







Replication Manager 管理多集群
1.Replication Manager最新版本下载安装
##下载地址
vi /etc/yum.repos.d/signal18.repo
[signal18]
name=Signal18 repositories
baseurl=http://repo.signal18.io/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
yum install replication-manager-osc --downloadonly --downloaddir=/opt/
cd /opt
rpm -ivh replication-manager-osc-.2.2.25-1.x86_64.rpm
2. 后端DB集群的Master节点创建用户并授权
#修改本地root密码
alter user root@'localhost' identified with mysql_native_password by '123';
#创建复制用户
create user 'repuser'@'172.31.0.%' identified with mysql_native_password by 'repuser123';
grant replication slave on *.* to 'repuser'@'172.31.0.%';
#创建replication_manager管理用户
create user 'manager'@'172.31.0.%' identified with mysql_native_password by 'manager123';
grant select,reload,process,super,replication slave,replication client on *.* to 'manager'@'172.31.0.%';
3. 编辑全局配置文件
全局配置文件中配置的参数,会对 include 参数设置的路径下的所有 .toml 文件生效
vim /etc/replication-manager/config.toml
[Default]
include = "/etc/replication-manager/cluster.d" #所有集群配置文件的目录,该参数必须设置
monitoring-save-config = false
log-file = "/var/log/replication-manager.log"
log-level = 3 #1-7,>3会非常详细,仅用于调试
log-rotate-max-age = 7 #保存7天的日志
monitoring-datadir = "/var/lib/replication-manager" #一些监控文件的保存路径,会以集群名在该路径下创建目录
db-servers-connect-timeout = 5 #数据库连接超时时间(以秒为单位)。如果在该值之前无法建立连接,服务器将超时。
db-servers-read-timeout = 10 #数据库 I/O 读取超时(以秒为单位)。 如果在已经建立的连接上,在等于该选项值的时间段内没有收到数据,服务器将超时。
##########
## HTTP ##
##########
http-server = true
http-bind-address = "0.0.0.0"
http-port = "10001"
http-auth = false
http-session-lifetime = 3600
http-bootstrap-button = false
http-refresh-interval = 4000
##############
## FAILOVER ##
##############
failover-at-sync = true #仅当状态半同步为最后状态同步时才进行故障转移。配合半同步使用,保证切换时数据不丢失
failover-max-slave-delay = 0 #切换选主时,如果从库延时大于此值,则不进行切换
failover-limit = 0 #故障转移的最大次数,超过此值则不再进行故障转移,0表示无限制
failover-mode = "automatic" #故障转移模式为自动,想要手动使用参数"manual"
failover-readonly-state = true #故障转移后重新构建的主从关系,将从库设置为只读
failover-falsepositive-ping-counter=5 #5次ping探活失败后进行failover
failover-falsepositive-heartbeat = true #如果一个从站仍然可以从主站获取事件,则取消故障转移。
failover-falsepositive-heartbeat-timeout = 2 #心跳检测的超时时间
failover-time-limit=0 #该值时间(秒)内再次发生故障不切换,防止硬件问题或网络问题,默认值0
#########
## API ##
#########
api-credentials = "admin:repman"
api-port = "10005"
api-https-bind = false
4. 编辑每个集群的配置文件
#集群1配置文件
vim /etc/replication-manager/cluster.d/cluster_5733.toml
[cluster_5733] #定义集群名称
title = "test_cluster_5733" #托管集群的明确描述
db-servers-hosts = "172.31.0.101:5733,172.31.0.102:5733,172.31.0.103:5733" #定义集群主机列表
db-servers-prefered-master = "172.31.0.102:5733" #指定切换后的master
db-servers-ignored-hosts = "172.31.0.103:5733" #指定切换选主时忽略的主机,如果本组件在集群中某个节点安装,则可设置此选项
db-servers-credential = "manager:manager123" #replication-manger管理账号与密码
replication-credential = "repuser:repuser123" #主从账号
db-servers-binary-path = "/usr/local/mysql_5733/bin" #指定本集群二进制包的位置
failover-post-script = "/etc/replication-manager/vip_up_5733.sh" #指定vip漂移脚本
#集群2配置文件
vim /etc/replication-manager/cluster.d/cluster_5738.toml
[cluster_5738] #定义集群名称
title = "test_cluster_5738" #托管集群的明确描述
db-servers-hosts = "172.31.0.101:5738,172.31.0.102:5738,172.31.0.103:5738" #定义集群主机列表
db-servers-prefered-master = "172.31.0.102:5738" #指定切换后的master
db-servers-ignored-hosts = "172.31.0.103:5738" #指定切换选主时忽略的主机,如果本组件在集群中某个节点安装,则可设置此选项
db-servers-credential = "manager:manager123" #replication-manger管理账号与密码
replication-credential = "repuser:repuser123" #主从账号
db-servers-binary-path = "/usr/local/mysql_5738/bin" #指定本集群二进制包的位置
failover-post-script = "/etc/replication-manager/vip_up_5738.sh" #指定vip漂移脚本
5. 故障转移脚本
vim /etc/replication-manager/vip_up.sh
#!/bin/bash
# 当前脚本适用于中间件为 replication-manager 的高可用VIP切换
# 接收传入参数 cluster.oldMaster.Host cluster.master.Host cluster.oldMaster.Port cluster.master.Port
orig_master=$1
new_master=$2
old_port=$3
new_port=$4
emailaddress="email@example.com"
sendmail=0
# 根据环境配置,interface,vip ,ssh_options,ssh_user 需要根据实际情况更改。
# 网卡名称
interface=eth0
# VIP
vip=172.31.0.188
# ssh用户
ssh_options=''
ssh_user='root'
# discover commands from our path
ssh=$(which ssh)
arping=$(which arping)
ip2util=$(which ip)
# command for adding our vip
cmd_vip_add="sudo -n $ip2util address add ${vip}/24 dev ${interface}"
# command for deleting our vip
cmd_vip_del="sudo -n $ip2util address del ${vip}/24 dev ${interface}"
# command for discovering if our vip is enabled
cmd_vip_chk="sudo -n $ip2util address show dev ${interface} to ${vip%/*}/32"
# command for sending gratuitous arp to announce ip move
cmd_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*}"
# command for sending gratuitous arp to announce ip move on current server
cmd_local_arp_fix="sudo -n $arping -c 1 ${vip%/*}"
vip_stop() {
rc=0
# ensure the vip is removed
$ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \
"[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && sudo ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]"
rc=$?
return $rc
}
vip_start() {
rc=0
# ensure the vip is added
# this command should exit with failure if we are unable to add the vip
# if the vip already exists always exit 0 (whether or not we added it)
$ssh ${ssh_options} -tt ${ssh_user}@${new_master} \
"[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]"
rc=$?
$cmd_local_arp_fix
return $rc
}
vip_status() {
$arping -c 1 ${vip%/*}
if ping -c 1 -W 1 "$vip"; then
return 0
else
return 1
fi
}
echo "`date +'%Y-%m-%d %T'` Master is dead, failover"
# make sure the vip is not available
if vip_status; then
if vip_stop; then
if [ $sendmail -eq 1 ]; then mail -s "$vip is removed from orig_master." "$emailaddress" < /dev/null &> /dev/null ; fi
else
if [ $sendmail -eq 1 ]; then mail -s "Couldn't remove $vip from orig_master." "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
fi
if vip_start; then
echo "`date +'%Y-%m-%d %T'` $vip is moved to $new_master."
if [ $sendmail -eq 1 ]; then mail -s "$vip is moved to $new_master." "$emailaddress" < /dev/null &> /dev/null ; fi
else
echo "`date +'%Y-%m-%d %T'` Can't add $vip on $new_master!"
if [ $sendmail -eq 1 ]; then mail -s "Can't add $vip on $new_master!" "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
(2)赋予vip漂移脚本执行权限
[root@lpn002082 opt]# chmod +x /etc/replication-manager/vip_up.sh
6 普通用户操作故障转移
需要在visudo中添加相关权限,并在vip漂移脚本中指定添加好权限的用户
[root@qilin-03 replication-manager]# visudo #添加以下权限
wanglu ALL=(ALL) NOPASSWD: /usr/sbin/ip address add 172.31.0.188/24 dev eth0 , /usr/sbin/ip address del 172.31.0.188/24 dev eth0 , /usr/sbin/ip address show dev eth0 to 172.31.0.188/24 , /usr/sbin/arping -c 1 -I eth0 172.31.0.188 , /usr/sbin/arping -c 1 172.31.0.188 , /usr/sbin/ip route flush cache
7. 服务启停
/etc/init.d/replication-manager start
/etc/init.d/replication-manager stop
或 replication-manager-osc --config=/etc/replication-manager/config.toml monitor #不常用
8. console界面进行快捷操作
#进入某集群的console界面
replication-manager-cli console --cluster=cluster_5733
#快捷操作
Ctrl + S 执行 switchover
Ctrl-(N|P) 切换集群
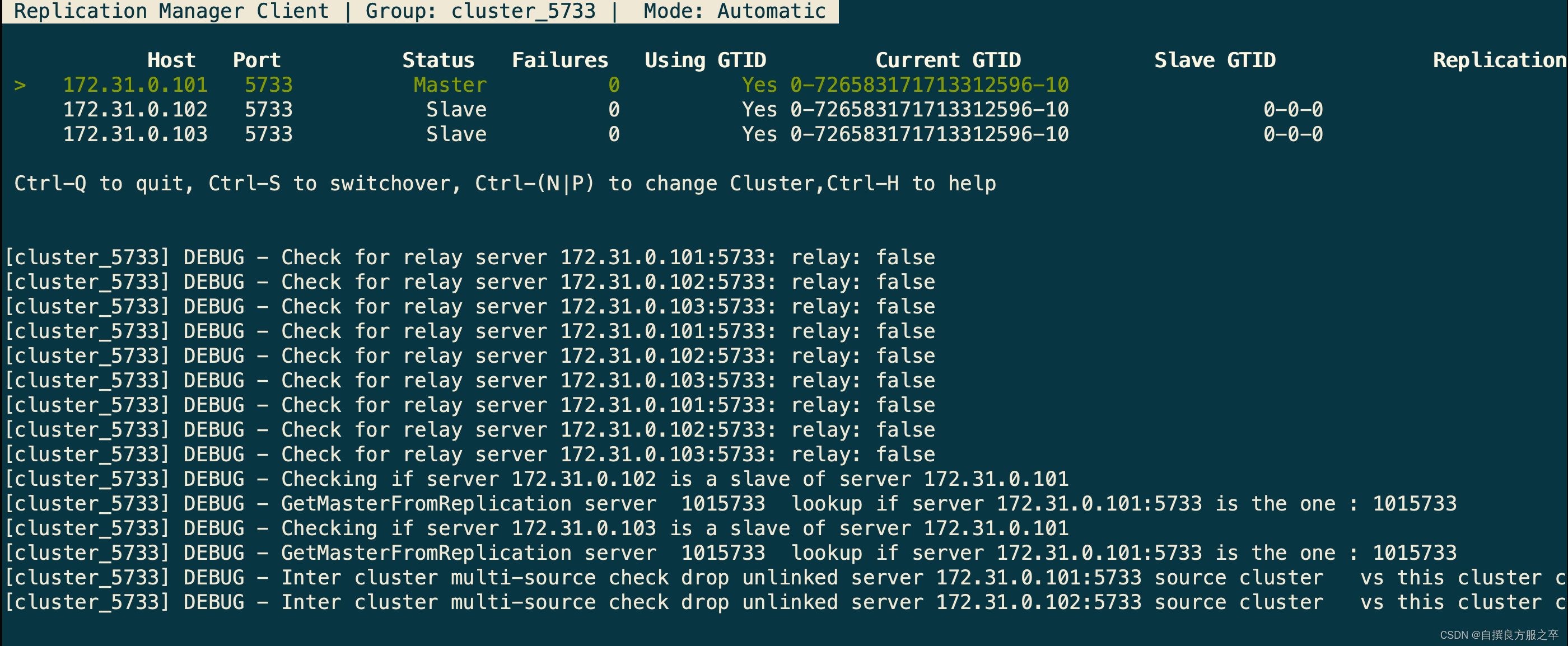
9. 命令行操作
#某集群进行switchover
replication-manager-cli switchover --cluster='test_cluster'
#某集群进行switchover,并指定新主节点
replication-manager-cli switchover --cluster='cluster_5738' --db-servers-prefered-master='172.31.0.102:5738'















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









