







最近在学习的过程当中,经常遇到PCA降维,于是就学习了PCA降维的原理,并用网上下载的iris.txt数据集进行PCA降维的实践。为了方便以后翻阅,特此记录下来。本文首先将介绍PCA降维的原理,然后进入实战,编写程序对iris.数据集进行降维。
一、为什么要进行数据降维?
在数据处理中,经常会遇到特征维度比样本数量多得多的情况,如果直接放到机器学习算法中,效果不一定好。一是因为冗余的特征会带来一些噪音,影响计算的结果;二是因为无关的特征会加大计算量,耗费时间和资源。因此,降维往往作为预处理步骤,在数据应用到其他算法之前清洗数据。降维技术使得数据变得更易使用,并且它们往往能够去除数据中的噪声,使得其他机器学习任务更加精确。准确来说,降维致力于解决三大问题:
(1)降维可以缓解维数灾难问题。
现实应用中属性维数经常成千上万,由于许多学习方法都涉及距离计算,而高维空间会给距离计算带来很大的麻烦,例如当维数很高时甚至连计算内积都不再容易。通常,在高维情形下出现的数据样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为“维数灾难”。缓解维数灾难的一个重要途径就是降维,亦称为“维数约简”,即通过某种数学变换将原始高维属性空间转变为一个低维“子空间”,在这个子空间中样本密度大幅提高,距离计算也变得更为容易。
(2)降维可以在压缩数据的同时让信息损失最小化。
我们希望在尽可能减少信息损失的情况下来降低数据的维度,通常来说,我们期望得到的结果,是把原始数据的特征空间(n个d维样本)投影到一个小一点的子空间里(n个k维样本,其中k<<d)去,并尽可能表达的很好(就是说损失信息最少)。
(3)由于人类思维的限制,理解几百个维度的数据结构很困难,若将数据维数降至二维或三维,则可以通过可视化技术来直观地展示数据分布。
二、PCA降维的概念
PCA是一种较为常用的降维技术,PCA的思想是将n维特征映射到k维上,这k维是全新的正交特征。在PCA中,数据从原来的坐标系转换到了新的坐标系,新的坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。
三、PCA算法的步骤
将数据转换成前N个主成分的伪代码大致如下:
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值从大到小排序
保留最前面的N个特征值所对应的特征向量
将原始数据转换到上述N个特征向量构建的新空间中
具体的算法流程如下所示:

四、PCA代码实现
本文基于iris数据集来进行PCA降维演示,Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据。其中每行数据包含每个样本的四个特征和样本的类别信息,可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。所以Iris数据集是一个150行5列的二维表。
我们把样本数据存储在一个irisdata.txt的文件当中,局部样本数据如下图所示:
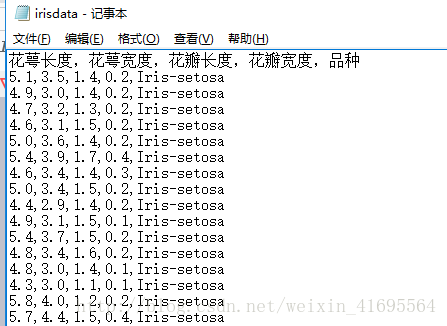
为了方便,本文的例子是想把二维的空间降成一维的空间,因此截取了花瓣长度和花瓣宽度这两列数据作为样本集(150*2),部分样本集如下所示:

为了更加直观的表示样本数据集,我们利用matplotlib这个第三方绘图库,采用散点图的形式将数据展示出来,散点图分布如下所示:
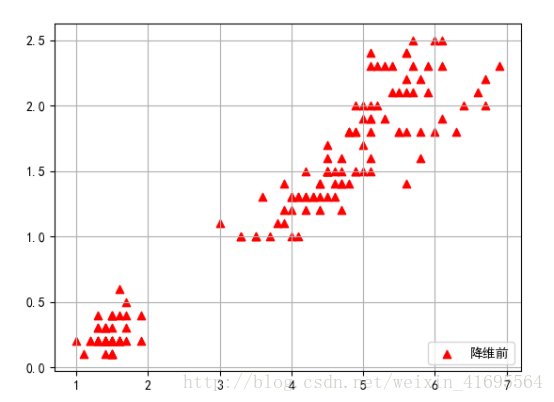
接下编写PCA算法的代码,我们在irisdata.txt文件所在的目录下,新建了一个pca.py的文件,并在里面写入以下代码,如下所示:
import numpy
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simHei']
#这句话用来设置 matplotlib.pyplot模块绘制的图中正常显示中文字体
###################################
####PCA降维技术应用于iris数据集#####
#### time:2018.3.8 ####
#################################
def loaddataset(filename):
"""
这是一个加载iris数据集的函数
输入: filename是iris数据集的相对存储路径
输出: dataset是数据集合
"""
with open(filename) as fr:
rowArr = [line.strip().split(',')[2:] for line in fr.readlines()[1:]]
dataset =[]
for i in range(len(rowArr )):
dataArr = []
for j in range(2):
dataArr.append( float(rowArr[i][j] ))
dataset.append(dataArr )
return numpy.array(dataset)
def pcaProcessingData( dataset, figureNumber ):
"""
此函数的作用是对输入的数据进行PCA降维处理
输入: dataset是输入的待处理的数据集
figureNumber用以指定降维后的数据维度
输出:
"""
meanValue = numpy.mean( dataset,axis=0 ) #mean()函数对数组进行求均值运算,其中axis=0表示对各列求均值,返回1* n数组
centered_dataset = dataset - meanValue #将样本数据进行中心化,即对每个维度减去这个维度的数据均值
covariance_matrix = numpy.cov( centered_dataset,rowvar=0 )
#cov()函数实现的是求出两个变量的协方差矩阵,得到一个2*2的数组,其中rowvar=0表示将每一列看作一个变量
eigenvalue,eigenvector = numpy.linalg.eig( covariance_matrix )
#eig()函数求解矩阵的特征值和特征向量,该函数将返回一个元组,其中第一个元素为特征值,
# 第二个元素为特征向量(且每一列为一个特征向量)
eigenvalue_sorted_index = numpy.argsort( -eigenvalue )
#将特征值数组元素从大到小进行排序,并返回排序后元素的索引
projection_matrix = eigenvector[:,eigenvalue_sorted_index[:figureNumber]]
#取排序后的前figureNumber个特征值所对应的特征向量组成投影矩阵
newDataSet = numpy.dot(centered_dataset,projection_matrix) #得到原样本向量在新坐标系中的坐标向量,即降维后的数据集
reconstructedData = numpy.dot ( newDataSet, projection_matrix.T ) + meanValue #将降维后的数据进行重构
return newDataSet, reconstructedData
def data_visualization( dataset, recondataset ):
"""
这是一个将数据集进行可视化的函数,以散点图的形式将数据展示出来
输入: dataset是输入的数据集
输出: 散点图
"""
x_coordinates_Arr1 = dataset[:,0]
y_coordinates_Arr1 = dataset[:,1]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(x_coordinates_Arr1, y_coordinates_Arr1, c='red',alpha=1,marker='^',label = u'降维前')
x_coordinates_Arr2 = recondataset[:, 0]
y_coordinates_Arr2 = recondataset[:, 1]
ax.scatter(x_coordinates_Arr2, y_coordinates_Arr2, c='green', alpha=1,marker='+',label =u'降维后')
plt.grid(True)
plt.legend(loc=4)
plt.show()
if __name__ == '__main__':
dataset = loaddataset('irisdata.txt')
print(dataset)
newDataSet, reconstructedData = pcaProcessingData(dataset, 1)
print('降维后的数据集:')
print(newDataSet)
data_visualization( dataset,reconstructedData )
运行上述代码,得到结果如下所示:
降维后的数据集(局部):
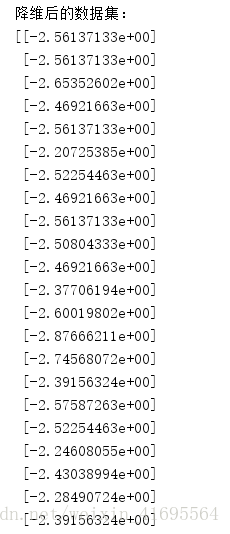
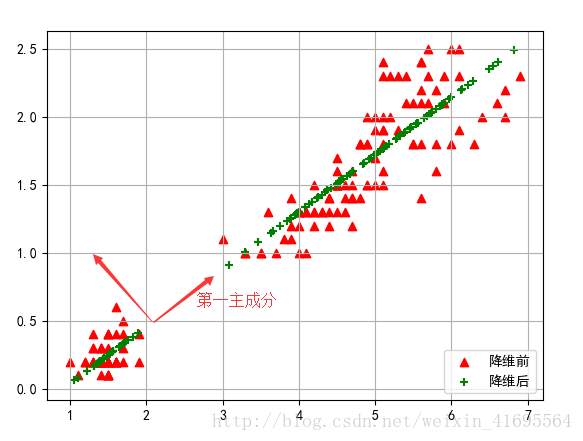
得到原始数据集(红色三角形点表示)及第一主成分(绿色叉号表示),如下:
参考资料:
[1] 周志华 《机器学习》
[2] Peter Harrington 《机器学习实战》















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









