







一 理解归一化:
梯度的求导公式:

通过这个公式我们可以发现:theta j的梯度 与第j列的特征值相关,成正比。如果这一列的特征值约大,那么这一列的梯度就越大,梯度越大更新下降的就越快,越容易达到该方向的最优值。从下面的图中可以看出,theta2 的更新幅度比theta1要大。
注意:某个theta达到最优值后,并不不变化了,随着训练的进行,会发生震荡。震荡的产生又增加了训练的次数,为了减小这种现象。我们需要将训练样本进行归一化,来消除量纲不同的影响。

归一化方法:
min_max scaler 归一化:先处理异常值,
from sklearn.preprocessing import MinMaxScaler
import numpy as np
data=[[-1,2],[-0.5,6],[0,10],[1,18]]
# print(np.array(data))
minMax=MinMaxScaler()
transform_data=minMax.fit_transform(data)
print(transform_data)
# 数据预处理当模型来训练
minMax2=MinMaxScaler()
# 训练
minMax2.fit(data)
# 转化
print(minMax2.transform(data))
# 处理不在该范围的数据
print(minMax2.transform([[4,6]]))sard scaler 归一化:均值归一化数值会在[-1 1]这个范围; 标准归一化(代码...)
二 理解正则化:
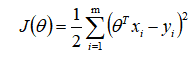



sklearn 房价预测案列:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor,Ridge
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
dataset = load_boston()
y = dataset.target
x = dataset.data
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=6)
sgd = SGDRegressor(max_iter=10000)
sgd.fit(x_train,y_train)
y_pred = sgd.predict(x_test)
print("mse:%s"%mean_squared_error(y_test,y_pred))
ridge = Ridge()
ridge.fit(x_train,y_train)
y_pred = ridge.predict(x_test)
print("mse:%s"%mean_squared_error(y_test,y_pred))
# 归一化数据后 再看MES
transformdata = MinMaxScaler().fit_transform(x)
x_train,x_test,y_train,y_test = train_test_split(transformdata,y,test_size=0.3,random_state=6)
sgd = SGDRegressor(max_iter=10000)
sgd.fit(x_train,y_train)
y_pred = sgd.predict(x_test)
print("mse:%s"%mean_squared_error(y_test,y_pred))
mse:8.272588593371536e+27
mse:29.035285983771672
mse:29.68675679206023














 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









