







MHA高可用
架构介绍
MHA(Master HighAvailability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。
Manager工具包主要包括以下几个工具:
- masterha_check_ssh 检查MHA的SSH配置状况
- masterha_check_repl 检查MySQL复制状况
- masterha_manger 启动MHA
- masterha_check_status 检测当前MHA运行状态
- masterha_master_monitor 检测master是否宕机
- masterha_master_switch 控制故障转移(自动或者手动)
- masterha_conf_host 添加或删除配置的server信息
MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
- save_binary_logs 保存和复制master的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs 清除中继日志(不会阻塞SQL线程)
整个故障转移过程对应用程序完全透明
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上最大限度的保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。
使用MySQL 5.5开始找支持的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器 ,一主二从,即一台master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器。
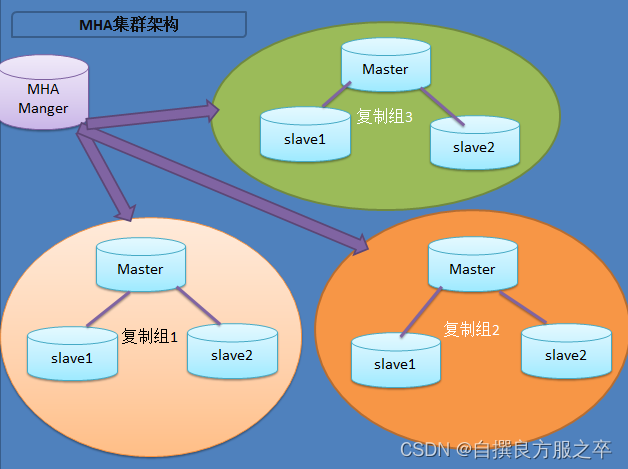
1.数据库基础环境搭建
1.1 部署规划
| 操作系统 | hostname | IP地址 | 端口 | 安装软件 |
|---|---|---|---|---|
| Centos7.8 | wl_01 | 172.31.0.101 | 3306 | MySQL8.0.28、mha4mysql-node-0.58 |
| Centos7.8 | wl_02 | 172.31.0.102 | 3306 | MySQL8.0.28、mha4mysql-node-0.58 |
| Centos7.8 | wl_03 | 172.31.0.103 | 3306 | MySQL8.0.28、mha4mysql-node-0.58 |
| Centos7.8 | wl_04(mha管理节点) | 172.31.0.104 | mha4mysql-manager-0.58、mha4mysql-node-0.58 |
1.2 下载安装MySQL二进制包
#安装依赖包
[root@wl_01 opt]# yum install -y gcc gcc-c++ ncurses-devel.x86_64 libaio bison gcc-c++.x86_64 perl perl-devel libssl-dev autoconf openssl-devel openssl numactl vim net-tools sysstat wget
#下载二进制包
[root@wl_01 ~]# cd /opt/
[root@wl_01 opt]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.28-linux-glibc2.12-x86_64.tar.xz
#解压二进制包
[root@wl_01 opt]# tar xf mysql-8.0.28-linux-glibc2.12-x86_64.tar.xz
#将解压后的目录软连接到/usr/local下
[root@wl_01 opt]# ln -s /opt/mysql-8.0.28-linux-glibc2.12-x86_64 /usr/local/mysql_8028
#添加相关环境变量
[root@wl_01 opt]# tail -1 /etc/profile
export PATH=/usr/local/mysql_8028/bin:$PATH
[root@wl_01 opt]# source /etc/profile
[root@wl_01 opt]# mysql -V
mysql Ver 8.0.28 for Linux on x86_64 (MySQL Community Server - GPL)
1.3 创建相关用户与目录
[root@wl_01 opt]# mkdir /mysql_8028/{data,logs,binlog,relaylog,run,tmp} -p
[root@wl_01 opt]# groupadd -g 1100 mysql
[root@wl_01 opt]# useradd -g mysql -u 1100 mysql
[root@wl_01 opt]# passwd mysql
Changing password for user mysql.
New password:
BAD PASSWORD: The password contains less than 2 non-alphanumeric characters
Retype new password:
passwd: all authentication tokens updated successfully.
[root@wl_01 opt]# chown -R mysql.mysql /mysql_8028/
1.4 编辑配置文件
#编辑配置文件
cat > /mysql_8028/my.cnf <<EOF
[mysql]
show-warnings
prompt="\\u@\\h : \\d \\r:\\m:\\s> "
default-character-set = utf8mb4
socket=/mysql_8028/run/mysql.sock
[mysqld]
user=mysql
port=3306
server_id=1013306
report_host=172.31.0.101
report_port=3306
default-time-zone='+8:00'
basedir=/usr/local/mysql_8028
datadir=/mysql_8028/data
tmpdir=/mysql_8028/tmp
pid-file=/mysql_8028/run/mysqld.pid
socket=/mysql_8028/run/mysql.sock
lower_case_table_names=1
character-set-server=utf8mb4
skip-name-resolve
default-storage-engine=INNODB
##connections
max_connections=2000
max_connect_errors=99999
max_allowed_packet=1G
wait_timeout=172800
interactive_timeout=172800
##buffer
net_buffer_length=8K #设置每个客户端会话线程相关的连接缓冲区和结果集缓冲区初始大小
read_buffer_size=2M
read_rnd_buffer_size=2M
sort_buffer_size=2M
max_length_for_sort_data=16k
join_buffer_size=4M
binlog_cache_size=2M
max_heap_table_size=10M
tmp_table_size=10M
internal_tmp_mem_storage_engine=MEMORY
open-files-limit=65535
table_open_cache=20000 #控制全局打开表数
table_definition_cache=20000 #缓存表定义文件.frm的数量
thread_cache_size=512
##log
log_error=/mysql_8028/logs/error.log
innodb_print_all_deadlocks= 1
long_query_time= 1
slow_query_log= 1
slow_query_log_file=/mysql_8028/logs/slow.log
log_bin=/mysql_8028/binlog/mysql_bin
binlog-format=ROW
max_binlog_size = 1G
binlog-rows-query-log-events=1
binlog_expire_logs_seconds=1209600 #14天
sync_binlog=1
relay-log=/mysql_8028/relaylog/mysql_relay
relay-log-recovery=1
relay_log_purge=1
log_slave_updates=1
##replica
gtid-mode=on #开启gtid模式,全局唯一事务id,方便运维管理
enforce-gtid-consistency=true
slave_parallel_workers=16
slave_parallel_type=LOGICAL_CLOCK
replica_preserve_commit_order=on
##transaction
transaction_isolation = READ-COMMITTED
innodb_thread_concurrency = 64
innodb_lock_wait_timeout = 50
innodb_rollback_on_timeout = 1
lock_wait_timeout = 120
##innodb
innodb_buffer_pool_size=1G
innodb_buffer_pool_instances=1
innodb_max_dirty_pages_pct = 75
innodb_flush_neighbors = 0
innodb_data_home_dir = /mysql_8028/data
innodb_data_file_path = ibdata1:2048M:autoextend
innodb_file_per_table
innodb_strict_mode = 1
innodb_flush_method = O_DIRECT
innodb_read_io_threads=8
innodb_write_io_threads=8
innodb_io_capacity=2000
#redolog
innodb_log_group_home_dir = /mysql_8028/data
innodb_log_buffer_size = 64M
innodb_log_file_size = 2G
innodb_log_files_in_group = 2 #设置redo log日志组中有多少个redo log文件
innodb_flush_log_at_trx_commit = 1
#undo
innodb_undo_directory=/mysql_8028/data #设置独立与系统表空间的undo logs文件存放路径
innodb_purge_threads= 4
EOF
1.5 初始化并启动所有实例
[root@wl_01 opt]# mysqld --defaults-file=/mysql_8028/my.cnf --initialize-insecure
[root@wl_01 opt]# mysqld_safe --defaults-file=/mysql_8028/my.cnf &
1.6 创建复制专用用户并开启主从
---在wl_01主库中创建复制用户
create user repl@'172.31.0.%' identified with mysql_native_password by 'repl123';
grant replication slave on *.* to repl@'172.31.0.%';
---在wl_01主库中创建mha管理用户
create user mhaadmin@'172.31.0.%' identified with mysql_native_password by 'mhaadmin123';
grant all privileges on *.* to mhaadmin@'172.31.0.%';
---wl_02/wl_03
change master to
master_host='172.31.0.101',
master_port=3306,
master_user='repl',
master_password='repl123' ,
MASTER_AUTO_POSITION=1;
start slave;
2. MHA环境搭建
2.1 配置各节点间的互信
---所有节点全部执行以下操作
---1.配置域名解析
vim /etc/hosts
172.31.0.101 wl_01
172.31.0.102 wl_02
172.31.0.103 wl_03
172.31.0.104 wl_04
---2.清理旧的ssh密钥
rm -rf /root/.ssh
---3.生成新密钥,一路回车
ssh-keygen -t rsa
---4.将公钥分发到所有节点
for i in {1..4};do ssh-copy-id -i root@wl_0$i;done
---5.各节点互信验证,如果每台主机上执行以下指令不用输入密码就可以获取所有主机的主机名,说明免密登录配置无误
for i in {1..4};do ssh wl_0$i hostname;done
2.2 下载安装mha软件
---所有节点下载node包(包括mha管理节点)
[root@wl_01 opt]# wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
[root@wl_01 opt]# yum install perl-DBD-MySQL -y
[root@wl_01 opt]# rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
安装完成后会在/usr/bin目录下生成以下脚本
[root@wl_01 bin]# ll apply_diff_relay_logs filter_mysqlbinlog purge_relay_logs save_binary_logs
-rwxr-xr-x 1 root root 17639 Mar 23 2018 apply_diff_relay_logs
-rwxr-xr-x 1 root root 4807 Mar 23 2018 filter_mysqlbinlog
-rwxr-xr-x 1 root root 8337 Mar 23 2018 purge_relay_logs
-rwxr-xr-x 1 root root 7525 Mar 23 2018 save_binary_logs
---mha管理节点下载安装manager包
[root@wl_04 opt]# wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
[root@wl_04 opt]# yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
[root@wl_04 opt]# rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
安装完成后会在/usr/bin目录下生成以下脚本
[root@wl_04 /usr/bin]# ll masterha*
-rwxr-xr-x 1 root root 1995 Mar 23 2018 masterha_check_repl
-rwxr-xr-x 1 root root 1779 Mar 23 2018 masterha_check_ssh
-rwxr-xr-x 1 root root 1865 Mar 23 2018 masterha_check_status
-rwxr-xr-x 1 root root 3201 Mar 23 2018 masterha_conf_host
-rwxr-xr-x 1 root root 2517 Mar 23 2018 masterha_manager
-rwxr-xr-x 1 root root 2165 Mar 23 2018 masterha_master_monitor
-rwxr-xr-x 1 root root 2373 Mar 23 2018 masterha_master_switch
-rwxr-xr-x 1 root root 5172 Mar 23 2018 masterha_secondary_check
-rwxr-xr-x 1 root root 1739 Mar 23 2018 masterha_stop
3. 配置MHA
3.1 编辑MHA配置文件
---(1)创建相关目录
---管理节点创建MHA管理集群的工作目录
[root@wl_04 opt]# mkdir -p /etc/mha/cluster_name1
---(2)编辑mha配置文件
[root@wl_04 opt]# vim /etc/mha/cluster_name1/cluster_name1.cnf
[server default]
manager_workdir=/etc/mha/cluster_name1
manager_log=/etc/mha/cluster_name1/cluster_name1.log
client_bindir=/usr/local/mysql_8028/bin/
client_libdir=/usr/local/mysql_8028/lib/
master_binlog_dir=/mysql_8028/binlog/
master_ip_failover_script=/etc/mha/cluster_name1/master_ip_failover
master_ip_online_change_script=/etc/mha/cluster_name1/master_ip_online_change
secondary_check_script='masterha_secondary_check -s 172.31.0.102 -s 172.31.0.103'
report_script=/etc/mha/cluster_name1/send_report
remote_workdir=/tmp
user=mhaadmin
password=mhaadmin123
repl_user=repl
repl_password=repl123
ping_interval=3
ssh_user=root
[server1]
hostname=172.31.0.101
port=3306
[server2]
hostname=172.31.0.102
port=3306
[server3]
hostname=172.31.0.103
port=3306
[binlog1]
hostname=172.31.0.101
#配置文件参数说明
[server default]
manager_workdir=/etc/mha/cluster_name1 #mha工作目录
manager_log=/etc/mha/cluster_name1/cluster_name1.log #mha日志文件
master_binlog_dir=/mysql_8028/binlog/ #主库的binlog路径,若每个节点路径不一致,需要在每个节点单独指定
client_bindir=/usr/local/mysql_8028/bin/ #mysql 二进制命令目录
client_libdir=/usr/local/mysql_8028/lib/ #mysql lib文件目录
remote_workdir=/tmp #MHA node程序生成日志文件的工作目录完整路径名。
master_ip_failover_script=/etc/mha/cluster_name1/master_ip_failover #故障转移脚本
secondary_check_script='masterha_secondary_check -s 172.31.0.102 -s 172.31.0.103' #二次检查脚本,防止只有manager节点检测出现误判
master_ip_online_change_script=/etc/mha/cluster_name1/master_ip_online_change #在线切换脚本
report_script=/etc/mha/cluster_name1/send_report #发生故障切换后的通知脚本
user=mhaadmin #MHA管理用户
password=mhaadmin123 #MHA用户密码
repl_user=repl #复制用户
repl_password=repl123 #复制用户
ping_interval=3 #心跳检测时间间隔3秒
ssh_user=root #ssh互信用户
[server1]
hostname=172.31.0.101
port=3306
[server2]
hostname=172.31.0.102
port=3306
[server3]
hostname=172.31.0.103
port=3306
[binlog1]
hostname=172.31.0.101 #当 MHA 进行基于 GTID 的故障转移时,MHA 会检查 binlog 服务器,如果 binlog 服务器领先于其他从属服务器,则 MHA 在恢复之前将差异的 binlog 事件应用到新的主服务器。当 MHA 执行基于非 GTID(传统)的故障转移时,MHA 会忽略 binlog 服务器
----------------------------------------下面两个参数根据情况判断是否使用----------------------------------------
candidate_master=1 #设为候选master,如果设置该参数后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中时间最新的slave
check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为新master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时。这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
3.2 配置故障转移脚本
[root@wl_04 opt]# vim /etc/mha/cluster_name1/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
my $vip = '172.31.0.188';
my $mask = '24';
my $key = "1";
my $if='eth0';
my $ssh_start_vip = "/sbin/ifconfig $if:$key $vip/$mask";
my $ssh_stop_vip = "/sbin/ifconfig $if:$key down";
my $ssh_send_garp = "/sbin/arping -U $vip -I eth0 -c 1";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "Disabling the VIP an old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print "Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
# print "Creating app user on the new master..\n";
# FIXME_xxx_create_user( $new_master_handler->{dbh} );
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
print "Enabling the VIP $vip on the new master: $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
# If you want to continue failover, exit 10.
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip(){
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
`ssh $ssh_user\@$new_master_host \" $ssh_send_garp \"`;
}
sub stop_vip(){
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
3.3 配置在线切换脚本
[root@db04 opt]# vim /usr/local/bin/master_ip_online_change
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
###########################################################################
my $vip = "172.31.0.188";
my $mask = "24";
my $key = "1";
my $if = "eth0";
my $ssh_start_vip = "/sbin/ifconfig $if:$key $vip/$mask";
my $ssh_stop_vip = "/sbin/ifconfig $if:$key $vip down";
my $ssh_Bcast_arp= "/sbin/arping -I $if -c 3 -A $vip";
###########################################################################
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart);
if ( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping app user on the orig master..\n";
###########################################################################
#FIXME_xxx_drop_app_user($orig_master_handler);
###########################################################################
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
###########################################################################
print "disable the VIP on old master: $orig_master_host \n";
&stop_vip();
###########################################################################
## Terminating all threads
print current_time_us() . " Killing all application threads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. Register new master's ip to the catalog database
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print current_time_us() . " Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
print current_time_us() . " Creating app user on the new master..\n";
###########################################################################
#FIXME_xxx_create_app_user($new_master_handler);
###########################################################################
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
###############################################################################
print "enable the VIP: $vip on the new master: $new_master_host \n ";
&start_vip();
###############################################################################
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
###########################################################################
sub start_vip() {
`ssh $new_master_ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
###########################################################################
sub usage {
print
"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
die;
}
3.4 配置故障报警脚本
[root@wl_04 opt]# vim /etc/mha/cluster_name1/send_report
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp='smtp.163.com';
my $mail_from='wangludba@163.com';
my $mail_user='wangludba';
my $mail_pass='UIVNOQPNAHQPAKQO';
my $mail_to=['wangludba@163.com'];
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' => \$new_master_host,
'new_slave_hosts=s' => \$new_slave_hosts,
'subject=s' => \$subject,
'body=s' => \$body,
);
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, "> /tmp/monitormail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain; charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $user,
authpwd => $passwd,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{ msg => $msg,
debug => $DEBUG
}
) or print $Mail::Sender::Error;
return 1;
}
exit 0;
3.5 主节点添加VIP
[root@wl_01 opt]# ifconfig eth0:1 172.31.0.188/24
[root@wl_01 opt]# ifconfig
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.31.0.188 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:c4:00:66 txqueuelen 1000 (Ethernet)
3.6 检查架构状态,并开启MHA
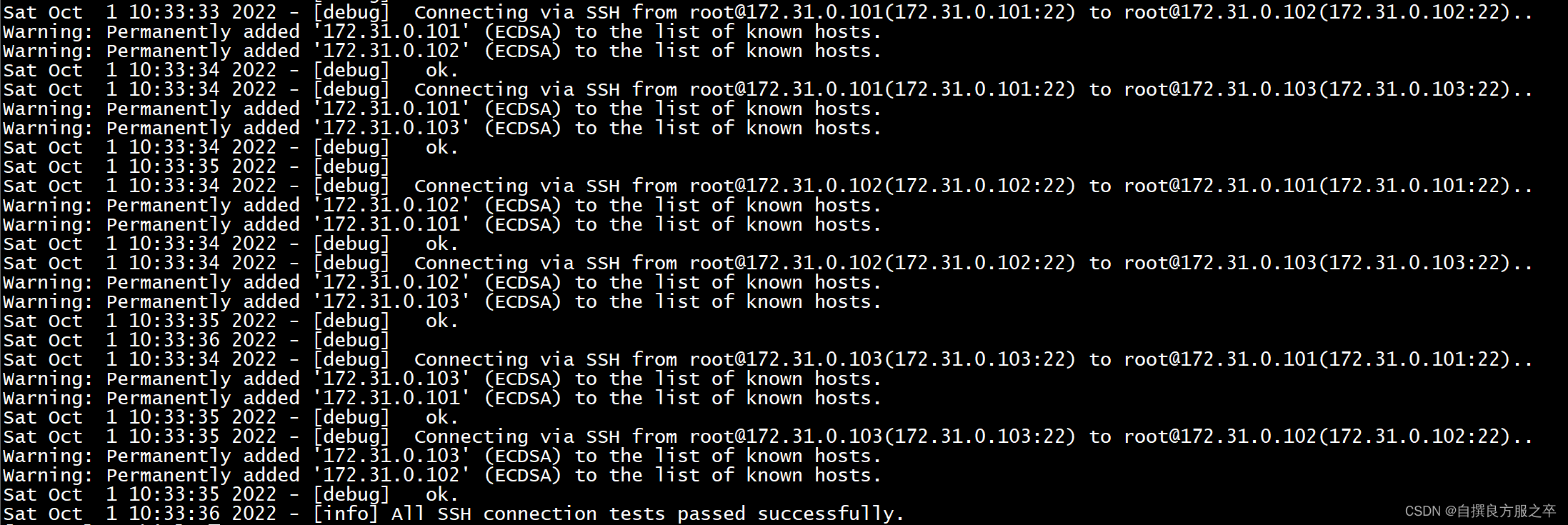
(1)ssh互信检查
[root@wl_04 opt]# masterha_check_ssh --conf=/etc/mha/cluster_name1/cluster_name1.cnf
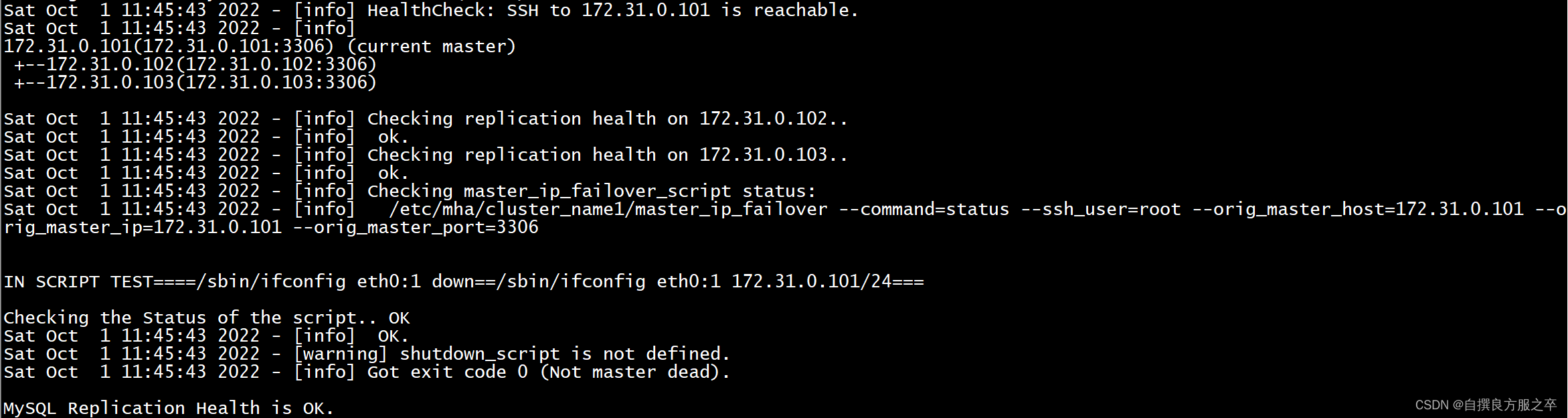
(2)主从状态检查
[root@wl_04 opt]# masterha_check_repl --conf=/etc/mha/cluster_name1/cluster_name1.cnf
(3)开启MHA:
[root@wl_04 opt]# masterha_manager --conf=/etc/mha/cluster_name1/cluster_name1.cnf --ignore_last_failover &
---参数:
`1.--remove_dead_master_conf` #发生主从切换后,老的主库的IP将会从配置文件中移除,为了避免连续故障转移时将故障节点选为主库(可不加)
`2.--ignore_last_failover` #在缺省的情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时,则不进行Failover。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录里产生failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后手动删除该文件,为了方便,这里设置为--ignore_last_failover
(4)查看MHA状态
[root@wl_04 opt]# masterha_check_status --conf=/etc/mha/cluster_name1/cluster_name1.cnf
cluster_name1 (pid:26709) is running(0:PING_OK), master:172.31.0.101
#work_dir下的cluster_name1.master_status.health文件中记录着健康状态
[root@wl_04 opt]# tail -f /etc/mha/cluster_name1/cluster_name1.master_status.health
26709 0:PING_OK master:172.31.0.101
3.7 故障转移流程
1.manager节点首次发现主库失联后,触发二次检查脚本
2.从库所有节点对主库进行select探测
3.3次健康检测都失败后,检查ssh的连通性
4.从mha配置文件中读取所有节点信息,获取所有节点的配置信息,确认主库已经down掉,然后开始故障转移
故障转移流程:
Phase 1: Configuration Check Phase..
Phase 2: Dead Master Shutdown Phase..
如果设置了shutdown_script,会再强制关闭主库一次,以防脑裂问题
Phase 3: Master Recovery Phase..
Phase 3.1: Getting Latest Slaves Phase..
Phase 3.2: Determining New Master Phase..
Phase 3.3: New Master Recovery Phase..
Waiting all logs to be applied..
Saving binlog from host 172.31.0.101
Fetching binary logs from binlog server 172.31.0.101..
Applying differential binlog
Getting new master's binlog name and position..
All other slaves should start replication from here.
Master Recovery succeeded.
Set read_only=0 on the new master.
Phase 4: Slaves Recovery Phase..
Phase 4.1: Starting Slaves in parallel..
Resetting slave
starting replication from the new master
Executed CHANGE MASTER.
Slave started.
gtid_wait completed
All new slave servers recovered successfully.
Phase 5: New master cleanup phase..
Resetting slave info on the new master..
Master failover completed successfully.
Phase 6: Failover Report
4. 验证故障转移
(1)手工宕掉主库
[root@wl_01 ~]# mysql -S /mysql_8028/run/mysql.sock
mysql> shutdown;
(2)验证VIP漂移
[root@wl_02 ~]# ip a | grep 172.31.0.188/24
inet 172.31.0.188/24 brd 172.31.0.255 scope global secondary eth0:1
5. 修复MHA架构
(1)修复down掉的节点,与新master节点构建主从关系
change master to
master_host='172.31.0.102',
master_port=3306,
master_user='repl',
master_password='repl123' ,
MASTER_AUTO_POSITION=1;
start slave;
(3)重新检查ssh互信状态,主从状态,开启MHA,检查MHA状态
[root@db04 opt]# masterha_check_ssh --conf=/etc/mha/cluster_name1/cluster_name1.cnf
[root@db04 opt]# masterha_check_repl --conf=/etc/mha/cluster_name1/cluster_name1.cnf
[root@db04 opt]# masterha_manager --conf=/etc/mha/cluster_name1/cluster_name1.cnf --ignore_last_failover &
[root@db04 opt]# masterha_check_status --conf=/etc/mha/app1.cnf
6. 在线切换功能
用于在线验证MHA故障转移功能是否正常,在线切换时,自动锁原主库,VIP自动切换
(1)停止masterha_manager进程
[root@wl_04 opt]# masterha_stop --conf=/etc/mha/cluster_name1/cluster_name1.cnf
Stopped cluster_name1 successfully.
[1]+ Exit 1 masterha_manager --conf=/etc/mha/cluster_name1/cluster_name1.cnf
(2)开启在线切换
[root@db04 opt]# masterha_master_switch --conf=/etc/mha/cluster_name1/cluster_name1.cnf --master_state=alive --new_master_host=172.31.0.101 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
参数:
--orig_master_is_new_slave 将原master变成slave,默认MHA不做上述操作.
--running_updates_limit=10000,默认值时1000ms,在切换时,如果主库执行的更新操作花费的时间超过默认大小1000ms,或者新主库和老主库之间的主从延迟超过1000ms,那么MHA进行切换就会失败,我们修改了这个值以后,可以让这个时间限制改为10000ms,提高成功切换的几率
7.常用命令
ifconfig eth0:1 172.31.0.188/24 #添加vip
masterha_check_ssh --conf=/etc/mha/cluster_name1/cluster_name1.cnf #检查集群ssh的连通性
masterha_check_repl --conf=/etc/mha/cluster_name1/cluster_name1.cnf #检查主从关系
masterha_manager --conf=/etc/mha/cluster_name1/cluster_name1.cnf --ignore_last_failover & #开启mha
masterha_stop --conf=/etc/mha/cluster_name1/cluster_name1.cnf #关闭mha
masterha_check_status --conf=/etc/mha/cluster_name1/cluster_name1.cnf #检查mha状态
masterha_master_switch --conf=/etc/mha/cluster_name1/cluster_name1.cnf --master_state=alive --new_master_host=172.31.0.101 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 #在线切换主库















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









