







1、介绍
作者回顾了目标检测技术近二十年来的发展历程,参考了400多篇相关论文,讨论主题包括历史上的里程碑检测器、检测数据集、度量标准、检测系统基本构建块、加速技术以及最新检测方法。论文还对行人检测、人脸检测、文本检测等重要检测应用进行了综述,并对近年来它们面临的挑战和技术改进进行了分析。
从应用角度来看,目标检测可以分为通用目标检测和检测应用。前者利用统一框架检测不同类型目标,后者则是特定的检测应用场景,如行人检测、人脸检测、文本检测等。
图 1. 为近年来目标检测领域发表的论文数量变化趋势
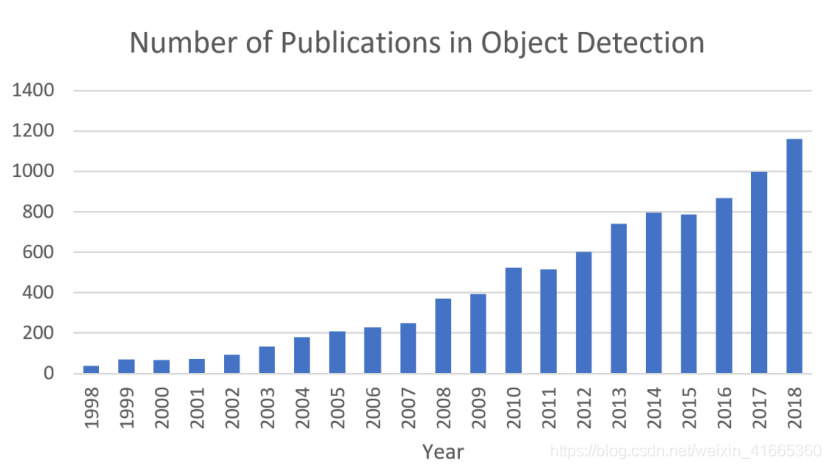
图 1. 从1998-2018年目标检测领域发表的论文不断增加
本文与其他综述的主要区别在于:
- 根据技术发展的脉络进行全面的回顾
- 对关键技术和最新技术进行深入探索
- 对检测加速技术的综合分析
目标检测的困难和挑战
除了常见的计算机视觉任务面临的挑战,比如:不同视角、光照、类中差异等,目标检测面临的挑战包括但是不限于以下几个方面:
- 目标旋转和尺度变化(小目标)
- 精确目标定位
- 稠密和遮挡目标检测
- 检测加速
作者在第 2 2 2 部分回顾了目标检测 20 20 20 年来的发展史。第 3 3 3 部分介绍目标检测加速技术。第 4 4 4 部分总结了近三年来最新的检测方法。第 5 5 5 部分回顾了一些重要的检测应用。第 6 6 6 部分总结论文,分析未来研究方向。
2、目标检测的20年发展历程
这部分将介绍里程碑检测器、检测数据集、度量准则以及关键技术发展
2.1、目标检测路线
过去20年,目标检测经历了两个主要阶段:传统目标检测(2014年之前)、深度学习目标检测(2014年之后)
图 2. 展示了目标检测发展历程
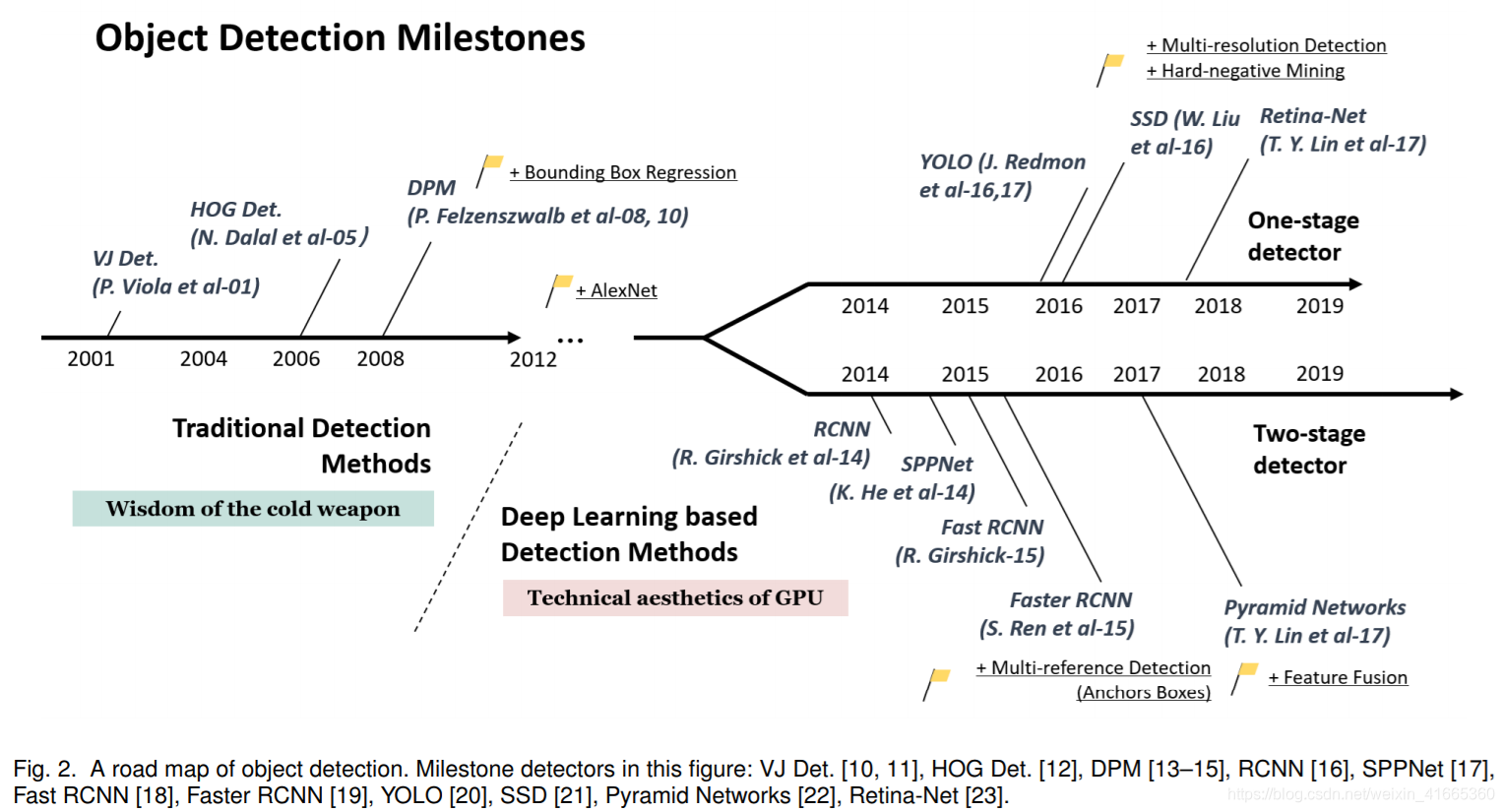
图 2. 目标检测发展路线
2.1.1、里程碑:传统检测器
传统目标检测算法建立在手工设计的特征的基础上。由于缺乏有效的图像表示,人们别无选择,只能设计复杂的特征,以及各种加速技巧来使用有限的计算资源。
VJ 检测器
V J VJ VJ 检测器首次实现了无约束的实时人脸检测(如,皮肤颜色分割)。运行在 700 M H z P e n t i u m I I I C P U 700MHz~Pentium~III~CPU 700MHz Pentium III CPU 上,同等精度下比其他算法快几十倍甚至几百倍。
V J VJ VJ 检测器遵循最直接的检测方式,即滑动窗口:通过图像中所有可能的位置和尺度来查看是否包含人脸。这种过程看似简单,背后的计算远远超出该时代计算机的算力。 V J VJ VJ 检测器采用积分图、特征选择、检测级联极大地提升了检测速度。
积分图:积分图是一种加速框过滤或卷积过程的计算方法。和同时期的其他方法一样, V J VJ VJ 检测器使用 H a a r Haar Haar 小波作为图像的特征表示。积分图使每个窗口的计算复杂度与窗口大小无关。
特征选择: 作者没有使用一组人工选择的 H a a r Haar Haar 基滤波器,而是使用 A d a b o o s t Adaboost Adaboost 算法从一组大量随机特征池中选择一组最有利于人脸检测的小特征集。
检测级联: V J VJ VJ 检测器引入多阶段检测范式(检测级联),通过减少背景窗口上的计算,增加人脸目标计算来减少计算开销。
HOG 检测器
H O G HOG HOG 被看作是该时期尺度不变特征变换和形状上下文的重要改进。为平衡特征不变性(平移、缩放、光照)和非线性(区分不同类目标), H O G HOG HOG 描述符被设计成在均匀间隔单元的密集网格上计算,并使用重叠的局部对比归一化来提高精度。尽管 H O G HOG HOG 可以用于检测多种目标,它的最初动机是行人检测。为检测不同大小的目标, H O G HOG HOG 多次缩放输入图像,并保持检测窗口大小不变。
DPM
D P M DPM DPM 遵循分而治之的思想,训练可以简单地看作是学习一种正确的目标分解方法,推理可以看作是对不同目标部位的检测的集合。比如,检测车的问题,可以看作是对车窗,车体,轮子的综合检测。星模型的研究是由 P . F e l z e n s z w a l b P. Felzenszwalb P.Felzenszwalb 等人完成的, R . G i r s h i c k R. Girshick R.Girshick 等人进一步将星模型扩展到混合模型。
典型的 D P M DPM DPM 检测器是由根滤波器和部位滤波器组成。 D P M DPM DPM 提出一种弱监督学习方法,而不是手动指定部位滤波器配置(例如,大小和位置),它可以将部位滤波器的所有配置作为潜在变量来学习。 R . G i r s h i c k R. Girshick R.Girshick 将此过程进一步表述为多实例学习的特例,并使用难分负样本挖掘、边界框回归和 context priming 来提升检测精度。 G i r s h i c k Girshick Girshick 开发了一种 “编译” 检测模型的技术,使模型变得更快,实现了级联架构,在不损害精度的条件下,速度提升了十倍以上。
2.1.2、基于CNN的两阶段检测器
RCNN
首先通过 S e l e c t i v e S e a r c h Selective Search SelectiveSearch 提取一系列目标提议,然后将每个提议缩放到特定大小喂到卷积神经网络中提取特征,最后使用线性 S V M SVM SVM 预测提议中是否包含目标,以及目标属于哪个类别。
尽管 R C N N RCNN RCNN 有了很大提升,它的缺陷也很明显:大量重叠提议上的冗余特征计算导致检测速度极其慢。
SPP-Net
S P P − N e t SPP-Net SPP−Net 的主要贡献是提出了空间金字塔池化层(SPP),这使 C N N CNN CNN 对任意大小的图像和 R O I ROI ROI 能够生成固定大小的表征,而不需要进行缩放。使用 S P P − N e t SPP-Net SPP−Net 进行目标检测,只需从整个图像提取一次特征图,就可以生成任意区域的固定长度的表征来训练检测器,避免了重复卷积运算。
在不牺牲精度的条件下, S P P − N e t SPP-Net SPP−Net 检测速度比 R − C N N R-CNN R−CNN 快 20 20 20 倍。但是它仍然有一些缺点,首先,训练是分阶段进行的,其次,只微调了全连接层,忽略了之前所有层。
Fast RCNN
结合 R − C N N R-CNN R−CNN 和 S P P − N e t SPP-Net SPP−Net, F a s t R − C N N Fast~R-CNN Fast R−CNN 相比于 R − C N N R-CNN R−CNN 精度从 58.5 % 58.5\% 58.5% 提升到 70.0 % 70.0\% 70.0%,检测速度提升了 200 200 200 倍。
但是它的检测速度仍然受限于 S e l e c t i v e S e a r c h Selective~Search Selective Search。
Faster R-CNN
它是第一个端到端,第一个近实时的深度学习检测器。它的主要贡献是引入了 R P N RPN RPN,使区域提议近乎无时间损耗。它将区域提议、特征提取、边界框回归集成在一个统一的,端到端框架中。
FPN
在 F P N FPN FPN 之前,大多数检测器只在网络顶层进行检测。虽然深层特征有利于目标分类,但是不利于目标定位。为此, F P N FPN FPN 开发了一个具有横向连接的自顶向下的体系结构,用在所有尺度上构建高级语义。由于 C N N CNN CNN 通过前向传播自然形成一个特征金字塔, F P N FPN FPN 在多尺度目标检测方面显示出巨大的进步。
2.1.3、基于CNN的单阶段检测器
YOLO
相比于之前的检测方法, Y O L O YOLO YOLO 没有区域提议步骤,能够实现快速检测。尽管检测速度有极大的提升,但是相比于 t w o − s t a g e two-stage two−stage 方法,定位精度下降,尤其对于一些小目标更是如此
SSD
S S D SSD SSD 引入了多参考多分辨率检测技术,极大地提高了单阶段检测器精度,特别对一些小物体而言。 S S D SSD SSD 在检测速度和精度方面有优势。 S S D SSD SSD 和之前的检测器的区别在于,它在不同层上检测不同尺度的目标。
RetinaNet
尽管单极检测器速度快而且简单,但是精度上已经落后两级检测器很多年。极端的前景-背景类不平衡是造成这一现象的主要原因。作者在交叉熵损失的基础上引入 f o c a l l o s s focal~loss focal loss,训练时,重点关注难分、误分类样本。
2.2、目标检测数据集和度量标准
这些数据集的统计数字见表 1 1 1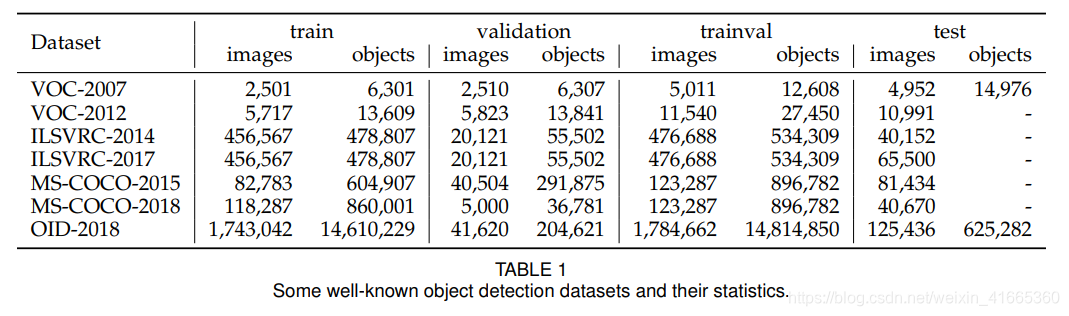
图 3 3 3 为08-18年在数据集上的检测精度
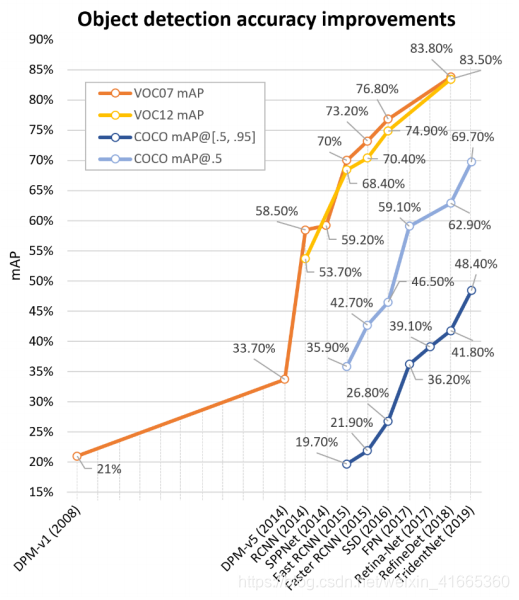
图 3 3 3 在VOC07、VOC12、MS-COCO数据集上的检测精度
Pascal VOC
Pascal Visual Object Classes(05-12) 是计算机视觉领域最重要的赛事之一。包含多任务,图像分类、目标检测、语义分割和行为检测。主要有两个版本的 Pascal-VOC 用于检测:VOC07 和 VOC12,前者包含 5K 张训练图像,共 12K 个标注目标。后者包含 11K 张训练图像,共 27K 个标注目标。两个数据集中包含了 20 个生活中常见的目标类(Person:person;Animal:bird, cat, cow, dog, horse, sheep; Vehicle:aeroplane, bicycle, boat, bus, car, motor-bike, train; Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor)
ILSVRC
ImageNet Large Scale Visual Recognition Challenge(10-17) 包含检测挑战赛。检测数据集包括 200 类视觉目标,图像/目标比 VOC 大两个数量级。例如,ILSVRC-14 包含517K 图像以及 534K 注释目标。
MS-COCO
MS-COCO 是当前最有挑战性的目标检测数据集。从 15 年开始举办比赛。它的目标类别比 ILSVRC 少,但是目标实例更多。例如,MS-COCO-17 包含 164K 张图像,来自 80 类的 897K 个标注目标。与 VOC 和 ILSVRC 相比,MS-COCO 除了边界框注释以外,每个目标通过实例分割进一步标注来帮助精确定位。此外,它包含更多小目标(面积小于图像的 1 % 1\% 1%),以及密集定位目标。这些特点使 M S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









