










Prompt Tuning 和 P-Tuning 都属于“软提示”(soft prompt)范式,但 P-Tuning 首次提出用小型 LSTM/MLP 对提示嵌入进行编码生成,而 Prompt Tuning(又称 Soft Prompt Tuning)则直接对一段可训练的嵌入序列做梯度更新;LoRA(Low-Rank Adaptation)通过在 Transformer 层注入两段低秩矩阵分解,仅训练这部分额外参数实现参数效率微调;QLoRA 则在 4-bit 量化权重上应用 LoRA,几乎与原始 16-bit LoRA 性能持平,却将显存占用降低近 3 倍。以下内容将依次覆盖各方法的原理细节、训练流程差异,以及在 BERT 分类任务中完整的训练、保存、加载与推理伪代码示例。
1 Prompt Tuning vs P-Tuning
1.1 方法定义与原理
-
Prompt Tuning:在模型输入的 embedding 层前添加 L 个可训练向量,称为软提示(soft prompts),并仅对这 L 参数进行梯度更新,冻结其余预训练模型参数 。
-
P-Tuning:《GPT Understands, Too》中提出,除使用离散提示外,还通过一个小型 LSTM 或 MLP(prompt encoder)对初始提示嵌入做变换,生成最终的连续提示嵌入,再拼接到输入前进行训练,提示参数由反向传播更新 。
1.2 训练流程对比
| 阶段 | Prompt Tuning | P-Tuning |
|---|---|---|
| 初始化 | 随机或预训练初始化 L 个提示向量 | 同上 + 初始化 LSTM/MLP 权重 |
| 前向传递 | 拼接提示向量 + 原始 embeddings → Encoder | 先 LSTM/MLP 生成提示嵌入,再拼接 + 原始 embeddings → Encoder |
| 反向更新 | 仅更新提示向量 | 更新提示向量与 prompt encoder 参数 |
| 数据存储 | 保存提示向量矩阵 | 同上 + 保存 encoder 权重 |
1.3 保存与加载伪代码
# 保存
torch.save(prompt_embeddings.state_dict(), "prompt_tuning_prompts.bin")
# 加载
prompt_embeddings = nn.Parameter(torch.zeros(L, hidden_size))
prompt_embeddings.load_state_dict(torch.load("prompt_tuning_prompts.bin"))# P-Tuning 保存
torch.save({
"prompt_encoder": lstm.state_dict(),
"prompt_vectors": prompt_embeddings_init
}, "p_tuning_prompt.bin")
# 加载
ckpt = torch.load("p_tuning_prompt.bin")
lstm.load_state_dict(ckpt["prompt_encoder"])
prompt_embeddings_init = ckpt["prompt_vectors"]2 LoRA vs QLoRA
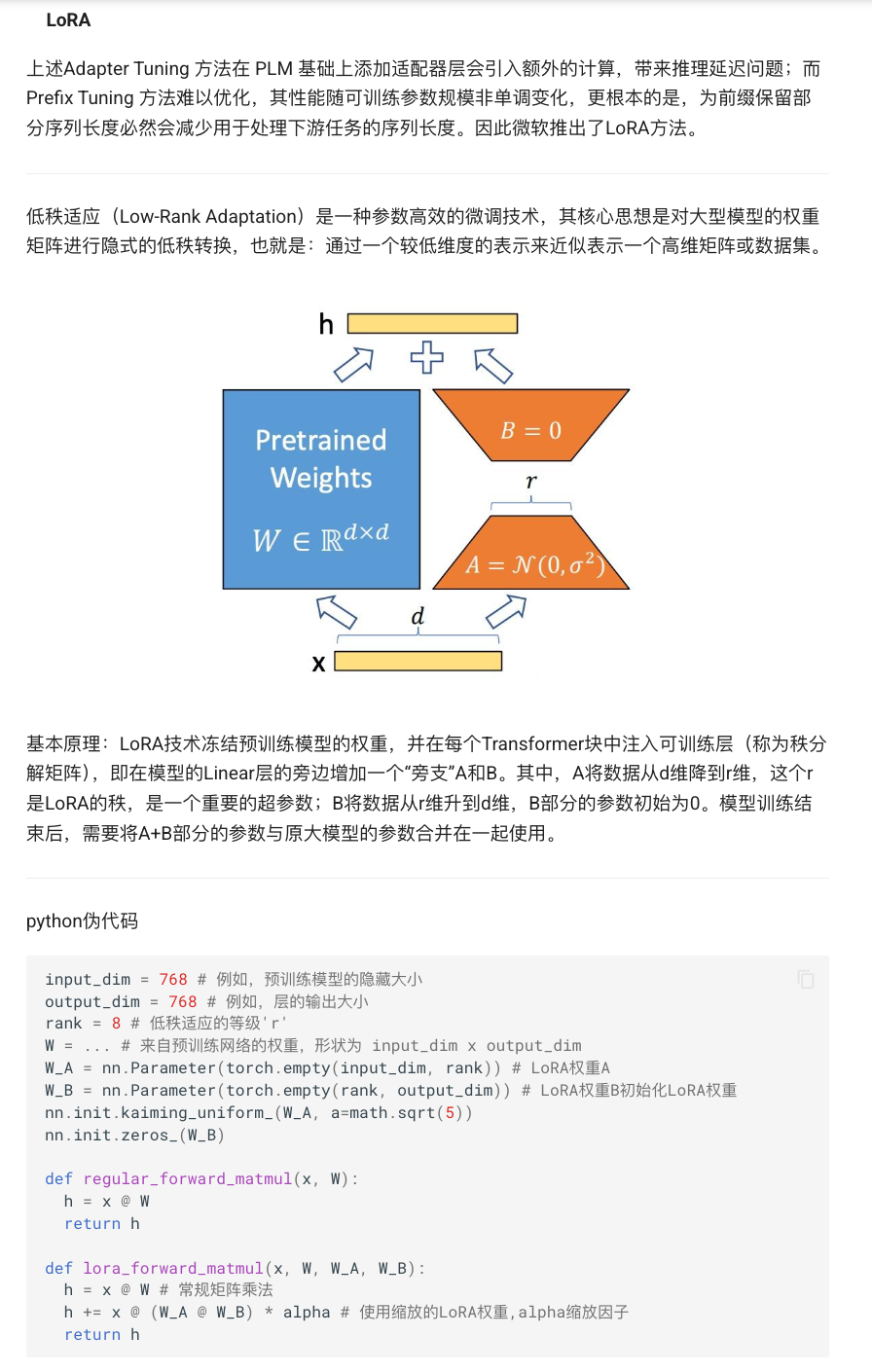
2.1 LoRA(Low-Rank Adaptation)原理
LoRA 在每个 Transformer 层的线性映射 xW 的旁支引入低秩分解 与
,并用
替代原始变换,其中
为缩放系数,可训练参数量仅为 2dr,相比全量微调可减少约 10,000 倍参数 。
2.2 QLoRA 原理
QLoRA 首先将原模型权重量化到 4-bit(如 NF4),显存占用大幅下降;然后在量化权重上按常规方式注入 LoRA 分支,并只训练 LoRA 分支参数。该过程兼顾了量化与低秩适配的双重优势,实验证明与 16-bit LoRA 性能相当,却将显存占用降至三分之一左右 。
2.3 训练与保存伪代码
# LoRA 注入示例(略)后,仅启用 A,B 子模块
for name,p in model.named_parameters():
p.requires_grad = ('lora_A' in name or 'lora_B' in name)
# 训练循环
for batch in dataloader:
outputs = model(**batch)
loss = criterion(outputs.logits, batch.labels)
loss.backward()
optimizer.step()
# 保存 LoRA 参数
torch.save(model.state_dict(), "bert_lora.pt")# QLoRA 量化 + LoRA
from bitsandbytes import quantize_4bit
for n,p in model.named_parameters():
p.data = quantize_4bit(p.data, dtype='nf4')
# 注入 LoRA 后同上训练代码
# 保存模型
model.save_pretrained("bert_qlora")3 BERT 分类任务:完整示例
本来应该是用chatglm,千问等大模型来来做演示的,但是此处只是为了讲解,这些训练的过程,所以使用大家熟悉的bert 模型来做。
下面以 PyTorch + Hugging Face Transformers 为原型,演示四种方法在 BERT 分类项目中的“训练→保存→加载→推理”流程。
3.1 Prompt Tuning
注释要点:
1. 冻结预训练模型:保证只有“软提示”与分类头参与训练,极大降低显存与计算开销。
2. 软提示(Prompt):用少量可学习的向量充当“伪 token”,引导模型关注下游任务特征。
3. 拼接逻辑:将 prompt 放在输入序列最前面,BERT 的 Transformer 自注意力会自动将其纳入计算。
4. 保存与加载:只需保存 prompt 与分类头,即可方便部署。
5. 推理流程:与训练相似,但不开启梯度,快速得到预测结果。
关键说明
-
attention_mask 扩展:在 prompt 前补 1,使得自注意力不会忽略 prompt 部分 。
-
token_type_ids 扩展:prompt 通常归为第 0 号句子,也可设置为其它值,务必与模型训练时一致 。
-
使用 inputs_embeds:通过 model(inputs_embeds=…, attention_mask=…, token_type_ids=…) 保证 BERT 自带的 绝对位置编码 与 句子编码 会自动加到我们拼接后的输入上,无需手动处理 。
-
取第 L 个位置:prompt 长度为 L,故第 L 个向量对应原始文本第 1 个 token 的“CLS 等价”表征,含 prompt 与输入信息 。
-
保存与加载:只需保存 prompt 与分类头,BERT 主干无需变动,极简部署。
通过以上改动,代码即完整支持了位置编码与句子编码,保证 soft prompt 能正确注入,而原有的自注意力机制与绝对位置编码均被保留。
import torch
import torch.nn as nn
from transformers import BertModel
from transformers import AdamW
# -----------------------------------------------------------------------------
# 1. 初始化
# -----------------------------------------------------------------------------
# 1.1 加载预训练 BERT 主干(不含任何 task-specific 头)
model = BertModel.from_pretrained('bert-base-uncased')
# 1.2 冻结所有 BERT 参数,只训练后续新增模块
for p in model.parameters():
p.requires_grad = False
# 1.3 软提示长度 L,可根据显存/性能自行调整
L = 20 # [turn0search0]
# 1.4 创建一个可训练的软提示向量,形状为 [L, H]
H = model.config.hidden_size
prompt = nn.Parameter(torch.randn(L, H)) # [turn0search4]
# 1.5 定义分类头,将隐藏维度 H 映射到类别数
num_labels = 2
classifier = nn.Linear(H, num_labels)
# 1.6 优化器只更新 prompt 和 classifier
optim_params = [prompt, *classifier.parameters()]
optimizer = AdamW(optim_params, lr=1e-3)
# 1.7 损失函数:交叉熵
loss_fn = nn.CrossEntropyLoss()
# -----------------------------------------------------------------------------
# 2. 训练循环
# -----------------------------------------------------------------------------
# 假设 train_loader 每个 batch 包含:
# batch['input_ids'] : [B, N]
# batch['attention_mask']: [B, N]
# batch['token_type_ids'] : [B, N] (可选,句子对任务需提供)
for batch in train_loader:
input_ids = batch['input_ids'] # [B, N]
orig_mask = batch['attention_mask'] # [B, N]
orig_token_ids = batch.get('token_type_ids',
torch.zeros_like(orig_mask)) # [B, N]
# 2.1 扩展 attention_mask: 在最前面为 L 个 prompt 置 1
# prompt_mask: [B, L]
prompt_mask = torch.ones(orig_mask.size(0), L,
dtype=orig_mask.dtype,
device=orig_mask.device) # [turn1search0]
new_mask = torch.cat([prompt_mask, orig_mask], dim=1) # [B, L+N]
# 2.2 扩展 token_type_ids: prompt 统一标为 0(或其他常数均可)
prompt_type = torch.zeros_like(prompt_mask, dtype=orig_token_ids.dtype)
new_token_ids = torch.cat([prompt_type, orig_token_ids], dim=1) # [B, L+N]
# 2.3 从 embedding table 拿到原始 prompt 的 word embeddings
# init_emb: [L, H]
init_emb = model.embeddings.word_embeddings(
torch.arange(L, device=orig_mask.device)) # [turn0search4]
# 2.4 用 LSTM/MLP 编码(此处以 LSTM 为例,也可改为 nn.Linear 等)
prompt_emb, _ = nn.LSTM(H, H, batch_first=True)(
init_emb.unsqueeze(0)) # [1, L, H]
# 2.5 扩展至 batch 大小 → [B, L, H]
pref = prompt_emb.expand(input_ids.size(0), -1, -1)
# 2.6 原始 token embeddings: [B, N, H]
emb = model.embeddings(input_ids) # [turn0search4]
# 2.7 拼接 prompt 与原始 embeddings → [B, L+N, H]
enc_inputs = torch.cat([pref, emb], dim=1) # [turn0search2]
# 2.8 调用 BertModel,传入 inputs_embeds、attention_mask、token_type_ids
# BertEmbeddings 层会在 inputs_embeds 上加上 position & token_type embeddings
outputs = model(inputs_embeds=enc_inputs,
attention_mask=new_mask,
token_type_ids=new_token_ids)
sequence_output = outputs.last_hidden_state # [B, L+N, H]
# 2.9 取第 L 个位置(即 prompt 之后首个 token)做“CLS”等价表示
pooled_rep = sequence_output[:, L, :] # [B, H]
# 2.10 分类 & 计算损失
logits = classifier(pooled_rep) # [B, num_labels]
loss = loss_fn(logits, batch['labels'])
# 2.11 反向传播 & 更新
loss.backward()
optimizer.step()
optimizer.zero_grad()
# -----------------------------------------------------------------------------
# 3. 保存
# -----------------------------------------------------------------------------
# 3.1 保存 prompt 向量
torch.save(prompt.state_dict(), "pt_prompts.bin")
# 3.2 保存分类头
torch.save(classifier.state_dict(), "pt_cls.bin")
# -----------------------------------------------------------------------------
# 4. 加载 & 推理
# -----------------------------------------------------------------------------
# 4.1 重建 prompt 并加载
prompt = nn.Parameter(torch.empty(L, H))
prompt.load_state_dict(torch.load("pt_prompts.bin"))
# 4.2 重建分类头并加载
classifier = nn.Linear(H, num_labels)
classifier.load_state_dict(torch.load("pt_cls.bin"))
# 4.3 推理模式
model.eval()
classifier.eval()
with torch.no_grad():
# 假设 test_ids, test_mask, test_token_type_ids 形状分别 [B, N]
emb = model.embeddings(test_ids) # [B, N, H]
prompt_mask = torch.ones(test_mask.size(0), L,
dtype=test_mask.dtype,
device=test_mask.device)
new_mask = torch.cat([prompt_mask, test_mask], dim=1) # [B, L+N]
prompt_type = torch.zeros_like(prompt_mask, dtype=test_token_type_ids.dtype)
new_types = torch.cat([prompt_type, test_token_type_ids], dim=1) # [B, L+N]
prompt_emb, _ = lstm(init_emb.unsqueeze(0)) # [1, L, H]
pref = prompt_emb.expand(test_ids.size(0), -1, -1) # [B, L, H]
enc_inputs = torch.cat([pref, emb], dim=1) # [B, L+N, H]
outputs = model(inputs_embeds=enc_inputs,
attention_mask=new_mask,
token_type_ids=new_types)
seq_out = outputs.last_hidden_state # [B, L+N, H]
rep = seq_out[:, L, :] # [B, H]
logits = classifier(rep) # [B, num_labels]
preds = logits.argmax(dim=-1) # [B]3.2 P-Tuning
关键说明
-
prompt_ids → init_emb:借助 BERT 的 embedding table 获取初始连续提示嵌入。
-
LSTM 编码:通过小型 LSTM(或通用 MLP)进一步转换提示向量,增强其表达能力。
-
拼接逻辑:将提示嵌入放在序列最前端,BERT 的自注意力会自动将其纳入上下文。
-
CLS 等价:拼接后第 prompt_len 位置处的向量即为融合了提示与输入的全局表示,用于分类。
-
推理流程:与训练相同,但无梯度计算,速度更快。
-
attention_mask 扩展:在 prompt 前补 1,使得自注意力不会忽略 prompt 部分 。
-
token_type_ids 扩展:prompt 通常归为第 0 号句子,也可设置为其它值,务必与模型训练时一致 。
-
使用 inputs_embeds:通过 model(inputs_embeds=…, attention_mask=…, token_type_ids=…) 保证 BERT 自带的 绝对位置编码 与 句子编码 会自动加到我们拼接后的输入上,无需手动处理 。
-
取第 L 个位置:prompt 长度为 L,故第 L 个向量对应原始文本第 1 个 token 的“CLS 等价”表征,含 prompt 与输入信息 。
-
保存与加载:只需保存 prompt 与分类头,BERT 主干无需变动,极简部署。
通过以上改动,代码即完整支持了位置编码与句子编码,保证 soft prompt 能正确注入,而原有的自注意力机制与绝对位置编码均被保留。
import torch
import torch.nn as nn
from transformers import BertModel, AdamW
# -----------------------------------------------------------------------------
# 1. 初始化阶段
# -----------------------------------------------------------------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 1.1 加载预训练的 BERT 主干(不含 task-specific 头),并移到 device
model = BertModel.from_pretrained('bert-base-uncased').to(device)
# 1.2 冻结 BERT 主干所有参数,只训练下面新增的部分
for p in model.parameters():
p.requires_grad = False
# 1.3 软提示长度 L(可调)
L = 20
# 1.4 伪 token IDs,用于从 embedding table 取初始 prompt 向量
prompt_ids = torch.arange(L, device=device)
# 1.5 创建 LSTM 作为 prompt encoder
H = model.config.hidden_size
prompt_encoder = nn.LSTM(
input_size=H,
hidden_size=H,
batch_first=True
).to(device)
# 1.6 定义分类头
num_labels = 2
classifier = nn.Linear(H, num_labels).to(device)
# 1.7 优化器:仅优化 prompt encoder 和分类头参数
optimizer = AdamW(
list(prompt_encoder.parameters()) + list(classifier.parameters()),
lr=1e-3
)
# -----------------------------------------------------------------------------
# 2. 训练循环
# -----------------------------------------------------------------------------
# 假设 train_loader 每 batch 提供:
# batch['input_ids'] : [B, N]
# batch['attention_mask']: [B, N]
# batch['token_type_ids'] : [B, N](可选)
# batch['labels'] : [B]
for batch in train_loader:
# 2.1 数据搬到 device
input_ids = batch['input_ids'].to(device)
orig_mask = batch['attention_mask'].to(device)
orig_types = batch.get('token_type_ids',
torch.zeros_like(orig_mask)).to(device)
labels = batch['labels'].to(device)
B, N = input_ids.size()
# 2.2 构造新的 attention_mask:prompt 部分全部设为 1
prompt_mask = torch.ones(B, L, dtype=orig_mask.dtype, device=device)
new_mask = torch.cat([prompt_mask, orig_mask], dim=1) # [B, L+N]
# 2.3 构造新的 token_type_ids:prompt 部分设为 0
prompt_type = torch.zeros_like(prompt_mask, dtype=orig_types.dtype, device=device)
new_types = torch.cat([prompt_type, orig_types], dim=1) # [B, L+N]
# 2.4 从 embedding table 提取初始 prompt 嵌入 [L, H]
init_emb = model.embeddings.word_embeddings(prompt_ids) # [L, H]
# 2.5 通过 prompt encoder(LSTM)生成最终 prompt 嵌入 [1, L, H]
prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0)) # [1, L, H]
# 2.6 扩展至 batch 大小 → [B, L, H]
pref = prompt_emb.expand(B, -1, -1)
# 2.7 获取原始文本 embeddings → [B, N, H]
emb = model.embeddings(input_ids) # [B, N, H]
# 2.8 拼接两个部分 → [B, L+N, H]
inputs_embeds = torch.cat([pref, emb], dim=1) # [B, L+N, H]
# 2.9 调用 BERT,传入 inputs_embeds、attention_mask 和 token_type_ids
outputs = model(
inputs_embeds=inputs_embeds,
attention_mask=new_mask,
token_type_ids=new_types
)
sequence_output = outputs.last_hidden_state # [B, L+N, H]
# 2.10 取第 L 个位置的向量作为 “CLS 等价” 表示 → [B, H]
cls_equiv = sequence_output[:, L, :]
# 2.11 分类 & 计算损失
logits = classifier(cls_equiv) # [B, num_labels]
loss = nn.CrossEntropyLoss()(logits, labels)
# 2.12 反向传播 & 参数更新
loss.backward()
optimizer.step()
optimizer.zero_grad()
# -----------------------------------------------------------------------------
# 3. 保存训练好的参数
# -----------------------------------------------------------------------------
# 3.1 保存 prompt encoder 权重
torch.save(prompt_encoder.state_dict(), "ptuning_encoder.bin")
# 3.2 保存分类头权重
torch.save(classifier.state_dict(), "ptuning_cls.bin")
# -----------------------------------------------------------------------------
# 4. 加载 & 推理
# -----------------------------------------------------------------------------
# 4.1 重建 prompt encoder 并加载
prompt_encoder = nn.LSTM(input_size=H, hidden_size=H, batch_first=True).to(device)
prompt_encoder.load_state_dict(torch.load("ptuning_encoder.bin"))
# 4.2 重建分类头并加载
classifier = nn.Linear(H, num_labels).to(device)
classifier.load_state_dict(torch.load("ptuning_cls.bin"))
# 4.3 设置为推理模式
model.eval()
prompt_encoder.eval()
classifier.eval()
# 4.4 推理循环
for batch in test_loader:
input_ids = batch['input_ids'].to(device)
orig_mask = batch['attention_mask'].to(device)
orig_types = batch.get('token_type_ids',
torch.zeros_like(orig_mask)).to(device)
B, N = input_ids.size()
prompt_mask = torch.ones(B, L, dtype=orig_mask.dtype, device=device)
new_mask = torch.cat([prompt_mask, orig_mask], dim=1)
prompt_type = torch.zeros_like(prompt_mask, dtype=orig_types.dtype, device=device)
new_types = torch.cat([prompt_type, orig_types], dim=1)
init_emb = model.embeddings.word_embeddings(prompt_ids)
prompt_emb, _= prompt_encoder(init_emb.unsqueeze(0))
pref = prompt_emb.expand(B, -1, -1)
emb = model.embeddings(input_ids)
inputs_embeds= torch.cat([pref, emb], dim=1)
outputs = model(
inputs_embeds=inputs_embeds,
attention_mask=new_mask,
token_type_ids=new_types
)
seq_out = outputs.last_hidden_state
cls_equiv = seq_out[:, L, :]
logits = classifier(cls_equiv)
preds = torch.argmax(logits, dim=-1)
# 处理 preds (例如计算准确率或保存结果)
# ...以GPT2自回归模型来讲解 p_turning
要点说明
-
使用 LSTM 作为 Prompt Encoder,可捕捉提示向量序列的时序依赖;
-
前 L 个位置的 labels 设为 -100,保证 loss 只计算在真实文本部分;
-
GPT-2 自带位置编码与因果遮掩,无需手动处理;
-
生成时也使用 inputs_embeds,并在输出时剔除前 L 个“伪 token”。
-
teacher Forcing 是一种经典的自回归序列模型训练策略,最早由 Williams 和 Zipser 在 1989 年提出,用于加速和稳定循环神经网络(RNN)的训练 。其核心思路是在训练阶段,模型每一步的输入不使用模型自身上一步的预测结果,而是直接采用真实标记(ground truth),以此减少误差累积并加快收敛 。在生成(推理)阶段,则依次将模型预测的标记拼回输入,完成逐步自回归生成。
import torch
import torch.nn as nn
from transformers import GPT2LMHeadModel, GPT2Tokenizer, AdamW
# 0. 环境与模型初始化
# 设备选取:若有可用 GPU 则用 GPU,否则用 CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载 GPT-2 自回归语言模型与分词器,并将模型移到 device
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2').to(device)
# 冻结 GPT-2 主干所有参数,只保留微调 Prompt Encoder 的权重
for p in model.parameters():
p.requires_grad = False
# 1. P-Tuning 参数与模块定义
# 定义 Prompt 长度 L,可根据显存与任务难度调节
L = 30
# GPT-2 隐藏层维度 H,等同于 embedding 维度
H = model.config.n_embd
# 从 GPT-2 的词向量表中取出 L 个“伪 token”对应的初始 embedding
prompt_ids = torch.arange(L, device=device)
init_emb = model.transformer.wte(prompt_ids) # [L, H]
# 创建 LSTM Prompt Encoder:输入 [1, L, H] → 输出 [1, L, H]
prompt_encoder = nn.LSTM(
input_size=H, hidden_size=H, num_layers=1, batch_first=True
).to(device)
# 仅训练 Prompt Encoder 的参数
optimizer = AdamW(prompt_encoder.parameters(), lr=5e-5)
# 2. 训练循环(自回归语言建模)
model.train()
prompt_encoder.train()
for epoch in range(num_epochs):
for batch in train_loader:
# 假设 batch 中含有:
# batch['input_ids'] : [B, N]
# batch['attention_mask']: [B, N]
# batch['labels'] : [B, N],用于计算下一个 token 的监督信号
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
B, N = input_ids.size()
# 2.1 用 LSTM 编码初始 prompt embedding → [1, L, H]
prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0))
# 2.2 扩展到 batch 大小 → [B, L, H]
prompt_emb = prompt_emb.expand(B, -1, -1)
# 2.3 获取原始输入 token embedding → [B, N, H]
token_emb = model.transformer.wte(input_ids)
# 2.4 拼接 prompt 与原始 embeddings → [B, L+N, H]
inputs_embeds = torch.cat([prompt_emb, token_emb], dim=1)
# 2.5 构造新的 attention_mask:在 prompt 部分填 1 → [B, L+N]
prompt_mask = torch.ones(B, L, device=device)
new_mask = torch.cat([prompt_mask, attention_mask], dim=1)
# 2.6 构造新的 labels:prompt 部分设为 -100,跳过 loss 计算 → [B, L+N]
prompt_labels = torch.full((B, L), -100, device=device, dtype=torch.long)
new_labels = torch.cat([prompt_labels, labels], dim=1)
# 2.7 前向计算,自回归地并行预测所有位置下一个 token
outputs = model(
inputs_embeds=inputs_embeds,
attention_mask=new_mask,
labels=new_labels
)
loss = outputs.loss
# 2.8 反向传播 & 更新 Prompt Encoder
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch+1} loss: {loss.item():.4f}")
# 3. 保存 Prompt Encoder
torch.save(prompt_encoder.state_dict(), "gpt2_ptuning_lstm.bin")
# 4. 加载 & 推理
# 4.1 重建并加载 Prompt Encoder
prompt_encoder = nn.LSTM(input_size=H, hidden_size=H, batch_first=True).to(device)
prompt_encoder.load_state_dict(torch.load("gpt2_ptuning_lstm.bin"))
model.eval()
prompt_encoder.eval()
# 4.2 准备初始上下文
context = "In a distant future"
tokens = tokenizer(context, return_tensors="pt").to(device)
input_ids = tokens.input_ids
attention_mask = tokens.attention_mask
B, N = input_ids.size()
# 4.3 生成 prompt_emb → [1, L, H] → 扩展为 [B, L, H]
prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0))
prompt_emb = prompt_emb.expand(B, -1, -1)
# 4.4 获取原始 embeddings & 拼接
token_emb = model.transformer.wte(input_ids)
inputs_embeds = torch.cat([prompt_emb, token_emb], dim=1)
# 4.5 构造新的 attention_mask
prompt_mask = torch.ones(B, L, device=device)
new_mask = torch.cat([prompt_mask, attention_mask], dim=1)
# 4.6 自回归生成并剔除 prompt 部分
generated = model.generate(
inputs_embeds=inputs_embeds,
attention_mask=new_mask,
max_length=L + N + 50
)
generated = generated[:, L:]
# 4.7 解码并输出
print(tokenizer.decode(generated[0], skip_special_tokens=True))
DeepSeek-R1 P-Tuning 示例代码
以下代码展示了对 DeepSeek-R1 模型进行 P-Tuning 的全流程:冻结主干 → 构造连续提示 → 并行化微调 → 保存加载 → 自回归生成。根据具体硬件与任务需求,可将 model_name 替换为任意 Distill 版本以实现更轻量化部署。
比如
-
DeepSeek-R1-Distill-Qwen-1.5B
-
DeepSeek-R1-Distill-Llama-7B/8B
-
DeepSeek-R1 / DeepSeek-R1-Zero
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer, AdamW
# 0. 设备与模型加载
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_name = "deepseek-ai/DeepSeek-R1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
for p in model.parameters():
p.requires_grad = False
# 1. Prompt Encoder 定义
L = 30
H = model.config.n_embd
prompt_ids = torch.arange(L, device=device)
init_emb = model.get_input_embeddings()(prompt_ids) # [L, H]
prompt_encoder = nn.LSTM(input_size=H, hidden_size=H, batch_first=True).to(device)
optimizer = AdamW(prompt_encoder.parameters(), lr=5e-5)
# 2. 训练循环
model.train()
prompt_encoder.train()
for batch in train_loader:
input_ids = batch["input_ids"].to(device) # [B, N]
attention_mask = batch["attention_mask"].to(device) # [B, N]
labels = batch["labels"].to(device) # [B, N]
B, N = input_ids.size()
# 2.1 生成 Prompt Embedding → [1, L, H] → 扩展至 [B, L, H]
prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0))
prompt_emb = prompt_emb.expand(B, -1, -1)
# 2.2 获取输入 embeddings & 拼接 → [B, L+N, H]
token_emb = model.get_input_embeddings()(input_ids)
inputs_embeds = torch.cat([prompt_emb, token_emb], dim=1)
# 2.3 构造新的 attention_mask & labels
prompt_mask = torch.ones(B, L, device=device)
new_mask = torch.cat([prompt_mask, attention_mask], dim=1)
prompt_labels = torch.full((B, L), -100, device=device, dtype=torch.long)
new_labels = torch.cat([prompt_labels, labels], dim=1)
# 2.4 前向 + 反向
outputs = model(inputs_embeds=inputs_embeds,
attention_mask=new_mask,
labels=new_labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 3. 保存 Prompt Encoder
torch.save(prompt_encoder.state_dict(), "deepseek_ptuning_lstm.bin")
# 4. 加载 & 推理
prompt_encoder.load_state_dict(torch.load("deepseek_ptuning_lstm.bin"))
model.eval()
prompt_encoder.eval()
context = "In a distant future"
tokens = tokenizer(context, return_tensors="pt").to(device)
input_ids, attn = tokens.input_ids, tokens.attention_mask
B, N = input_ids.size()
prompt_emb, _ = prompt_encoder(init_emb.unsqueeze(0))
prompt_emb = prompt_emb.expand(B, -1, -1)
token_emb = model.get_input_embeddings()(input_ids)
inputs_embeds = torch.cat([prompt_emb, token_emb], dim=1)
prompt_mask = torch.ones(B, L, device=device)
new_mask = torch.cat([prompt_mask, attn], dim=1)
generated = model.generate(inputs_embeds=inputs_embeds,
attention_mask=new_mask,
max_length=L+N+50)[:, L:]
print(tokenizer.decode(generated[0], skip_special_tokens=True))3.3 LoRA
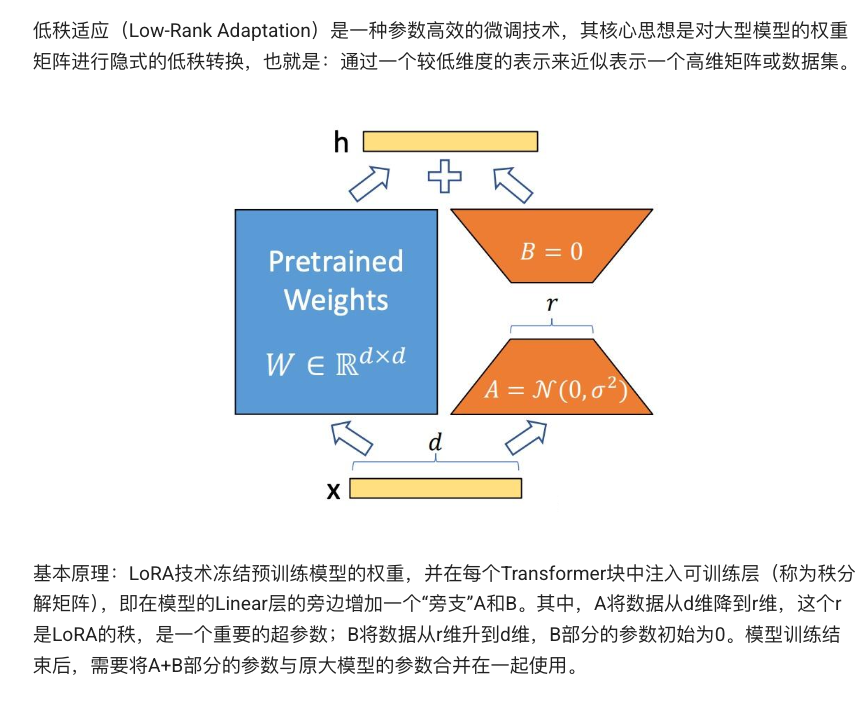
Low-Rank Adaptation (LoRA) 是一种参数高效微调(PEFT)技术,通过将原始的大规模模型权重更新分解成两个低秩矩阵 和
,并替代原始权重增量,实现只训练这两段小矩阵而冻结其他参数,从而将可训练参数量降低约 10,000 倍,显存占用减少 3 倍,并保持与全量微调相当或更优的表现 。
-
核心原理:在 Transformer 的线性层 W 旁路注入低秩增量
,
其中
,
为缩放系数,通常设定为
以平衡学习速率与参数尺度 。
-
优点:
-
极少可训练参数:仅占原模型的零点几至千分之一;
-
无推理延迟:与原模型结构兼容,无需在推理时合并额外层;
-
高效易用:Hugging Face PEFT、LoRAX 等开源工具提供开箱即用实现 。
-
LoRA 现已成为 2025 年主流大模型微调方法之一,广泛应用于 BERT、GPT-2/3、LLaMA、DeepSeek-R1 等多种模型。

# 1. LoRA 注入方法略——替换所有 nn.Linear 为 LoRALinear
for p in model.parameters(): p.requires_grad=False
for m in model.modules():
if isinstance(m, LoRALinear):
for p in m.parameters(): p.requires_grad=True
classifier = nn.Linear(H, num_labels)
optimizer = AdamW(list(filter(lambda p:p.requires_grad, model.parameters())) + list(classifier.parameters()), lr=1e-4)
# 2. 训练/保存/加载 同常规 fine-tuning
1. BERT 上的 LoRA 微调示例
import torch
from transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
# 1.1 设备与模型/分词器加载
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "bert-base-uncased"
tokenizer = BertTokenizerFast.from_pretrained(model_id)
model = BertForSequenceClassification.from_pretrained(model_id, num_labels=2).to(device) # 二分类 [oai_citation:0‡Hugging Face](https://huggingface.co/docs/transformers/en/peft?utm_source=chatgpt.com)
# 1.2 冻结主模型参数,只训练 LoRA 矩阵
for param in model.base_model.parameters():
param.requires_grad = False # 冻结 Bert 主体
# 1.3 配置 LoRA
lora_config = LoraConfig(
task_type="SEQ_CLS", # 序列分类任务
inference_mode=False, # 微调模式
r=8, # LoRA 低秩矩阵秩
lora_alpha=16, # 缩放系数
lora_dropout=0.1, # Dropout 比例
target_modules=["query", "value"] # 在自注意力的 query 和 value 矩阵上注入
) [oai_citation:1‡Hugging Face](https://huggingface.co/docs/peft/en/package_reference/lora?utm_source=chatgpt.com)
# 1.4 包装模型
model = get_peft_model(model, lora_config) # 插入 A, B 矩阵 [oai_citation:2‡Hugging Face](https://huggingface.co/docs/peft/main/en/developer_guides/lora?utm_source=chatgpt.com)
model.print_trainable_parameters() # 输出可训练参数比例
# 1.5 准备训练数据(示例)
texts = ["I love this!", "This is terrible."]
labels = [1, 0]
enc = tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(device)
dataset = torch.utils.data.TensorDataset(enc["input_ids"], enc["attention_mask"], torch.tensor(labels))
# 1.6 定义 Trainer
training_args = TrainingArguments(
output_dir = "./bert-lora-output",
per_device_train_batch_size = 8,
num_train_epochs = 3,
learning_rate = 3e-4,
logging_steps = 10,
save_steps = 50
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
# 1.7 训练
trainer.train() # 仅更新 LoRA 矩阵参数 [oai_citation:3‡GitHub](https://github.com/huggingface/peft?utm_source=chatgpt.com)
# 1.8 保存 & 加载
model.save_pretrained("bert-lora-model")
# 重新加载时:
# from peft import PeftModel
# model = BertForSequenceClassification.from_pretrained(model_id, num_labels=2)
# model = PeftModel.from_pretrained(model, "bert-lora-model")
2. DeepSeek-R1 上的 LoRA 微调示例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
# 2.1 设备与模型/分词器加载
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "deepseek-ai/DeepSeek-R1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id).to(device) # 自回归模型 [oai_citation:4‡Hugging Face](https://huggingface.co/docs/transformers/en/peft?utm_source=chatgpt.com)
# 2.2 冻结主模型参数,只训练 LoRA 矩阵
for param in model.parameters():
param.requires_grad = False
# 2.3 配置 LoRA(自回归任务)
lora_config = LoraConfig(
task_type="CAUSAL_LM", # 自回归语言模型
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.05,
target_modules=["c_attn", "c_proj"] # GPT 风格模型的注意力层
) [oai_citation:5‡Hugging Face](https://huggingface.co/docs/peft/en/package_reference/lora?utm_source=chatgpt.com)
# 2.4 包装模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 2.5 准备训练数据(示例)
texts = [
"Once upon a time,",
"In a galaxy far, far away,"
]
enc = tokenizer(texts, return_tensors="pt", padding=True, truncation=True).to(device)
# Labels = 输入右移一位的 input_ids
labels = enc["input_ids"].clone()
dataset = torch.utils.data.TensorDataset(enc["input_ids"], enc["attention_mask"], labels)
# 2.6 定义 Trainer
training_args = TrainingArguments(
output_dir = "./deepseek-lora-output",
per_device_train_batch_size = 4,
num_train_epochs = 3,
learning_rate = 2e-4,
logging_steps = 10,
save_steps = 50
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
# 2.7 训练
trainer.train() # LoRA 矩阵参与梯度更新
# 2.8 保存 & 加载
model.save_pretrained("deepseek-lora-model")
# 重新加载时:
# from peft import PeftModel
# base = AutoModelForCausalLM.from_pretrained(model_id)
# model = PeftModel.from_pretrained(base, "deepseek-lora-model")3.4 QLoRA
# 1. 4-bit 量化
for n,p in model.named_parameters():
p.data = quantize_4bit(p.data, dtype='nf4')
# 2. 注入 LoRA + 冻结主体 + 训练
# 3. model.save_pretrained & from_pretrained 进行加载推理只是比lora 加了
# 1. 4-bit 量化
for n,p in model.named_parameters():
p.data = quantize_4bit(p.data, dtype='nf4')
通过上述详细流程,您即可在 2025 年的常见生产场景中,根据数据量、资源与任务需求,灵活选择和实施软提示(Prompt/P-Tuning)或参数高效微调(LoRA/QLoRA)方法,实现千亿参数模型的高效适配与部署。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









