







 本文介绍了使用Scrapy框架创建项目和定义Item的过程,然后生成并修改了一个针对douban.com的爬虫。在抓取过程中遇到403Forbidden响应,通过修改请求头解决了问题。此外,文章还探讨了如何通过检查HTML结构实现页面翻页,以及提取页面数据的方法。
本文介绍了使用Scrapy框架创建项目和定义Item的过程,然后生成并修改了一个针对douban.com的爬虫。在抓取过程中遇到403Forbidden响应,通过修改请求头解决了问题。此外,文章还探讨了如何通过检查HTML结构实现页面翻页,以及提取页面数据的方法。
1 创建项目
scrapy startporject douban
2.修改模板 item.py
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
info = scrapy.Field()
score = scrapy.Field()
desc = scrapy.Field()
3. 生成一个爬虫
scrapy genspider movie douban.com

4.修改初始url
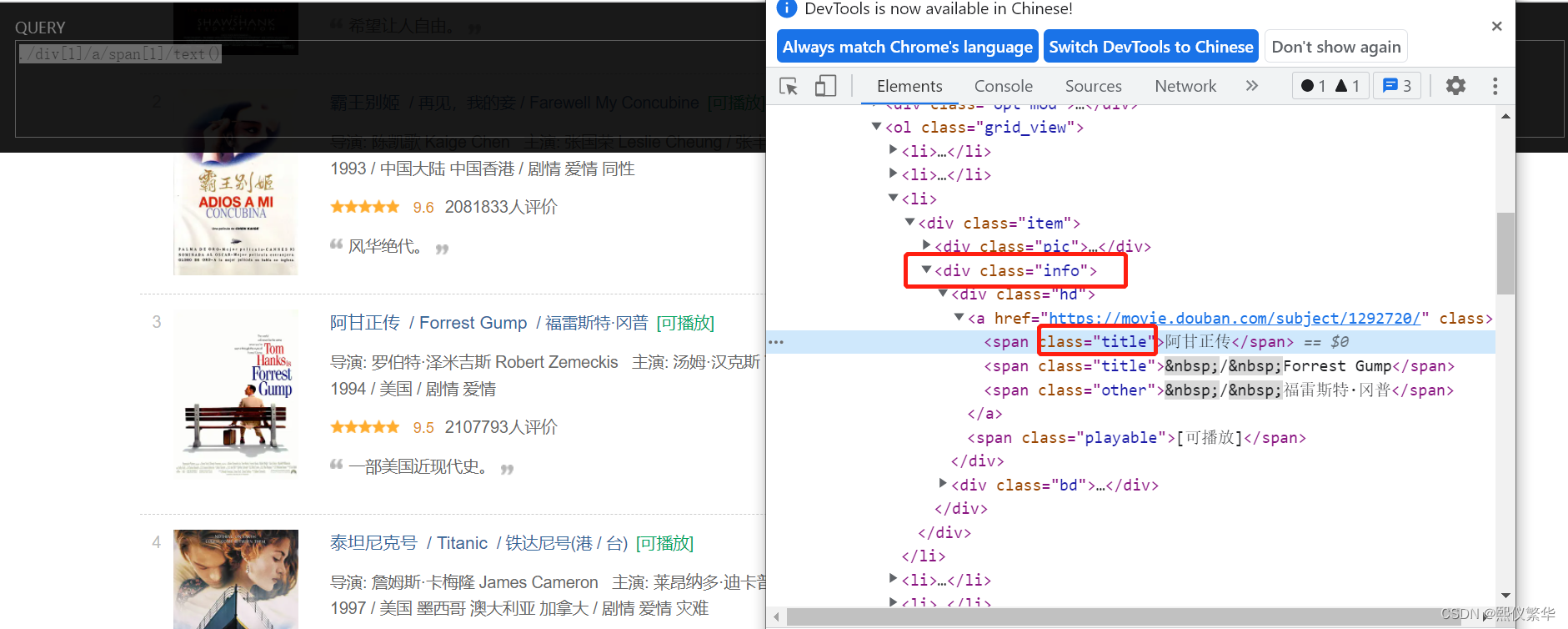
5. 提取相应中的所有节点
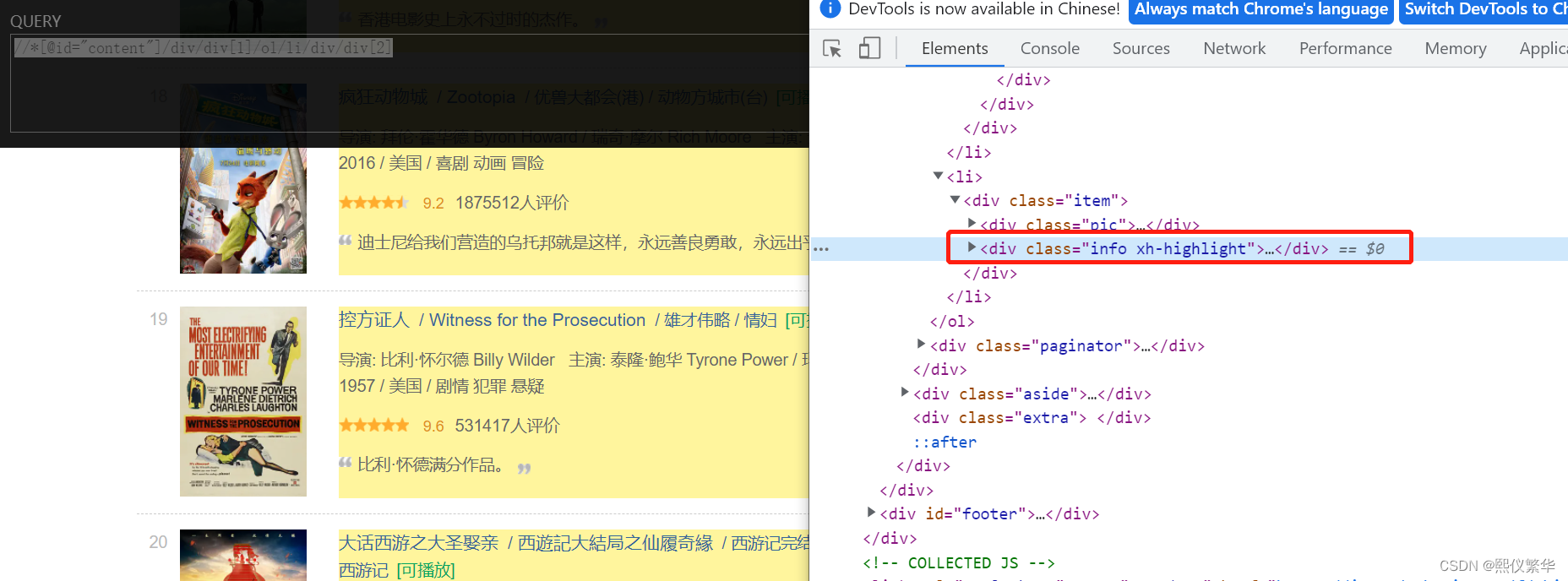
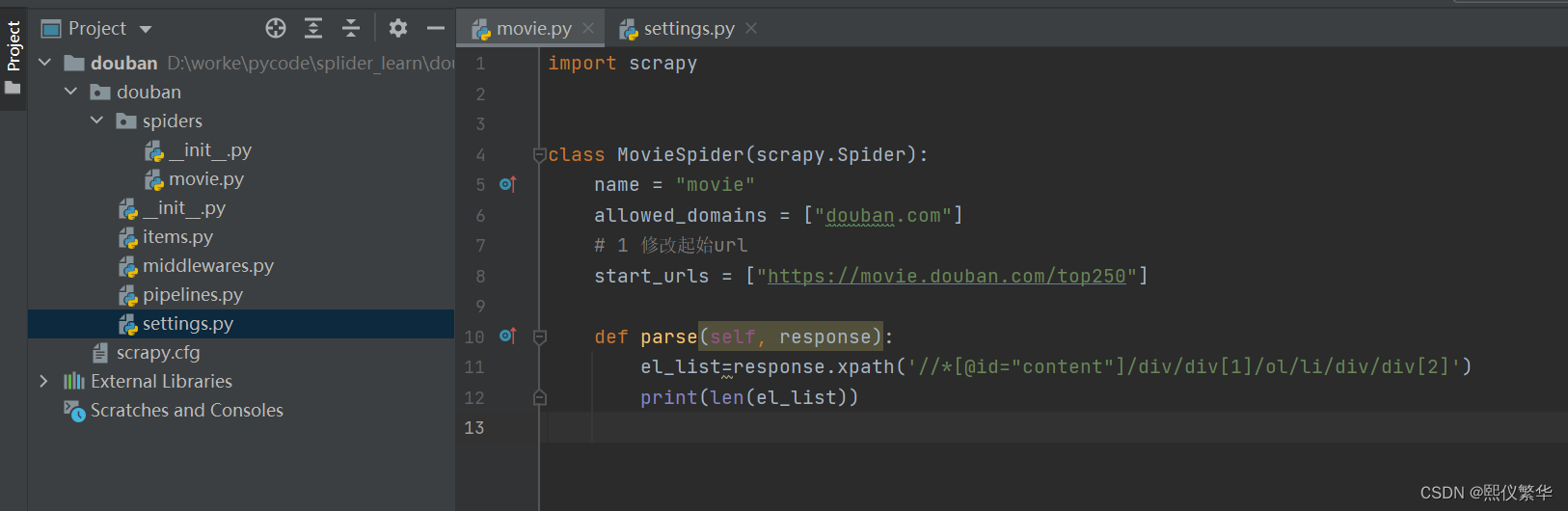
运行:

结果显示403:
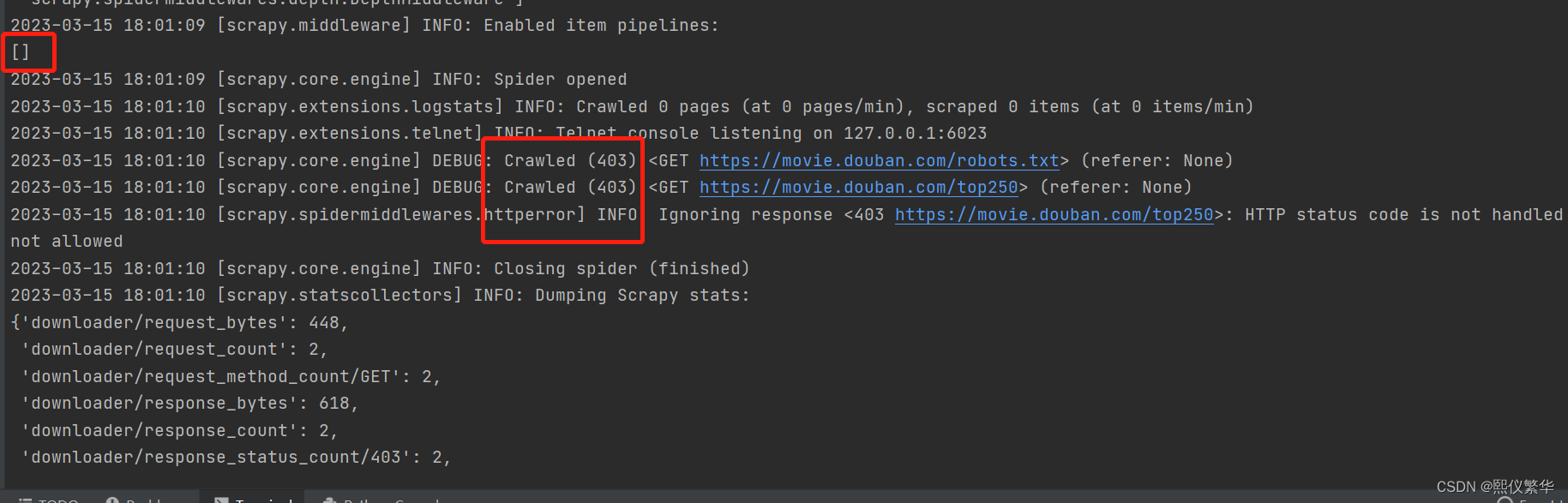
修改请求头:
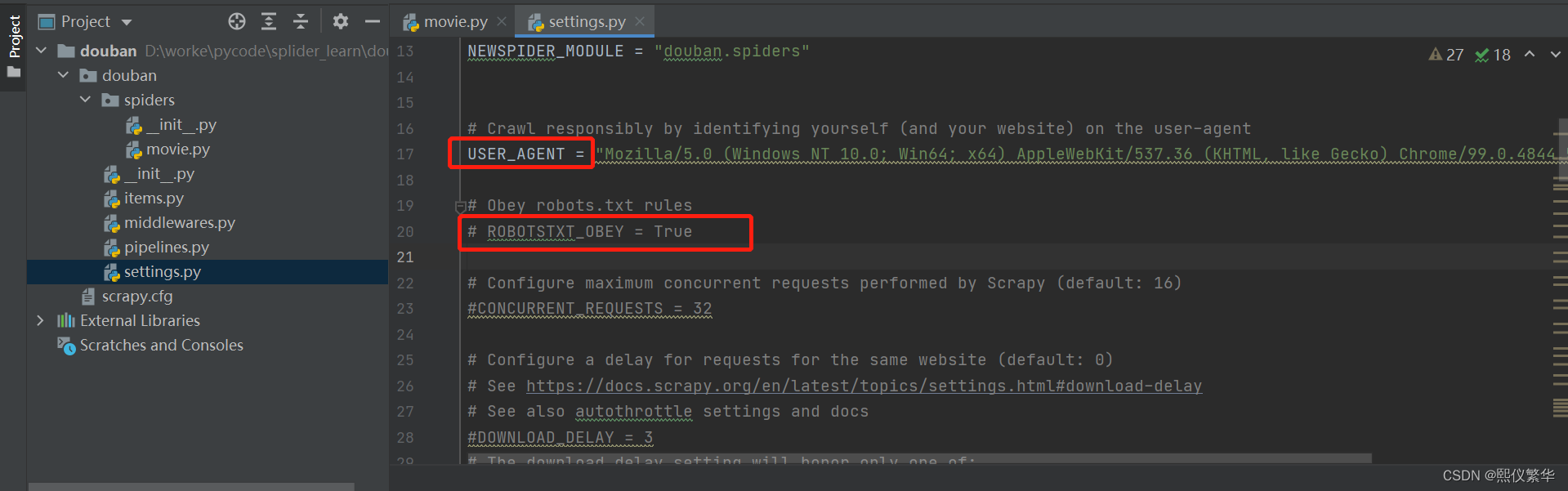
再次运行:

翻页实现
1.右键 检查
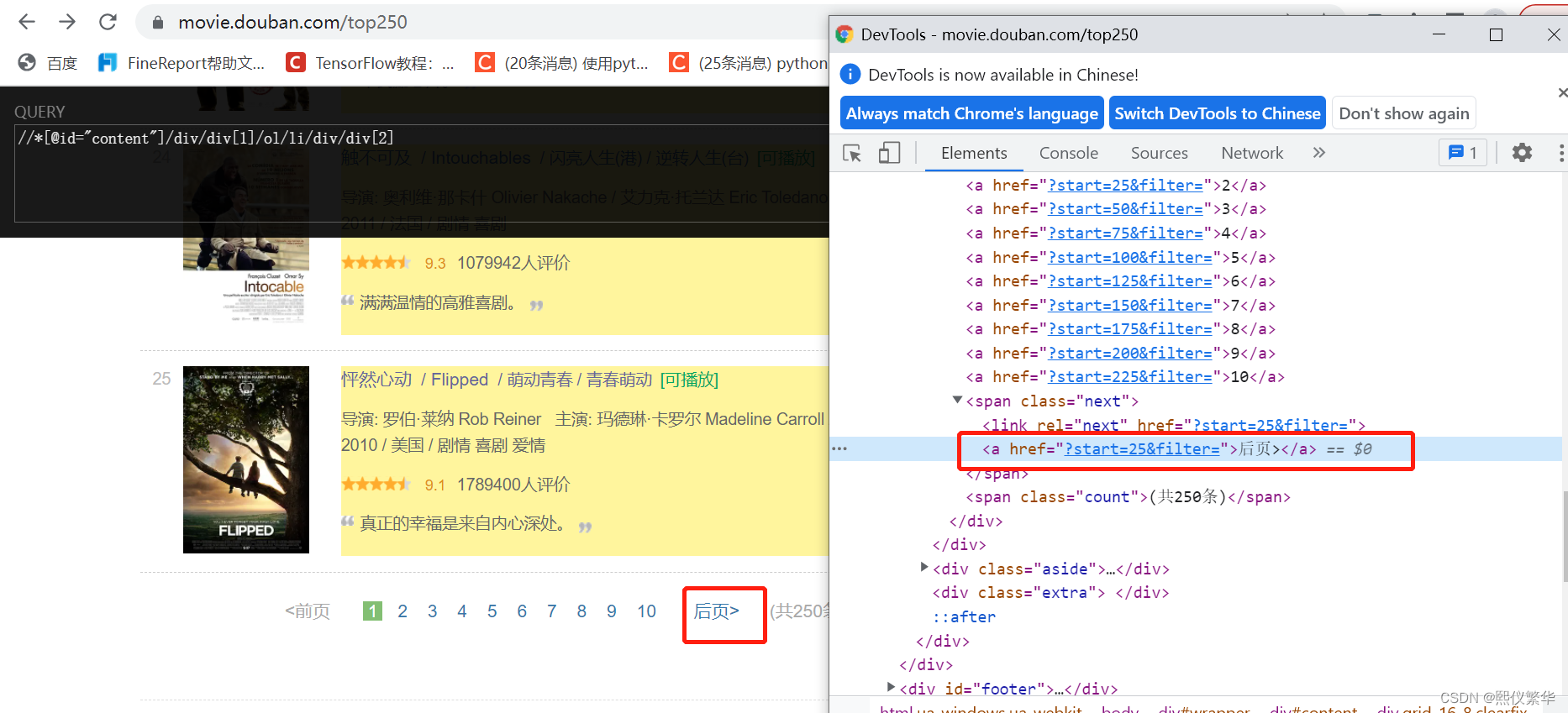
使用 span的class 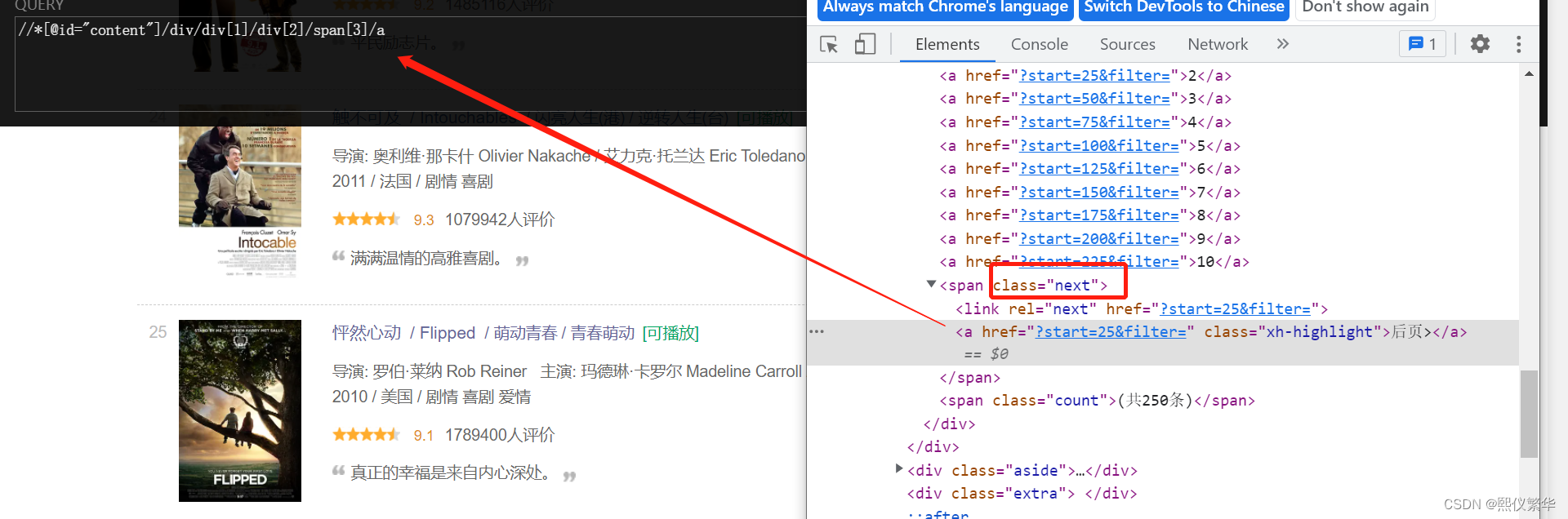
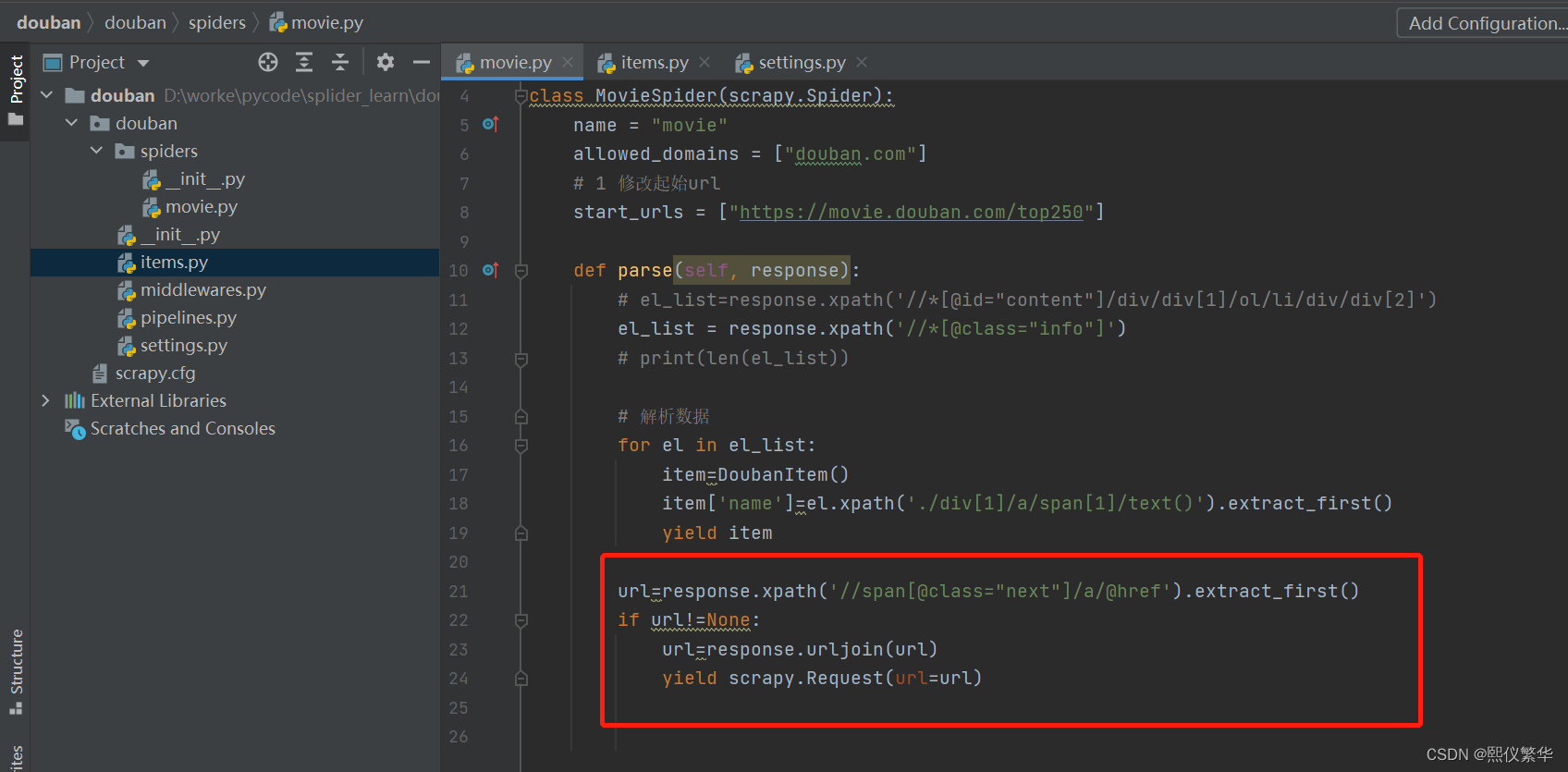
解析数据:

















 8635
8635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









