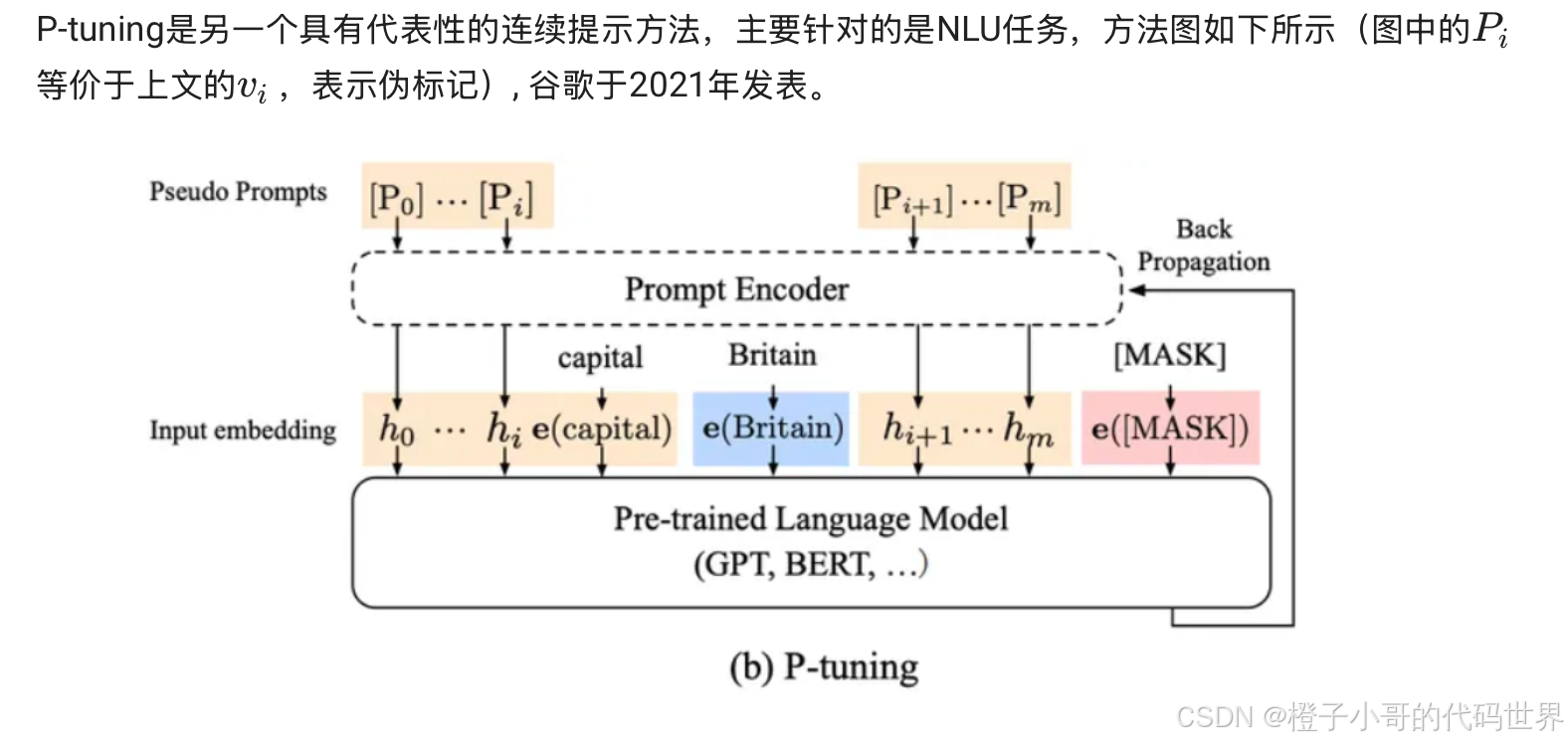
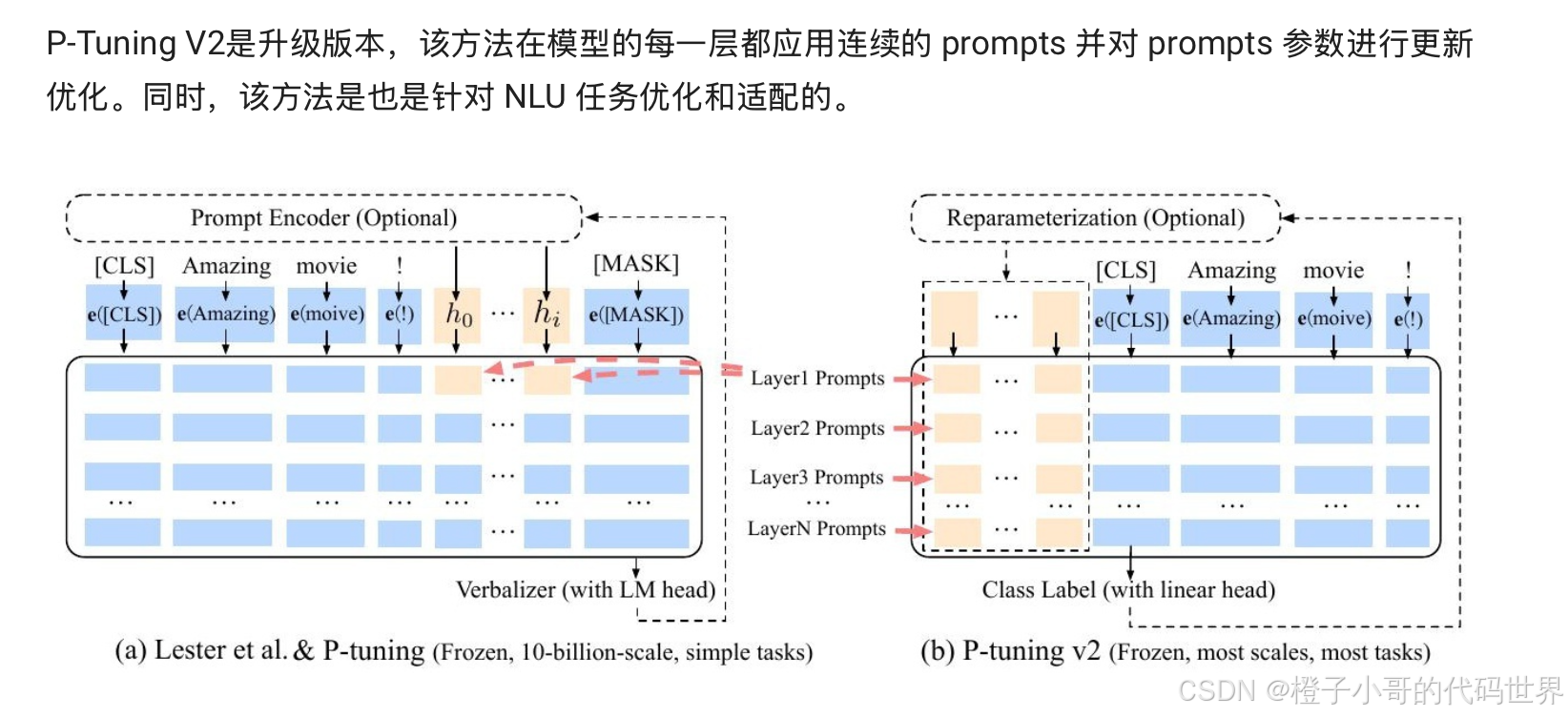
• 概念: 用连续向量代替人工离散模板,优化 Prompt 参数。并结合 Bi-LSTM 提升训练稳定性。
• 案例:情感分类
• 输入: “我喜欢这个电影。”
• 拼接: [Prompt 提示向量] + 我喜欢这个电影。 + [MASK]
• 模型预测: [MASK] = “棒极了” → 分类结果为“正向”。
第三阶段:Prompt 统一范式与多任务学习
• 时间: 2021 年 12 月 - 2022 年 5 月
• 核心技术:
1. MetaPrompt-Tuning(元提示微调)
• 概念:提出一个通用的 Prompt 模板,让不同任务共享同一套 Prompt。通过统一模板实现多任务共享,减少了人工设计成本。
• 案例:同一 Prompt 模板适配问答、分类和翻译任务。
• 模板: 任务:[描述任务目标] 输入:[任务输入] 输出:[任务输出]
• 问答任务:
- • 输入:“任务:回答问题 输入:地球的直径是多少? 输出:?”
- • 输出:“12,742 公里。”
• 情感分类任务:
- • 输入:“任务:判断评论的情感 输入:我喜欢这部电影。 输出:?”
• 输出:“正向。”
问题:MetaPrompt-Tuning(元提示微调)中的通用模板中 为什么同一个 Prompt 模板可以适配多个任务?
• 核心解释:
• 元提示(MetaPrompt)是一种通用的任务描述方式,将任务目标用自然语言明确表达,使不同任务在某种程度上共享相似的目标表达。
• 为什么通用模板可行?
• 自然语言描述的泛化能力:例如,“根据上下文回答问题”和“根据文本生成摘要”都可以通过自然语言描述转化为类似的结构化任务。
• 预训练模型的能力:大规模预训练模型(如 BERT、GPT)已经通过预训练掌握了丰富的知识。通过一个精心设计的 Prompt,它们可以调动模型中已有的知识来适配不同任务。
所以回到上面的案例,他就可以根据我们的额模版来实现不同任务的。
• 案例:
• 模板:“任务:[描述任务目标] 输入:[任务输入] 输出:[任务输出]”
• 问答任务:
• 输入:“任务:回答问题 输入:地球的直径是多少? 输出:?”
• 输出:“12,742公里。”
• 文本分类任务:
• 输入:“任务:判断评论的情感 输入:这部电影真是太棒了! 输出:?”
• 输出:“正向。”
• 翻译任务:
• 输入:“任务:将中文翻译成法语 输入:我喜欢学习。 输出:?”
• 输出:“J’aime apprendre.”
• 总结:
• MetaPrompt 通过通用的语言描述让任务共享同一个 Prompt 框架。大模型通过训练已经掌握了这类描述,能有效适配不同任务。
2. Instruction-Tuning(指令微调)
• 概念: 通过自然语言指令描述任务目标,减少 Prompt 的设计复杂性。
• 案例:翻译任务
• 输入:请将这句话翻译成法语:我喜欢编程。
• 输出:J'aime la programmation.
第四阶段:Chain-of-Thought(思维链)
• 时间: 2022 年 4 月 - 2023 年 3 月
• 概念:通过加入推理步骤解决复杂任务。通过分步推理让模型更好地处理复杂任务,尤其是逻辑推理问题。
• 核心技术:
• Few-shot CoT: 提供人工标注的推理步骤示例,通过示例演示推理过程,让模型模仿生成答案。
• Zero-shot CoT: 使用提示引导模型自主生成推理步骤,比如“让我们一步步思考”提示,模型自主生成推理步骤。
案例:数学推理
• 输入: 如果有 3 个苹果,拿走了 2 个,还剩几个?
• 提示: 让我们一步步思考。
• 推理过程:
• 第一步:有 3 个苹果。
• 第二步:拿走了 2 个。
• 第三步:剩下 1 个。
• 输出: 1
问题: 思维链(Chain-of-Thought,CoT)中的推理过程中的步骤是人类手写的还是模型自己推导的?
• 核心解释:
- • 思维链提示(CoT Prompt)可以是人类手写的,也可以是模型自己推导的,具体情况取决于任务场景和模型的规模。
• 两种实现方式:
1. Few-shot CoT(人类手写示例):
• 人类提供带有中间推理步骤的示例,作为模型学习的参考。
• 示例:
• 任务:数学推理
• 输入:如果有 3 个苹果,拿走了 2 个,还剩几个?
• 提示:我们一步步思考:
- 1. 起初有 3 个苹果。
- 2. 拿走了 2 个。
- 3. 剩下 3 - 2 = 1 个。
• 输出:1
• 解释:这种方法提供清晰的逻辑步骤,让模型模仿并生成类似的推理。
2. Zero-shot CoT(模型自己生成):
• 使用提示语句引导模型生成中间推理步骤。
• 示例:
• 输入:如果有 3 个苹果,拿走了 2 个,还剩几个?
• 提示:让我们一步步思考。
• 模型生成:
- 1. 有 3 个苹果。
- 2. 拿走了 2 个。
- 3. 剩下 1 个。
• 输出:1
• 解释:这种方法依赖模型的逻辑推理能力,在规模足够大的模型(如 GPT-4)中表现良好。
• CoT 提示为什么重要?
- • 传统模型难以直接从输入生成复杂任务的答案。
- • CoT 提示通过分步推理,让模型更易于处理逻辑复杂的任务。
• 总结:
- • 对于小模型,人类需要提供推理步骤示例。
- • 对于大模型,只需简单提示,模型即可生成中间推理步骤并得出答案。
三、总结与展望
总结:
- Prompt-Tuning 从离散模板到连续提示,再到思维链的引入,技术不断进化,不断提升了 NLP 模型的任务适配能力。它通过高效的参数优化和任务适配,为 NLP 模型开辟了新方向。
未来的发展方向包括:
- 1. 多模态扩展: 从文本任务扩展到图像、视频等多模态场景。
- 2. 自动化 Prompt 设计: 减少人工干预,提高 Prompt 生成效率。
- 3. 复杂任务适配: 更好地处理逻辑推理、多步骤生成等复杂任务。
通过这篇文章,你应该了解了 Prompt-Tuning 的发展脉络,可以肯定的是Prompt-Tuning 的未来无疑将进一步推动 NLP 技术的高效落地!
期待 Prompt-Tuning 在更多领域中释放潜力,为复杂任务提供更优雅的解决方案!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









