







前言:
先抓取一页数据-》查看信息之所以查看更多是因为分页-》所以可以先抓取一页数据,再循环页码就可以得到全部数据
被抓地址:http://jhsjk.people.cn/result/?area=402
分了3页

抓取1页数据所有的标题
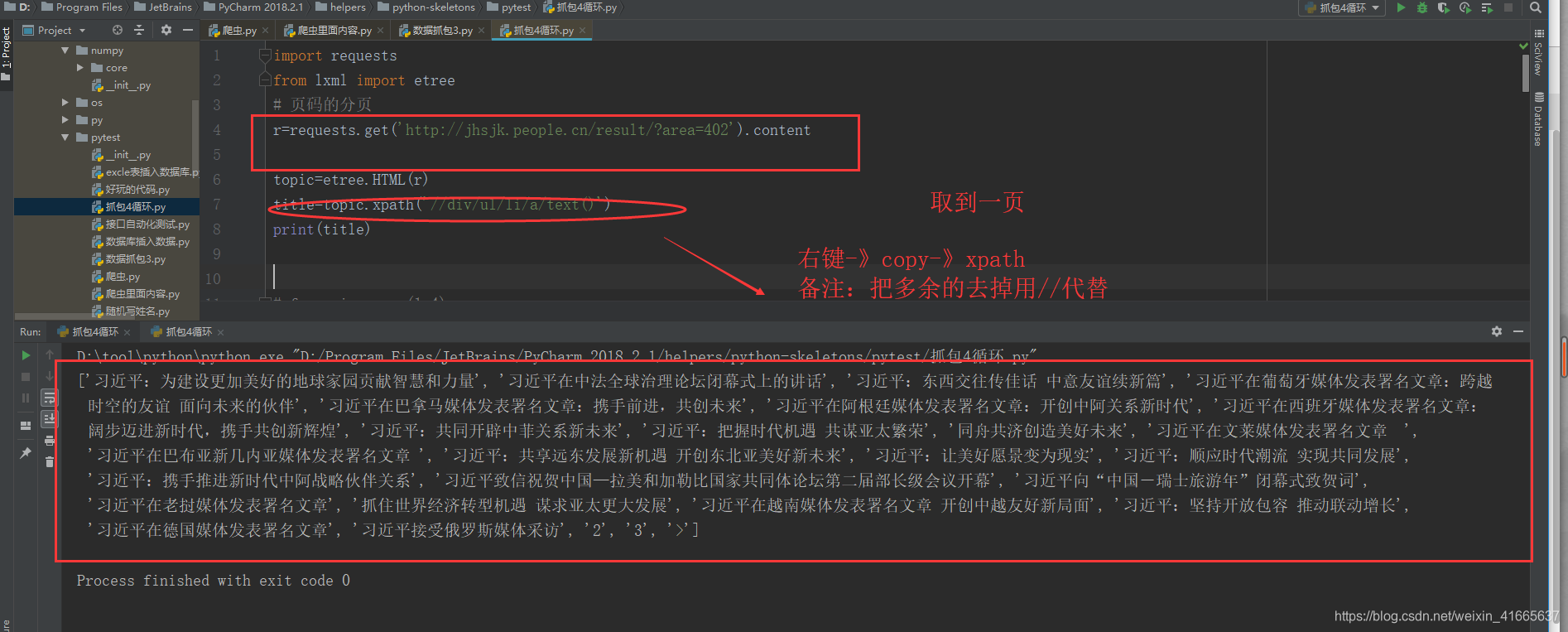

import requests
from lxml import etree
# 页码的分页
r=requests.get('http://jhsjk.people.cn/result/?area=402').content
topic=etree.HTML(r)
title=topic.xpath('//div/ul/li/a/text()')
print(title)
``
==========翻页
分析

翻页

运用到代码中

import requests
from lxml import etree
for a in range(1,4):
m=‘http://jhsjk.people.cn/result/’+str(a)+’?area=402’
l=requests.get(m).content
topic=etree.HTML(l)
title=topic.xpath('//div/ul/li/a/text()')
for x in title:
print(x)















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









