






 该教程详细介绍了如何在Windows11环境下,使用Vmware16.2.2版本安装Centos7,并配置静态网络,克隆虚拟机创建Hadoop集群。通过SSH免密登录和配置hosts文件,实现节点间的无密码访问。接着,文章详述了Hadoop2.7.4的安装和配置过程,包括环境变量设置、配置文件修改以及集群的启动和测试。
该教程详细介绍了如何在Windows11环境下,使用Vmware16.2.2版本安装Centos7,并配置静态网络,克隆虚拟机创建Hadoop集群。通过SSH免密登录和配置hosts文件,实现节点间的无密码访问。接着,文章详述了Hadoop2.7.4的安装和配置过程,包括环境变量设置、配置文件修改以及集群的启动和测试。
目录
一、前言
Hadoop是一个开源的、可运行与Linux集群上的分布式计算平台,本教程意图在Windows11平台使用Vmware虚拟机搭建一个伪分布式Hadoop运行环境,供学生进行Hadoop集群相关方面的学习、实验。
二、虚拟机的安装与配置
1.Vmware的安装
由于Vmware 15.x版本不兼容Windows11,请确保你的Vmware虚拟机版本高于16.0,否则会出现运行虚拟机时出现Device/Credential Guard的报错。VMware workstation v16.2.2 https://pan.baidu.com/s/1Odk-CjAiPSryYa6IIi5VaQ?pwd=XALA
https://pan.baidu.com/s/1Odk-CjAiPSryYa6IIi5VaQ?pwd=XALA
2.在虚拟机中安装Centos
下载Centos镜像
CentOS-7-x86_64-DVD-2207-02.isohttps://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2207-02.iso请确保你的磁盘中有10GB以上空闲空间!
在虚拟机中安装Centos:
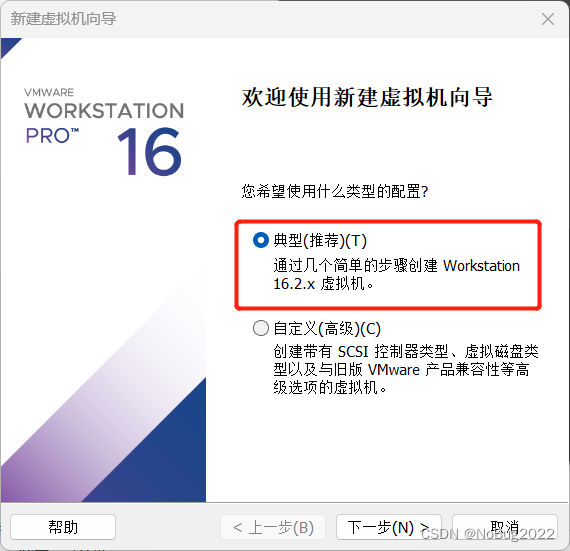
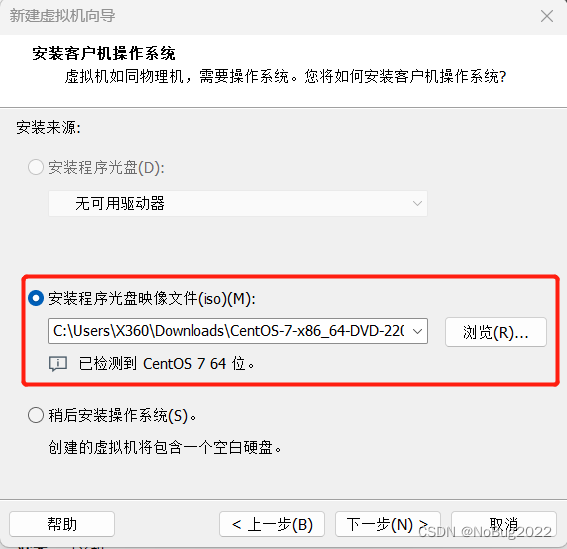
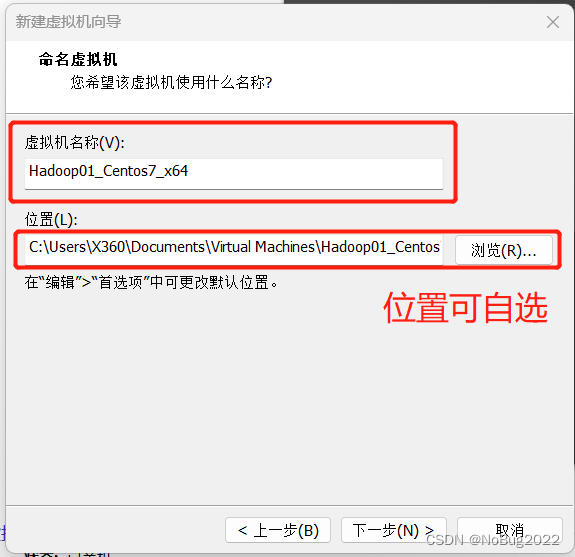
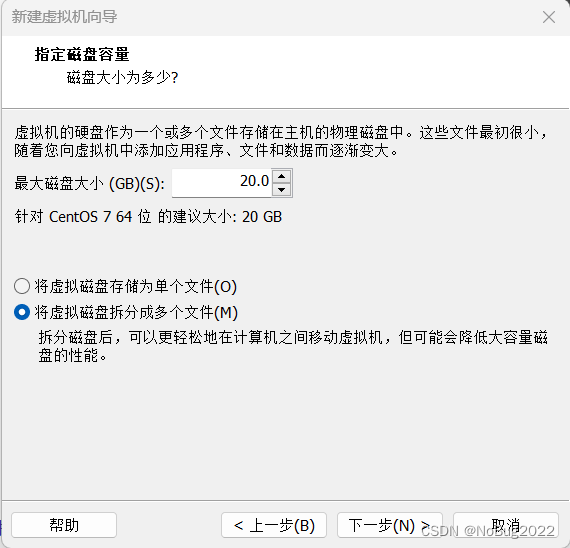
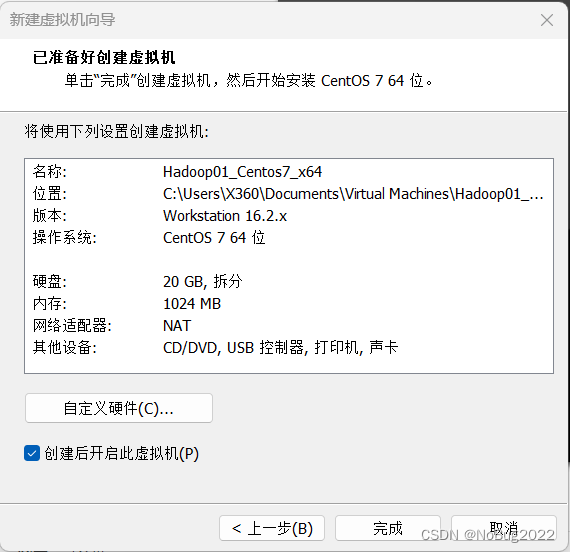
经测试,上述配置可以运行Hadoop的Demo测试,如果你的任务需要更多资源,后续可分配更多的CPU和内存(如果有)给虚拟机。
Centos的安装
创建虚拟机后,点击完成,虚拟机自动启动。
启动中,请忽略此提示:
进入虚拟机中,利用方向键选中Install Centos 7,回车安装:
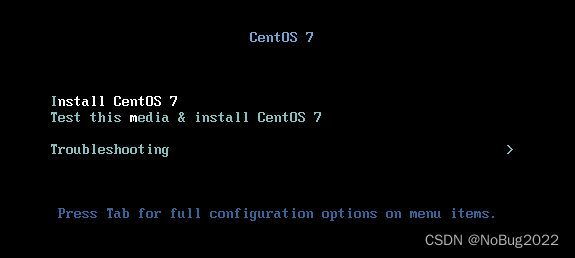
等待片刻。
选择中文,继续。
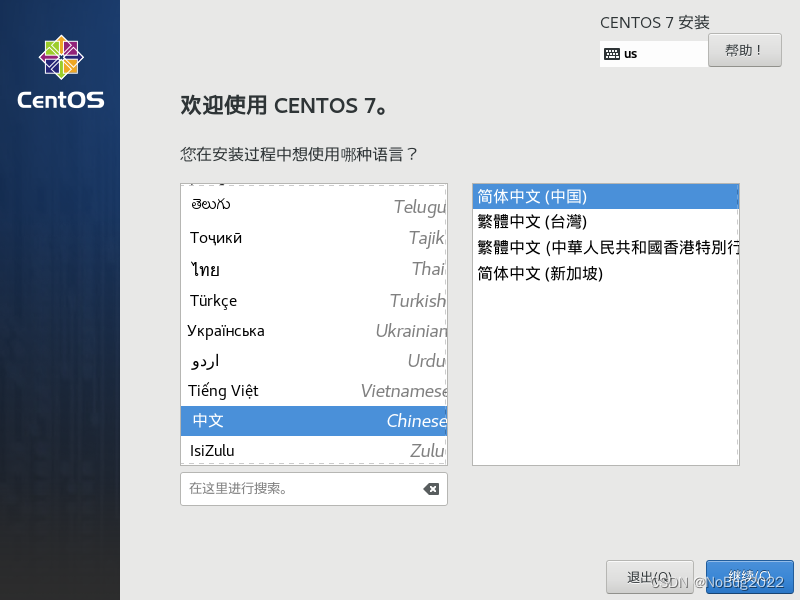
稍等片刻。
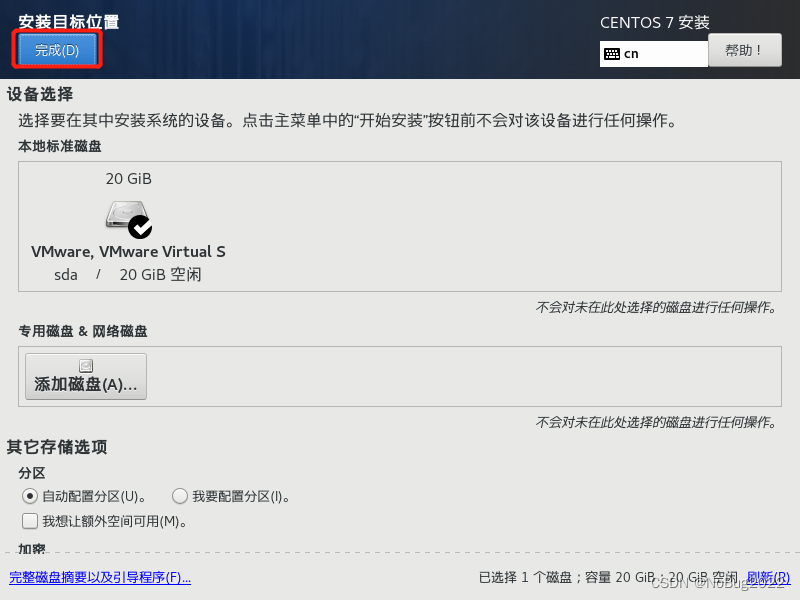
选择安装位置
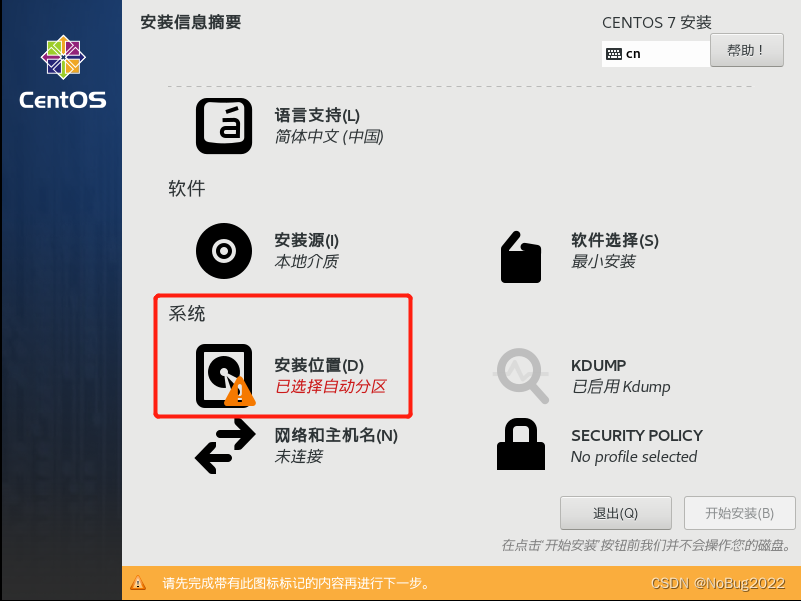
点击完成。
选择网络和主机名
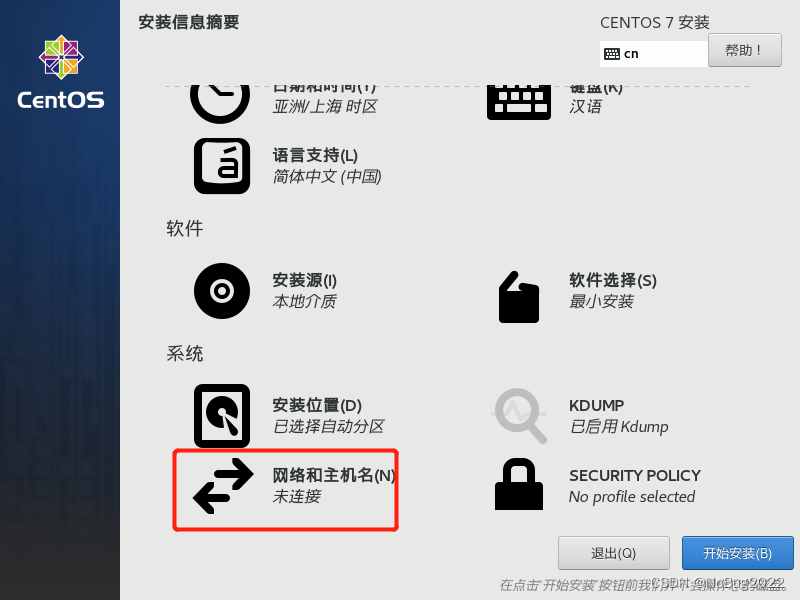
打开网卡,更改主机名。
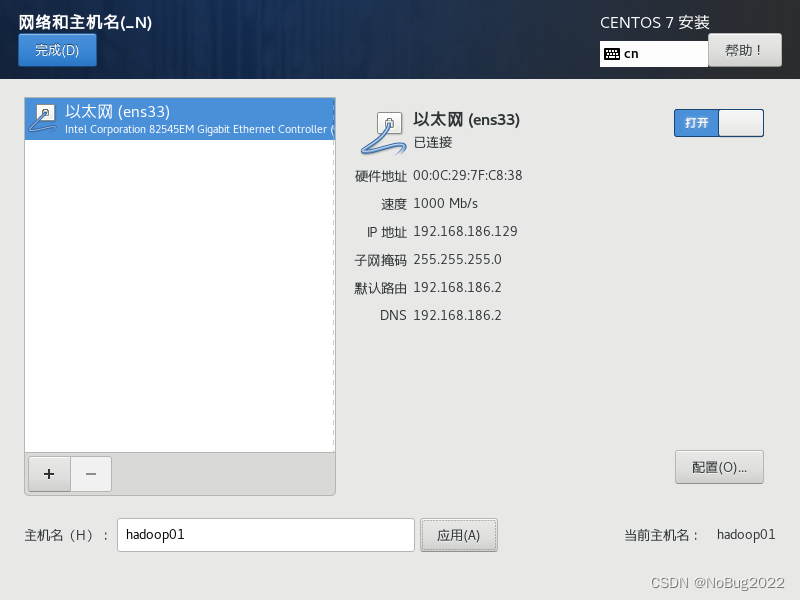
请记住上述信息:
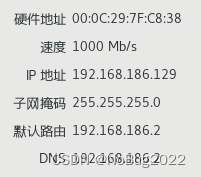
完成。
开始安装。
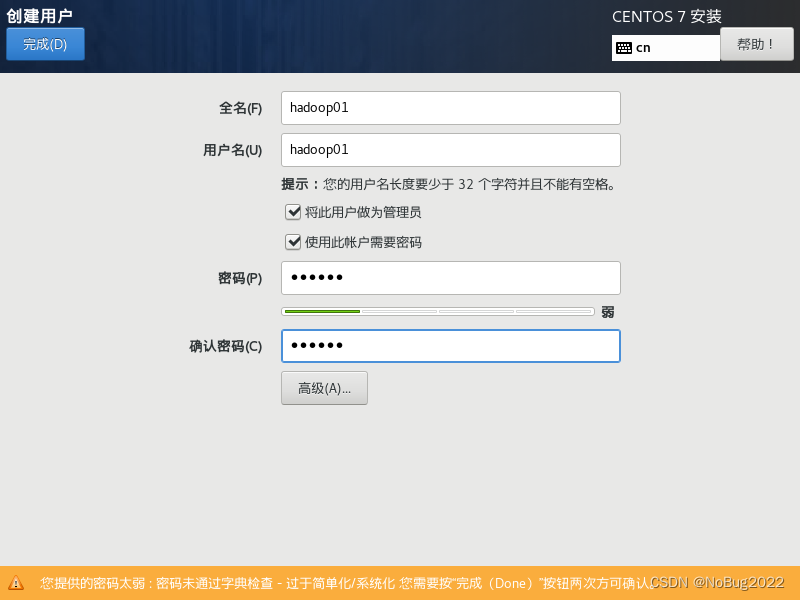
设置root密码和账户。

设置root密码,一定要记住root密码。
设置账户,取名为hadoop01
漫长的等待。
这个时候我们可以提前将hadoop、jdk、xshell、xftp下载好。
Toolshttps://pan.baidu.com/s/11sqkOS4pidiR6Me1ioQj5g?pwd=b4oe#list/path=%2Fhadoop自行安装xshell、xftp在Windows上,如果提示更新,点击确定。
这时Centos也差不多安装好了。
安装结束,点击重启。
使用Xshell登录root账户
使用Xshell进行设置是因为它可以很方便的粘贴命令到终端
还记得刚才的网卡连接信息吗?
打开Xshell,新建一个会话
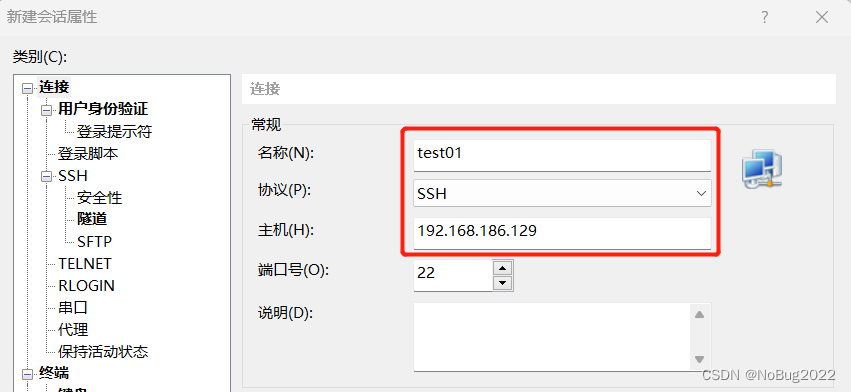
按照如下配置,主机填写刚才图片中的IP地址
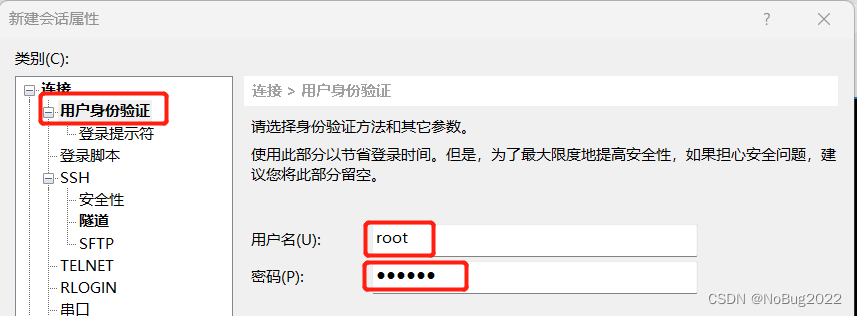
用户名root,密码为你刚才设置的root密码。
确定后,双击连接。
接受并保存。
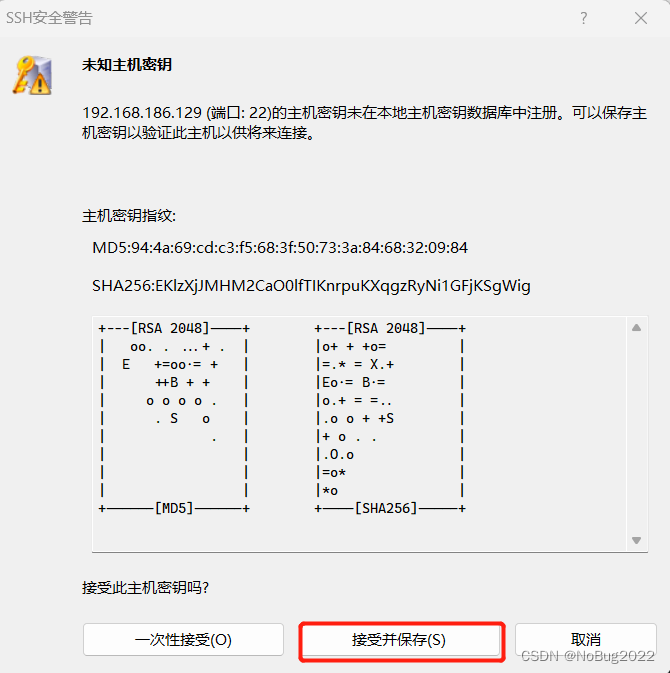
三、静态网络配置
Xshell可直接粘贴文本内容进入终端(右键或shift + insert)
测试网络状态
ping baidu.com -c 4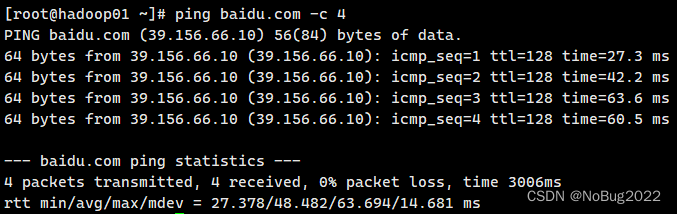
安装net-tools
yum upgrade yum install net-tools一直y下去安装,稍等片刻。
查看Mac地址
ifconfig如果提示没有这个命令,可能因为net-tools没安装,请重新安装。
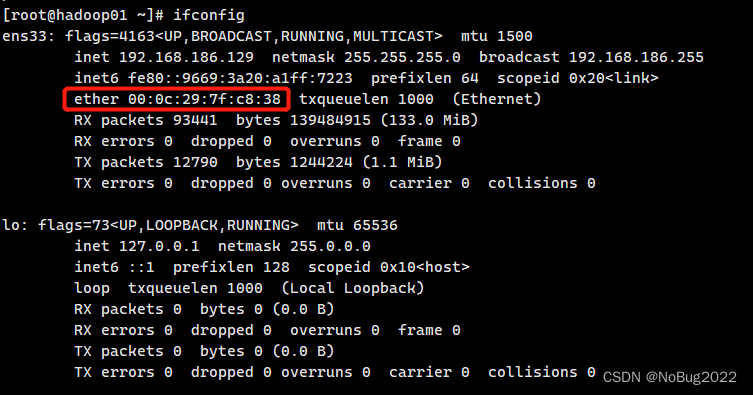
ether后的就是mac地址,可以复制保存。
安装nano
yum install nano使用nano编辑器因为他比vi更加易用,nano保存只需crtl+x y 然后回车。
查看可用ip范围
回到Vmware中,打开虚拟网络编辑器。
选择更改设置
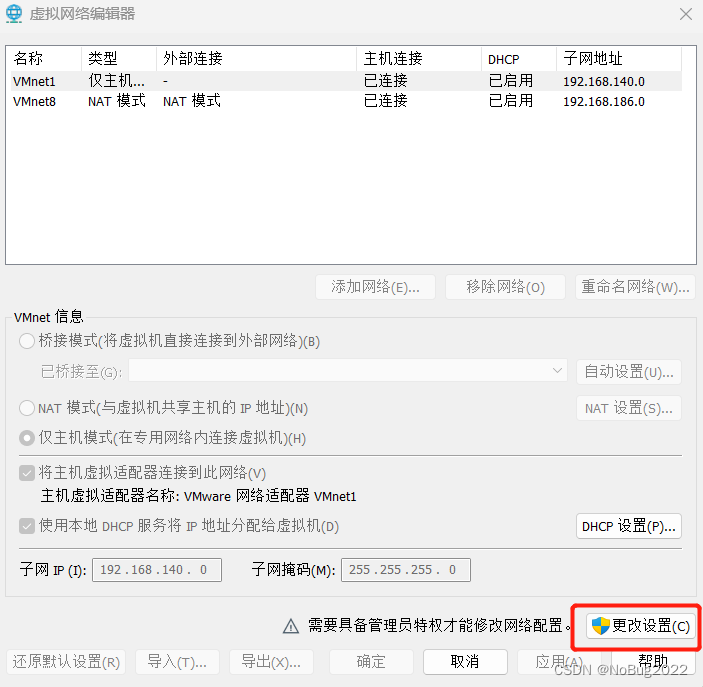
查看NAT模式网卡状态,点击DHCP设置。
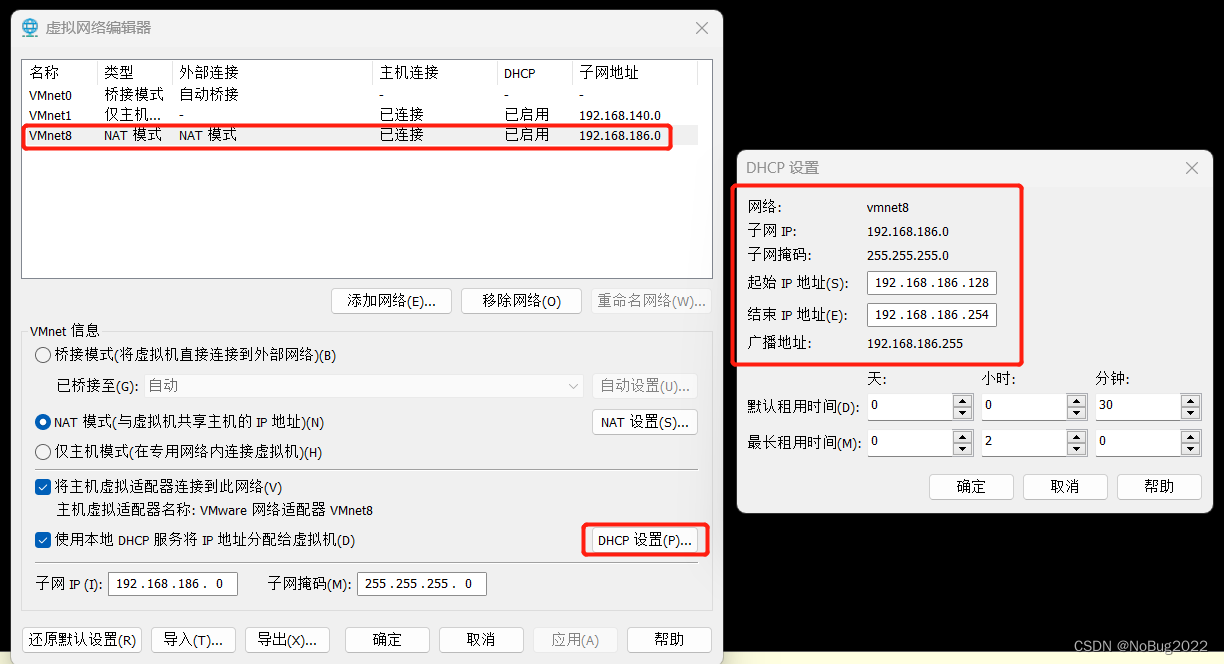
记住起始ip地址。
修改网络配置文件
nano /etc/sysconfig/network-scripts/ifcfg-ens33- 将BOOTPROTO设置为STATIC
- 新增 WADDR 为刚才复制的ether值(mac地址)
- 新增 IPADDR 为自己指定的IP地址,ip地址必须在起始和结束的范围内自行选择,不可重复
- 新增 GATEWAY 为网关的值,通常为先前记录的ip地址,最后一位改成2(如192.168.186.2)
- 新增 NETMASK 为255.255.255.0
- 新增 DNS1为8.8.8.8
- 修改模板如下所示:
BOOTPROTO="static"
WADDR="00:0c:29:7f:c8:38"
IPADDR="192.168.186.129"
GATEWAY="192.168.186.2"
NETMASK="255.255.255.0"
DNS1="8.8.8.8"修改前:
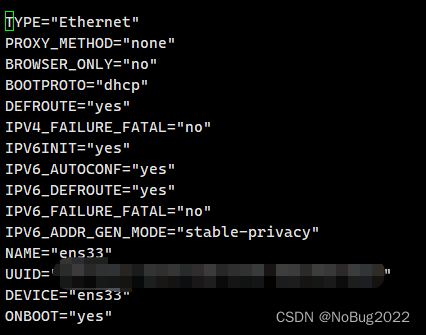
修改后:

WADDR为网卡的MAC地址,IPADDR为自己指定的IP,切记只修改红框内的数据!
重启网络服务
systemctl restart network
ping www.baidu.com
如果此时Xshell断开了连接,请检查是否配置出错,或者指派的IP与之前不同。
如果配置出错,请直接从虚拟机窗口配置,恢复正常后再使用xshell.
如果指派的IP与之前不同,请修改该xshell连接的ip地址!
重启虚拟机后,查看是否连通网络(ip地址并未改变,且能连通网络)
reboot
重新连接终端
ifconfig
ping www.baidu.com -c 4
四、虚拟机克隆
首先关闭虚拟机
shutdown now右键虚拟机,选择克隆。
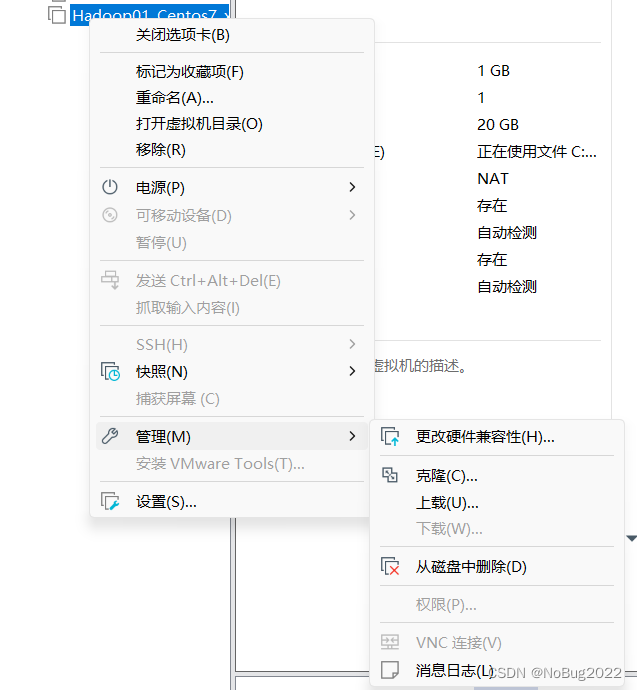
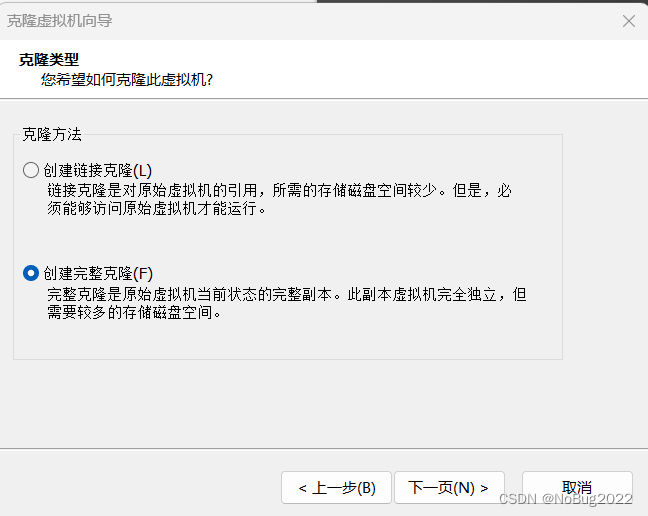
创建完整克隆
修改名称为hadoop02
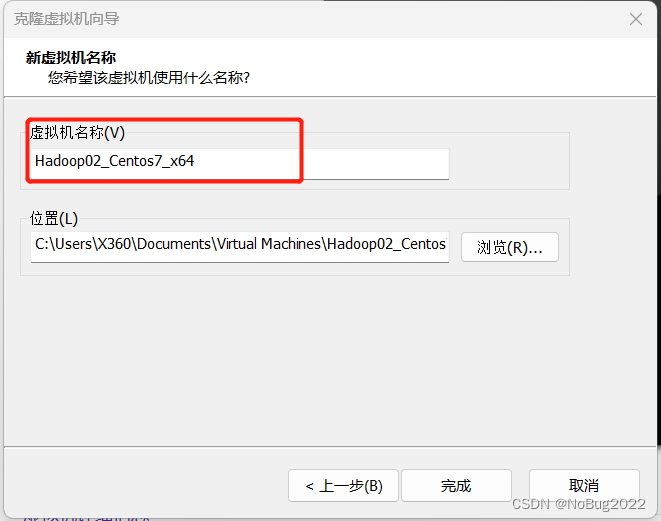
以下内容直接在虚拟机窗口进行
开启Hadoop02,登录root账户(不要用数字小键盘)
修改主机名
hostnamectl set-hostname hadoop02
reboot
(忘记截图了)
查看ip,mac地址
ifconfig
知道IP地址和mac地址了,我们按照之前的方式使用在虚拟机窗口配置静态网络!
要注意,请记录为主机分配的ip地址,不可重复!
教程中设置的ip为:
- hadoop01 192.168.186.129
- hadoop02 192.168.186.130
- hadoop03 192.168.186.131
重新启动网络配置、测试
systemctl restart network
ping www.baidu.com -c 4
按照上述内容自行复制出主机Hadoop03
当然,你也可以尽可能多的克隆主机(如果你有这样的需求),当然,三台主机已经够用了!
最终结果应如图所示:确保Xshell可以连接到每一台主机,并且每一台主机都可以ping通 baidu.com
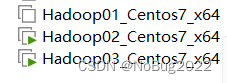

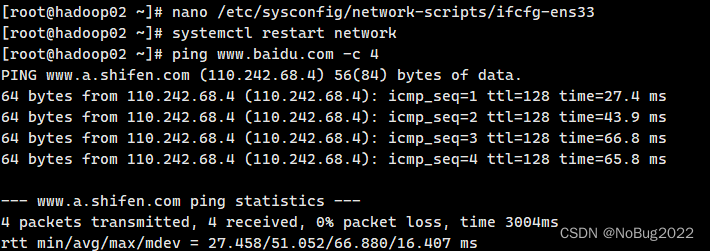
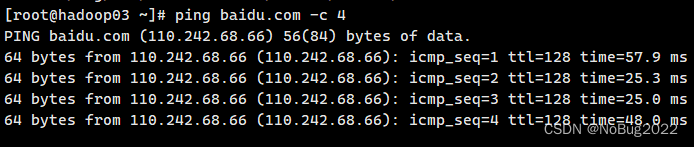
五、配置hosts文件和ssh免密登录
将所有虚拟机开机,并使用Xshell进行连接
修改hosts配置文件(所有虚拟机)
nano /etc/hosts192.168.186.129 hadoop01
192.168.186.130 hadoop02
192.168.186.131 hadoop03 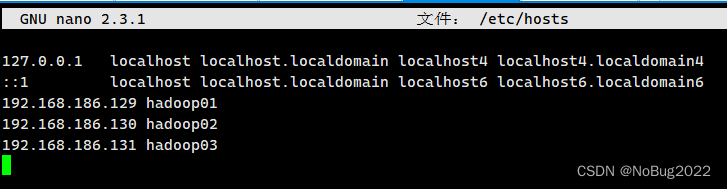
你可以在通过xshell直接复制进去,这样很方便。
生成密钥文件(所有虚拟机)
ssh-keygen -t rsa一直按回车就好
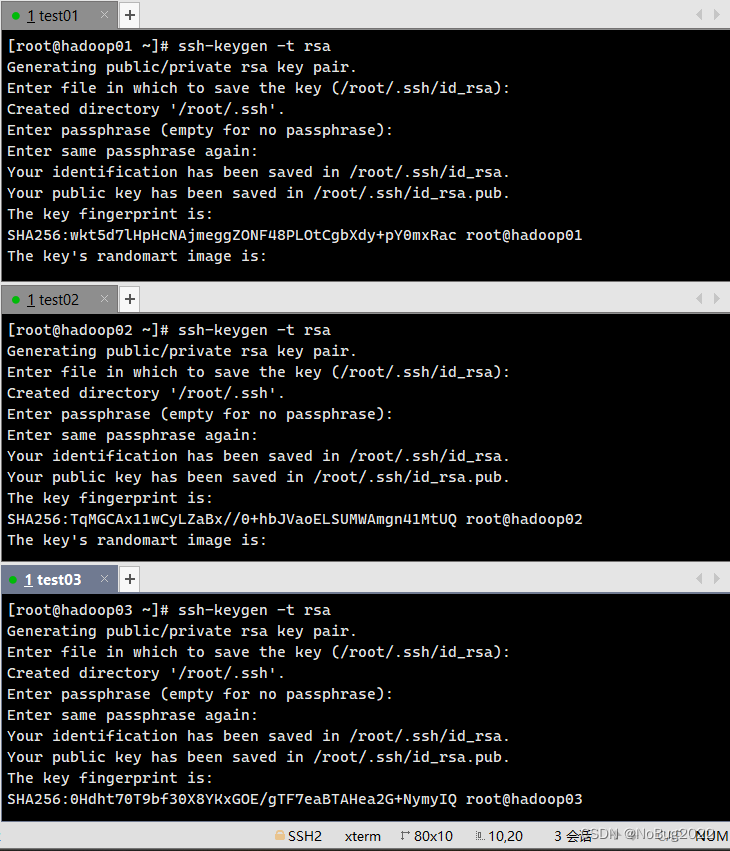
将本机公钥文件复制到其它虚拟机(所有虚拟机)
依次在终端中执行下列操作,每条指令执行后输入yes,在输入对应虚拟机密码。
ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop03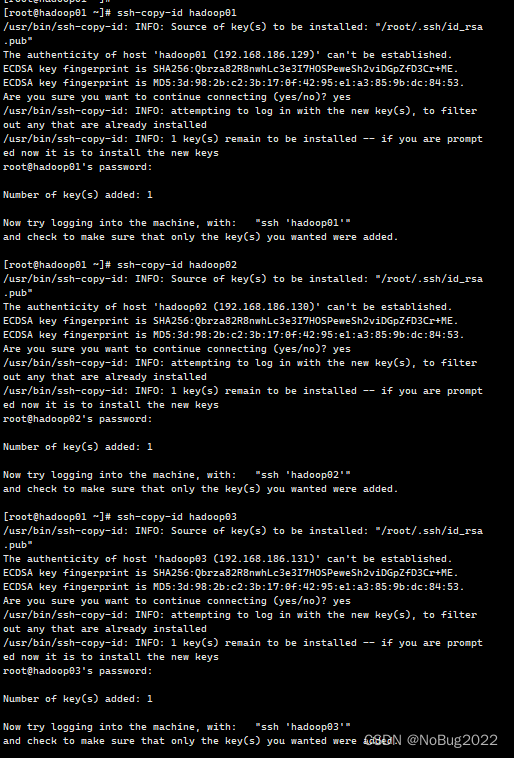
查看是否成功免密登录(所有虚拟机)
ssh hadoop02exit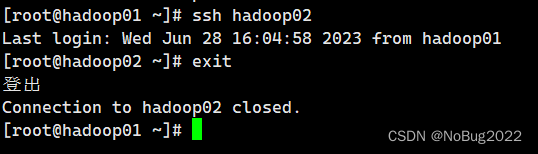
六、Hadoop集群配置
在所有虚拟机根目录下新建文件夹export,export文件夹中新建data、servers和software文件
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software准备安装包(前面已经给出下载链接)
- hadoop-2.7.4.tar.gz
- jdk-8u161-linux-x64.tar.gz
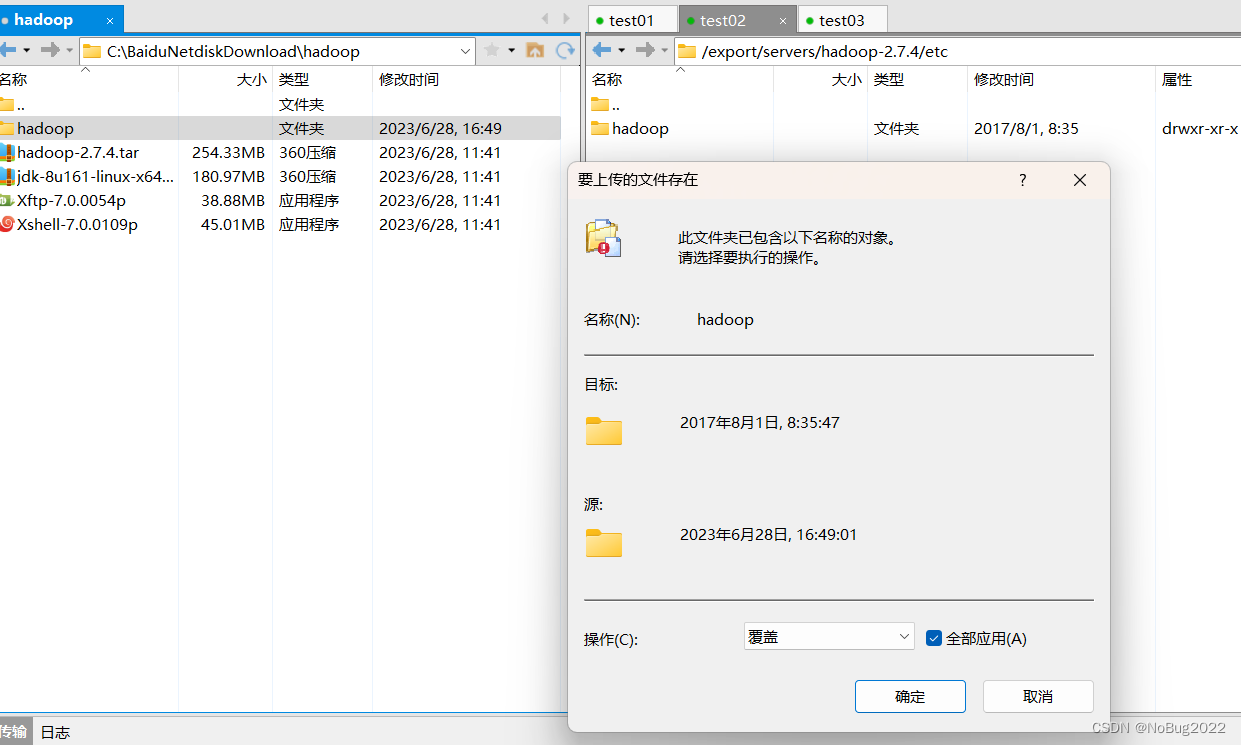
使用xftp将安装包复制进 /export/software目录下(所有虚拟机)
选中某一个窗口,按ctrl+alf+f召唤xftp,建立与对应主机的ftp连接
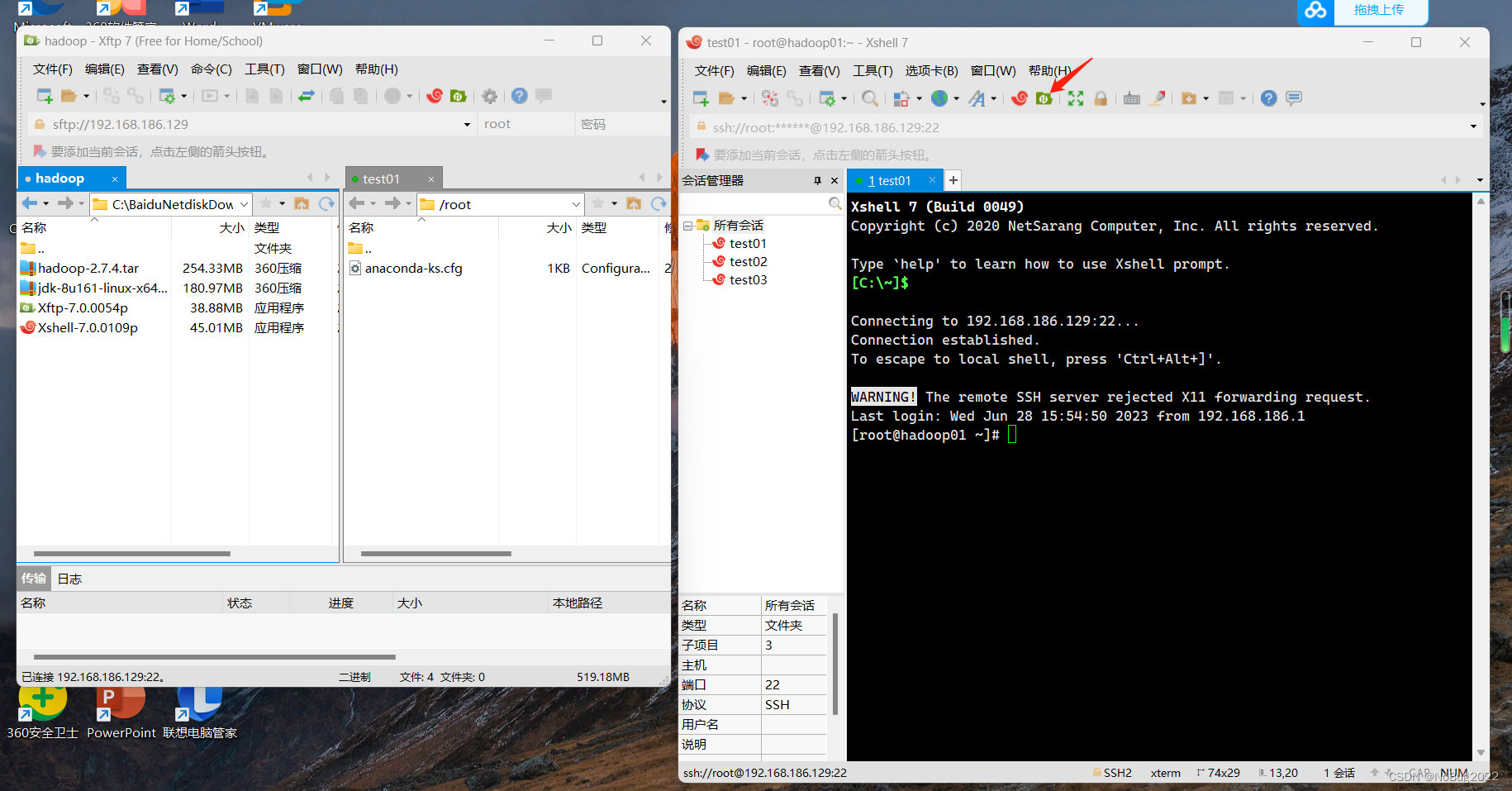
找到/export/software目录,直接把需要安装的软件拖进去(所有虚拟机)
等待上传结束
安装JDK(所有虚拟机)
解压
cd /export/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
重命名
cd /export/servers
mv jdk1.8.0_161 jdk
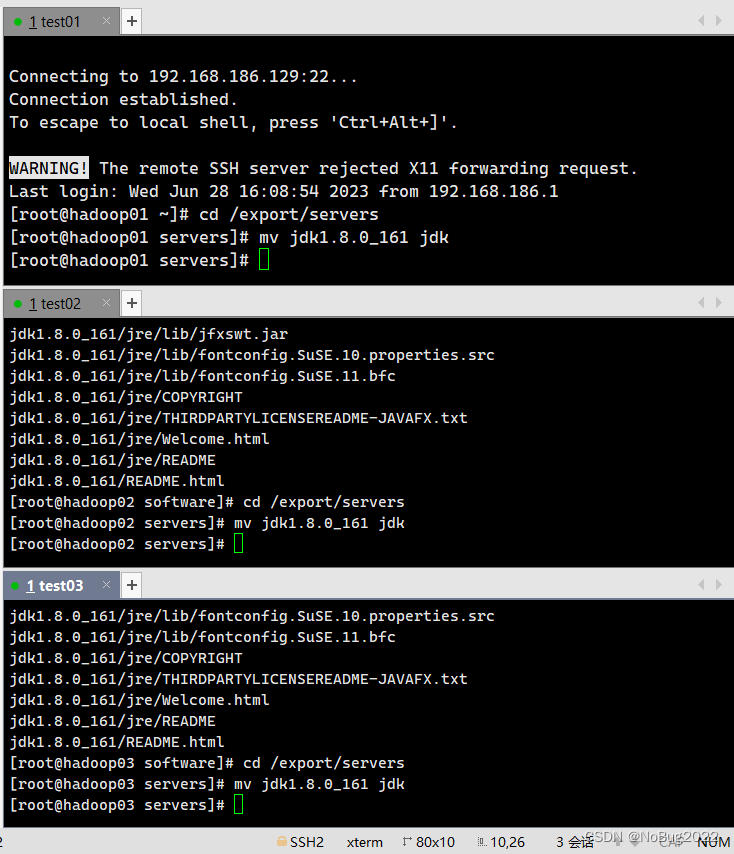
配置环境变量
nano /etc/profile
在文件最后追加
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使配置文件生效
source /etc/profile查看是否生效
java -version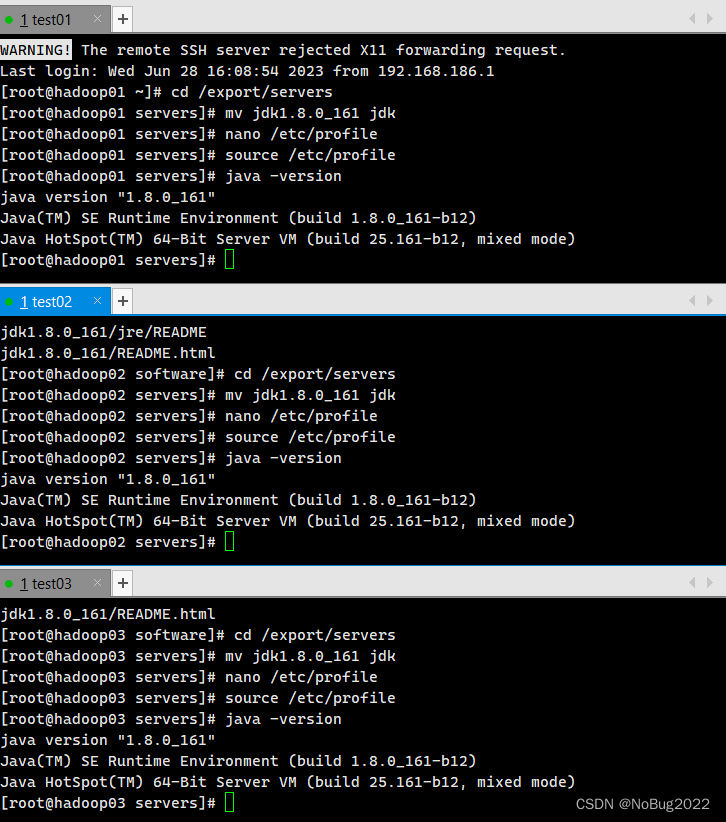
安装hadoop2.7.4(所有虚拟机)
解压安装包
cd /export/software
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
打开配置文件
nano /etc/profile
在文件末尾追加(图略)
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin使配置文件生效
source /etc/profile
查看是否配置成功
hadoop version
Hadoop集群配置 (先在本地修改,然后将修改后的文件复制到三台虚拟机)
我们配置hadoop01为主节点,hadoop02、hadoop03为子节点
使用xftp,进入hadoop01的/export/servers/hadoop-2.7.4/etc/hadoop/目录
直接将远程主机的hadoop文件夹拖到本地
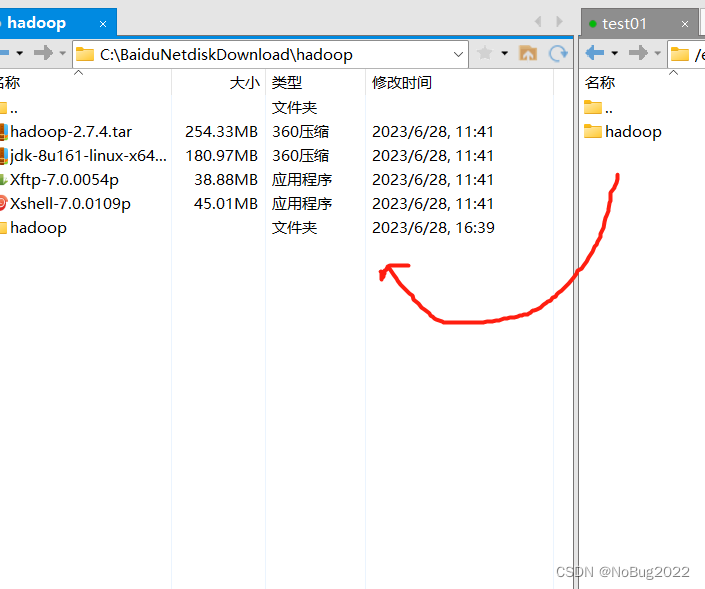
打开文件夹,直接在windows本地修改文件(推荐使用记事本)
修改hadoop-env.sh文件
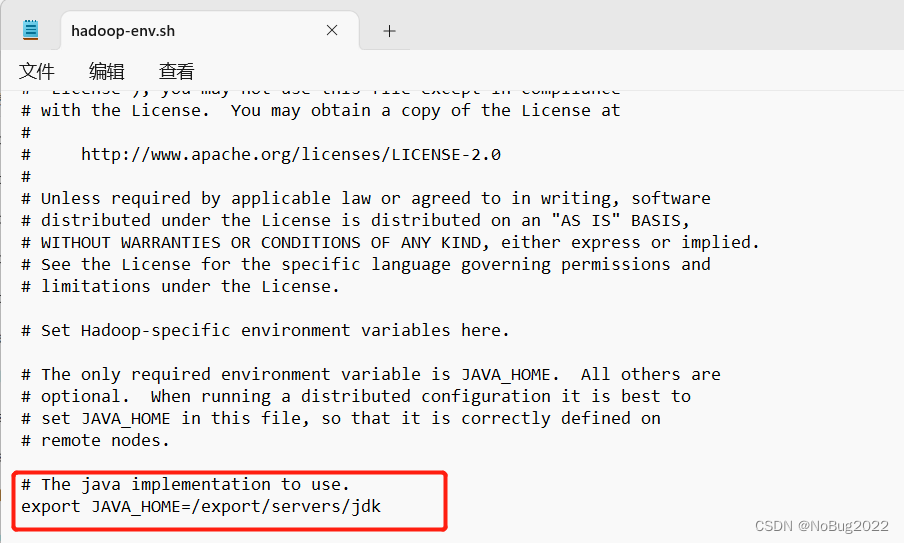
修改为
export JAVA_HOME=/export/servers/jdk修改core-site.xml文件
全部替换为
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://hadoop01:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tem/hadoop-${user.name}-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>修改hdfs-site.xml文件
全部替换为
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>修改mapred-site.xml文件
![]()
将mapred-site.xml.template复制一份副本,然后重命名为mapred-site.xml
将mapred-site.xml覆盖为
<configuration>
<!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml
覆盖为:
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves文件
覆盖为:
hadoop01
hadoop02
hadoop03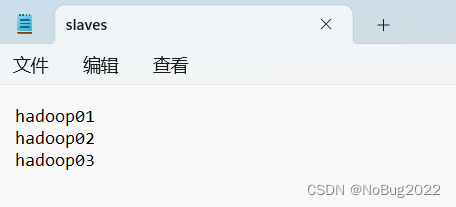
将修改好的文件覆盖到三台虚拟机
在hadoop01中执行
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile在hadoop02 03中执行
source /etc/profile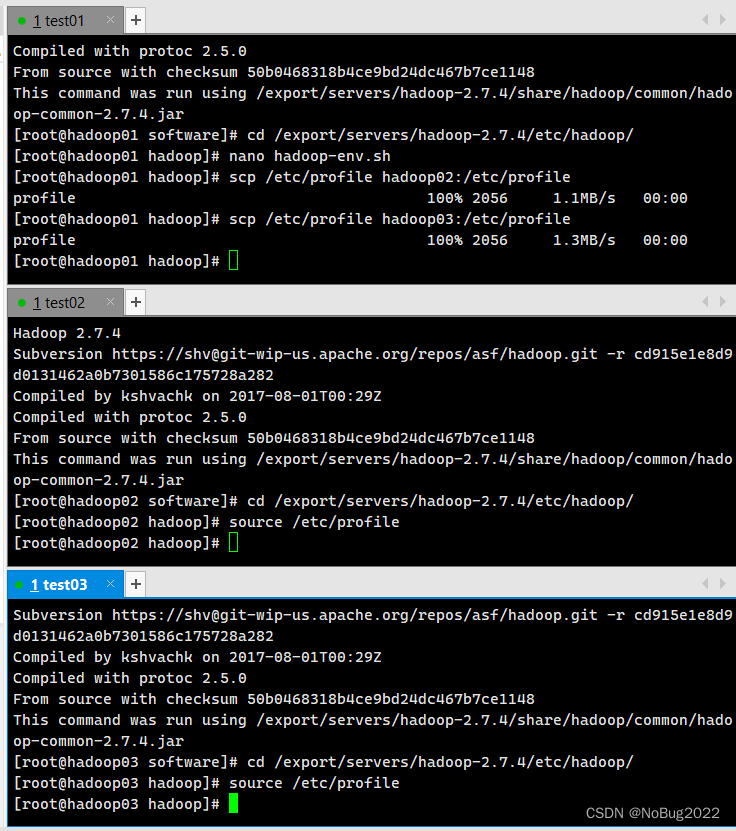
在hadoop01格式化hdfs
hdfs namenode -format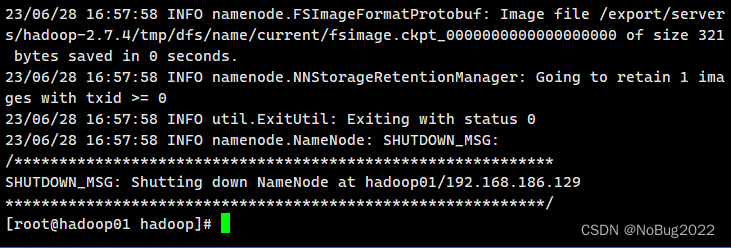
七、Hadoop集群测试
在主节点hadoop01启动HDFS
start-dfs.sh在主节点hadoop01启动yarn
start-yarn.sh使用jps命令查看进程
jps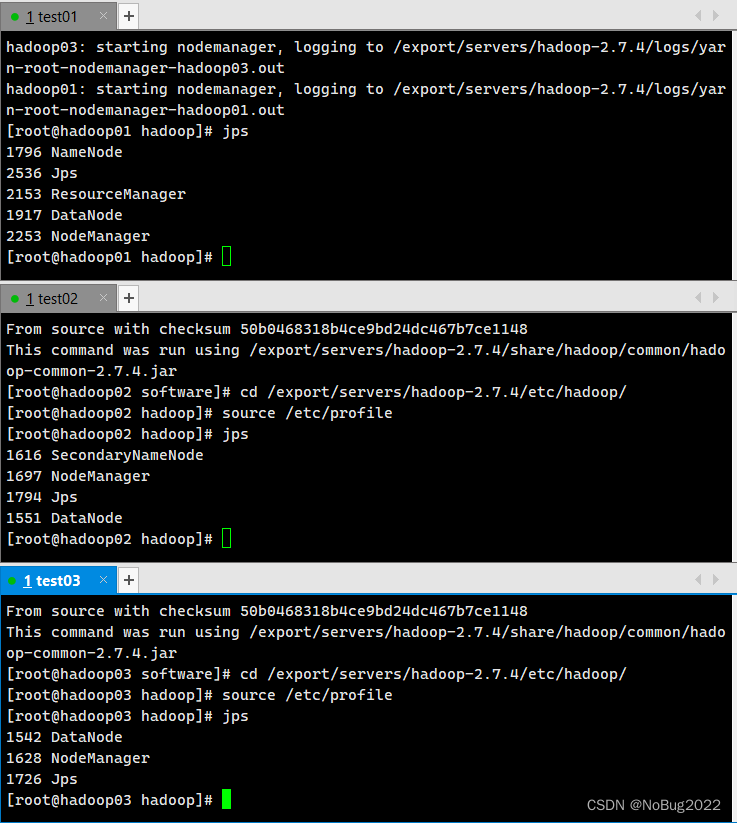
大功告成,现在你可以使用Hadoop平台进行大数据分析了!
运行DEMO
在主节点执行词频统计DEMO
mkdir ~/tmp
echo 'In the physical sciences, progress in understanding large complex systems has often come by approximating their constituents with random variables; for example, statistical physics and thermodynamics are based in this paradigm. Since modern neural networks are undeniably large complex systems, it is natural to consider what insights can be gained by approximating their parameters with random variables. Moreover, such random configurations play at least two privileged roles in neural networks: they define the initial loss surface for optimization, and they are closely related to random feature and kernel methods. Therefore it is not surprising that random neural networks have attracted significant attention in the literature over the years' > ~/tmp/word1.txt
echo 'Throughout this work we will be relying on a number of basic concepts from random matrix theory. Here we provide a lightning overview of the essentials, but refer the reader to the more pedagogical literature for background' > ~/tmp/word2.txt
hdfs dfs -mkdir /input
hdfs dfs -put ~/tmp/word*.txt /input
hadoop jar /export/servers/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /input output
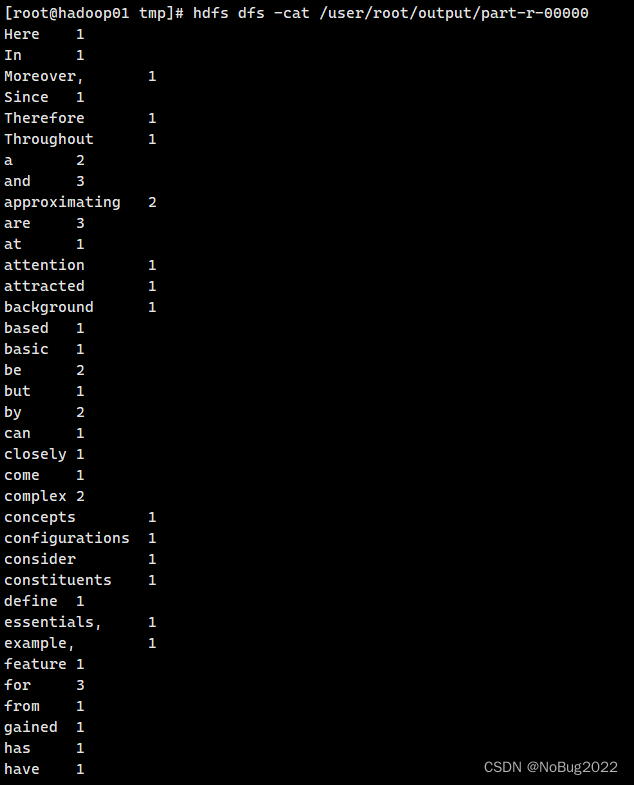
hdfs dfs -cat /user/root/output/part-r-00000
恭喜你,你已经成功搭建Hadoop环境!请展开下一步的探索吧!

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









