







spark core源码阅读-Storage shuffle(八)
本节主要介绍RDD.aggregateByKey导致的shuffle,分两部分map shuffle,reduce shuffle
一 map shuffle
ShuffleMapTask中Task如何处理rdd.iterator,shuffle中Map端如何根据根据分区把数据写入文件.
主要类简述
ShuffleManager
Driver/Executors创建SparkEnv时创建该类,不同的ShuffleManager对应不同ShuffleWriter,
通过Driver通过spark.shuffle.manager指定使用策略三个重要方法:
registerShuffle:driver端初始化ShuffleDependency生成
getWriter:在map任务中生成shuffle后的文件
getReader:在reduce任务中获取,以从mappers中读取被组合的记录分类:
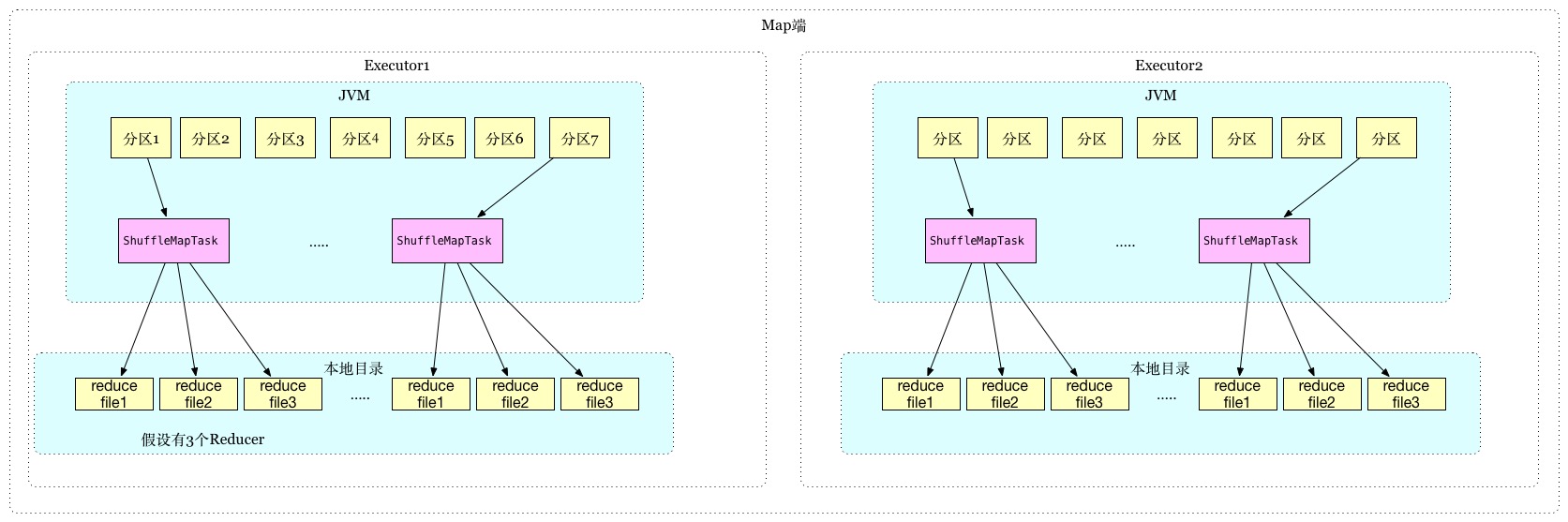
- (1) HashShuffleManager
1.2.0版本shuffle方式,有一些缺点,主要是大量小文件,每一个mapper task根据reducer数量创建分区文件,假设有M个Mapper,
R个Reducer,总共会创建M*R个小文件,如果有46k个Mapper和46k个reducer就会在集群产生2billion的文件
目前的版本已经做了优化,在mapper端优化,executor中task写同样文件,不过在1.5版本删除了SPARK-9808,
因为有更好的基于排序的shuffle改进
优点:
- 快,不需要排序,不需要维护hash表
- 没有额外的排序内存消耗
- 没有IO开销,一次性写硬盘,一次性读硬盘
缺点:
- partitions数量多,会产生大量小文件,影响性能
写入文件系统的大量文件导致IO倾向于随机IO,这通常比顺序IO慢100倍
(2) SortShuffleManager
default,在基于排序的shuffle中,rdd iter records将根据其目标分区ID进行排序写入单个map输出文件.
reducer获取此文件的连续区域以便阅读他们的map输出部分。 在map输出数据太大而不适合缓存的情况下
排序的输出子集可以被分散到磁盘上,并且这些磁盘上的文件被合并生成最终的输出文件。- (1) HashShuffleManager
ShuffleHandle
registerShuffle,根据不同场景选择不同ShuffleWriterShuffleWriter
HashShuffleManager=>HashShuffleWriter
过程如图:
SortShuffleManager
Manager按照以下顺序,根据不同条件选择ShuffleHandle:UnsafeShuffleWriter(Tungsten中优化项)
SPARK-7081
使用特殊高效内存排序ShuffleExternalSorter, 它对压缩记录指针和分区ID数组进行排序,通过在排序阵列中每个记录
仅使用8个字节的空间,CPU缓存可以更有效地工作
触发条件:- 序列化策略支持如
UnsafeRowSerializer,KryoSerializer,能直接在二进制上操作不需要反序列化数据 - 不需要聚合
- 分区数不能超过16 million
- 序列化策略支持如
BypassMergeSortShuffleWriter
HashShuffleWriterSPARK-9808放在该类,在writePartitionedFile方法中合并所有分区文件,这样每个map一个
output文件,HashShuffleManager2billion的shuffle文件就减少到46k
触发条件:spark.shuffle.manager=sort- “reducers”<“spark.shuffle.sort.bypassMergeThreshold” (默认200)
- SortShuffleWriter
过程如图:

ExternalSorter
通过Partitioner把key分区,在每个分区内排序,为每个分区输出单个分区文件IndexShuffleBlockResolver
逻辑块与物理文件Mapping,生成数据文件块索引文件PartitionedAppendOnlyMap
具有以下特征:
- AppendOnlyMap 内存存储,只能添加
- WritablePartitionedPairCollection
- 键值对都有分区信息
- 支持高效的内存排序iter
- 支持WritablePartitionedIterator直接以字节形式写入内容
Sorter
TimSort:是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法

主要方法
insertAll
迭代器循环处理数据
内存不足溢出到磁盘// Combine values in-memory first using our AppendOnlyMap val mergeValue = aggregator.get.mergeValue val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { addElementsRead() kv = records.next() // map=>PartitionedAppendOnlyMap map.changeValue((getPartition(kv._1), kv._1), update) // 内存不足溢出到磁盘 maybeSpillCollection(usingMap = true) }writePartitionedFile将所有添加到ExternalSorter中的数据写入磁盘存储中的文件

二 reduce shuffle
看一下ShuffledRDD中的compute
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}BlockStoreShuffleReader
该方法中:
- 通过
ShuffleBlockFetcherIterator远程获取各个map端相应的分区数据 - 需要map端合并,
combineCombinersByKey,使用ExternalAppendOnlyMap.insertAll数据结构缓存,内存不足溢出文件 - 需要排序,
ExternalSorter.insertAll循环排序 sorter.iterator合并数据集(如果有多个溢出文件,合并成一个)- 返回
CompletionIterator
- 通过
参考
- spark-architecture-shuffle
- TungstenSecret
TODO - TimSort JDK ComparableTimSort
- RoaringBitmap















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









