







 本文详细介绍了 Spark 中累加器的使用场景、基本原理,并通过源码分析揭示了累加器在 Driver 端与分布式计算中的逻辑,包括抽象类、实现类以及AccumulatorParam的实现。特别地,讨论了累加器变量如何在不同任务间合并以及在Executor端的任务执行过程。同时,文章提醒读者注意累加器在多阶段计算中的数据一致性问题,并给出了自定义AccumulatorParam的方法。
本文详细介绍了 Spark 中累加器的使用场景、基本原理,并通过源码分析揭示了累加器在 Driver 端与分布式计算中的逻辑,包括抽象类、实现类以及AccumulatorParam的实现。特别地,讨论了累加器变量如何在不同任务间合并以及在Executor端的任务执行过程。同时,文章提醒读者注意累加器在多阶段计算中的数据一致性问题,并给出了自定义AccumulatorParam的方法。
spark-core源码阅读-累加器(十)
使用场景
累加器是一种支持并行只能added的特殊变量,常用来计次/求和,我们也可以自行定义新数据类型支持added
基本原理
累加器变量在每个task任务中依次added,把结果传到Driver端进行合并,所以这是分布式计算,只有driver端才能读取累加器最终值
先看一个例子
object AccumulatorTest {
val conf = new SparkConf().setAppName("Spark Join")
val sc = new SparkContext(conf)
val accum1 = sc.accumulator(2000, "total even")
val accum2 = sc.accumulator(1000, "total odd")
val data = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 2).map(x => {
if (x % 2 == 0) accum1 += x
else accum2 += x
x
})
data.cache().distinct().count()
// data.foreach(println)
// data.foreach(accum += _)
println(accum1.value)
println(accum2.value)
sc.stop()
}例子中先通过SparkContext.accumulator初始化累加器,然后在MapPartitionsRDD-map中根据逻辑判断执行added操作
Spark UI图如下,其中Tasks-Accumulators展示了每个task不同类别累加值,Accumulators表展示该stage最终累加值
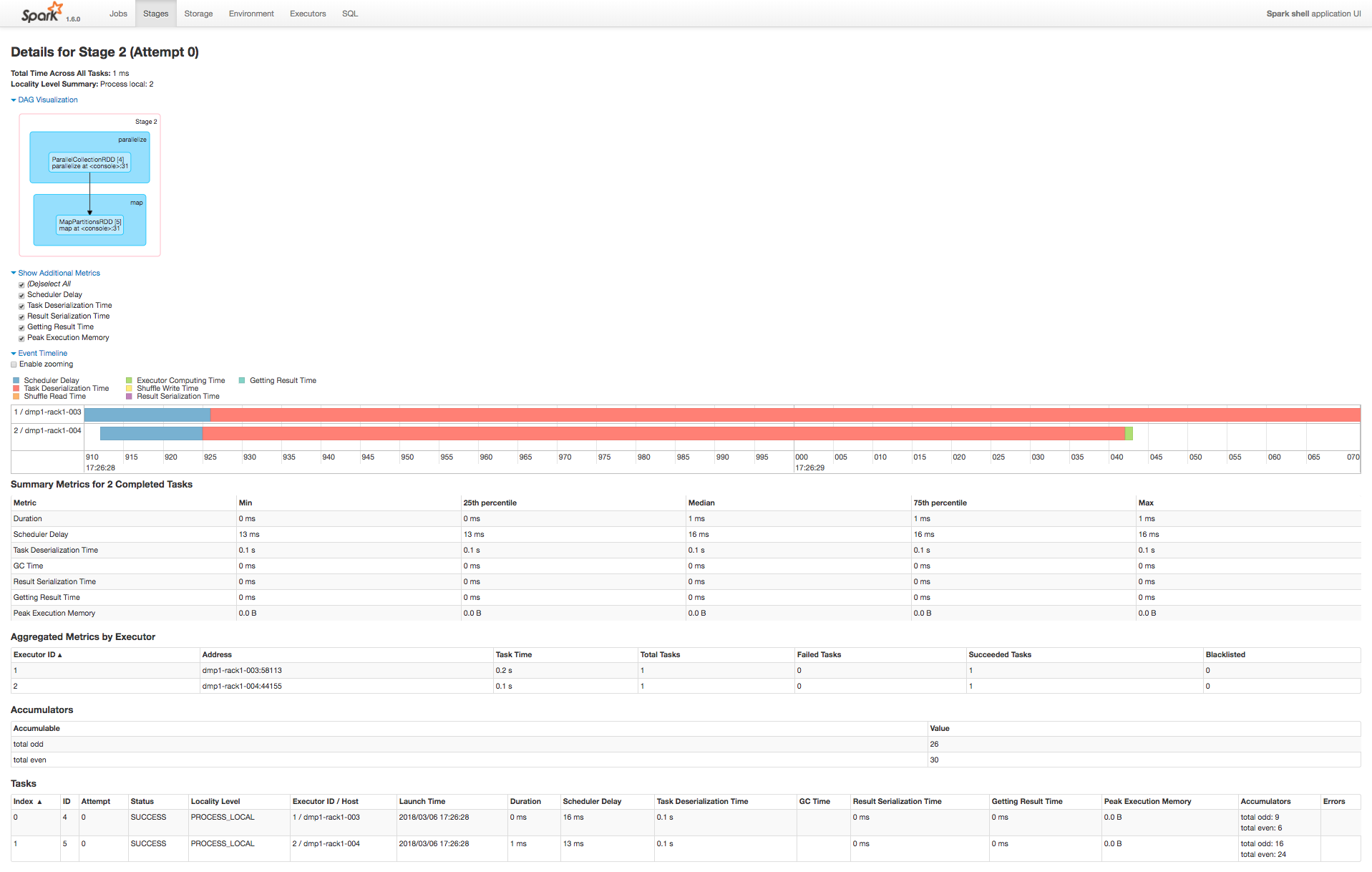
源码分析
抽象类Accumulable
class Accumulable[R, T] private[spark] (
initialValue: R,
param: AccumulableParam[R, T],
val name: Option[String],
internal: Boolean)
extends Serializable {
...
@volatile @transient private var value_ : R = initialValue // Current value on master
val zero = param.zero(initialValue) // Zero value to be passed to workers
private var deserialized = false
Accumulators.register(this)
...
}具体实现类Accumulator
class Accumulator[T]  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6555
6555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









