






文章目录
前言
这篇文章想聊一下最近在改版的一个模块,
在我们产品中叫流程引擎,
一般通用叫法为任务型的对话管理。
我们最近在修改:流程引擎;
对话管理涉及的范围很大,
不同类型的机器人、不同应用场景、不同公司的做法可能都不一样。
过去经常有朋友和同事问到
对话模型和对话管理的做法,
对于多轮对话、对话流程设计、话术管理、VUI、端到端方法等这些术语,
有些人会比较懵,
由于涉及面比较广,
这里把话题限定到任务型的机器人,
从实用角度聊一下它的发展、实践以及个人的理解。
本文并没有太多学术前沿,
而是希望从工业实践角度上聊一聊对话管理,
适合阅读的人群是对话系统的工程师、产品和运营,
以及对chatbot感兴趣的朋友。
文章的组织结构分三篇,
第一篇
回顾了常见的hand-crafted对话管理方法,
并介绍了几种基于数据的对话管理做法,
第二篇
概述了
data-driven方法用在实际项目中的
困难,
第三篇
从conversational interface层面
分享下业界的解决方案,
最后简要聊一下我们公司正在做的改版。
"Conversational interface"指的是
“会话式界面”或“对话式接口”,它是一种用户交互方式,
允许用户通过
自然语言与计算机系统进行交流。这种界面设计
使得用户能够
以类似日常对话的方式与
应用程序或服务互动,通常用于
聊天机器人、语音助手和某些类型的应用程序中。
1、介绍hand-crafted方法和data-driven方法
2、data-driven方法的困难
3、业界解决方案 + 得助
文章比一开始的预期要长很多,
写完之后发现行文有些啰嗦,
能坚持看完的朋友对chatbot肯定是真爱。
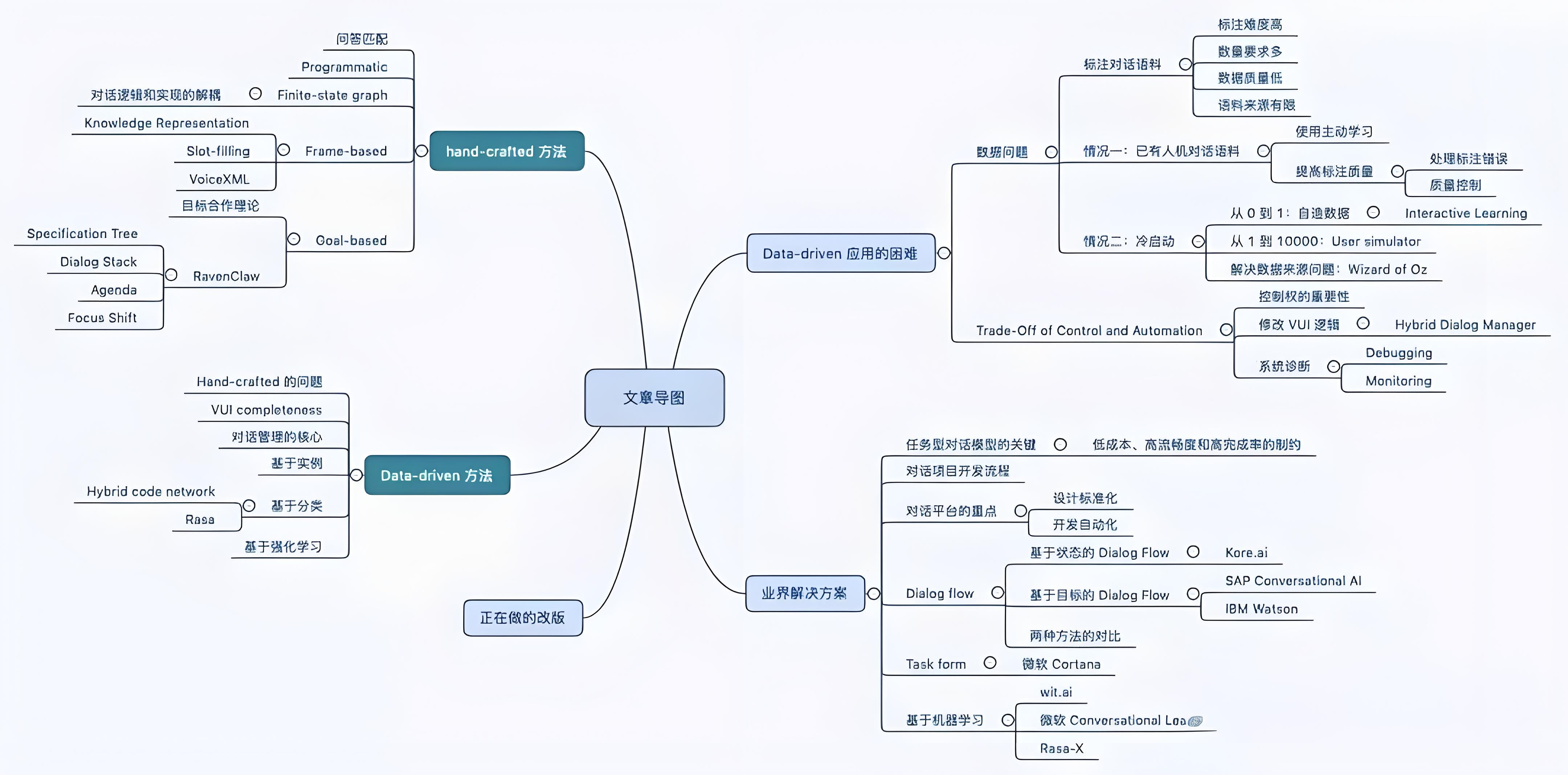
下面是本文的思维导图,
对这个领域有了解的话建议选择性阅读,
深色节点的是本篇讨论的两块内容。
(点击图片可查看大图)
对话管理(Dialog Manager,下文简称 DM)
一般的定义是,
根据用户当前的输入,
以及对话上下文,
决定系统下一步的最佳响应。
用户问 + 上下文 -> 决定 -> 最佳响应
对于任务型DM,
其职责是通过一致性的对话交互,
完成用户的对话目标。
这个定义虽然简短,
但却是下文所有方法的核心。
我们先从最简单的方法讲起,
通过实例慢慢聊下DM的发展逻辑。
问答匹配方法 - 命令式对话管理
最简单的对话系统可能是被动响应的问答匹配,
根据系统内部维护的命令-响应table,
对输入text做模式匹配或语义识别,
输出匹配命中的响应。
命令-响应table;
这类对话系统只能处理最简单的命令式的任务,
类似unix命令行工具、
它没有异常处理机制、无法利用上下文、无法与人进行多轮交互。
缺点
1、没有异常处理机制
2、无法利用上下文
3、无法多轮交互
Programmatic方法 - 编程式对话管理
为了支持多轮的对话交互,
早期的商业对话应用(例如以前IVR系统)
直接将对话逻辑用C++或Java在系统中实现,
即programmatic dialog management1。
Pieraccini,R.,Huerta, J., 2005.Where do we go from here? Research and commercial spoken dialog systems.
In: Proc.
5th SIGDIAL Workshop on Discourse and Dialogue, pp. 1–10.
Pieraccini,R.,Huerta,J.,2005。我们从哪里开始?研究与商业口语对话系统。
载于:Proc.
第5届SIGDIAL话语与对话研讨会,第1-10页。
这种方法实现起来速度很快,
但有一个很大的问题,
复用性很差,
对话模型和领域逻辑严重耦合,
修改对话逻辑必须要修改对话管理的代码,
甚至是从头开发,
对话变更的成本很高,
项目迭代速度很慢。
缺点
1、对话逻辑(领域逻辑)+ 对话管理(对话模型)耦合
2、对话变更成本高、项目迭代速度慢
3、对话调试困难
Programmatic方法 - 编程式对话管理 + 可复用的对话模块
为了提高系统的复用性,
商业公司开发出了很多可以重用的dialog modules,
这些模块封装了对话项目常用的通用组件,
例如超时、取消会话、澄清等,
甚至是一些常用的对话流程,
力争做到只修改部分dialog modules
就可以通过拼接组件的方式完成对话项目的开发。
但这种方法对系统的侵入性仍然很大,
只有自然语言处理专家和系统专家才能使用和维护。
实际情况是,
领域对话的设计者/创作者可能不是程序员,
程序员的职责也不应该是实现对话逻辑,
对话系统的使用和推广成本都很高。
缺点
1、对话逻辑(领域逻辑)+ 对话管理(对话模型)耦合
2、可复用的对话模块: 超时、取消会话、澄清、常用对话流程;
3、系统侵入性大,必须专业技术人士维护;
4、对话逻辑是运营,对话管理是程序员;
5、对话调试困难
需求:对话逻辑和对话模型的解耦
于是将逻辑设计从系统实现中提出来的需求就非常强烈,
这个是任务型机器人发展的一个重大改变,
即对话逻辑和对话模型的解耦(decoupling dialog specification and dialog engine)。
Finite-state graph方法 - 状态机式对话管理
"Finite-state graph"翻译成中文是“有限状态图”。
这是一种数学模型,
用于描述
有限数量的状态及其之间的转换关系。在
计算机科学和自动机理论中,有限状态图常用来表示
有限状态机的行为,用于
建模和分析各种计算过程和语言识别等问题。
为了降低开发成本,
满足交互设计解耦的需求,
基于状态转移的对话系统被开发出来。
一些系统将对话设计和对话管理的工作分离,
领域逻辑由对话交互设计师完成(称为VUI designer),
对话管理模块在运行时解析对话逻辑。
具体来说,
多轮会话用流程拓扑图来表示,
状态节点代表一次对话事件
(可以是等待用户输入并给予回复,
也可以是一次任意响应),
流程图的边代表状态转移条件。
1、流程拓扑图
2、节点:对话事件,如等待用户输入、系统回复
3、边:状态转移条件
设计者用对话流创作工具(一般称为Authoring Tool)定义好交互逻辑后,
创作工具将对话定义转换成一种数据结构或脚本,
用来表示整个状态图。
"Authoring Tool"翻译成中文是“创作工具”或“编辑工具”。
对话run time阶段,
对话管理载入预定义好的流程数据/脚本,
根据实际场景,
执行流程图的响应或跳转。
这类对话系统在90年代非常流行,
例如图2、俄勒冈州研究所推出的CSLU toolkit2,
类似的方法是后来很多其他对话模型的基础,
至今仍有很多公司采用。
Sutton, S.,
Novick, D.,
Cole, R.,and
Fanty, M.,Building 10,000 spoken-dialogue systems.
Proceedings of the International Conference on Spoken Language Processing,
Philadelphia,
PA,
萨顿, S.,
诺维克, D.,
科尔, R.,和
范蒂, M.,构建10,000个口语对话系统。
国际口语处理会议论文集,
费城,
宾夕法尼亚州,
1996年。
对话逻辑设计与对话管理系统分离的模式,
也一直沿用至今,
目前大多商用系统都提供了类似对话流设计工具。
基于状态机的方法擅长处理流程简单、特别是系统主导的任务
另外finite-state方法还引入一个额外的好处,
它一定程度上解决了对话设计debug的困难。
之前讲的用代码实现的方法(programmatic方法),
对话调试就很困难。
虽然软件测试方法很成熟,
但对话逻辑复杂度很高,
多轮交互的路径可能很多,
当测试用例走不通时,
需要仔细检查代码逻辑。
调试人员不仅需要领域对话设计者,
还需要对话系统开发者,
人员成本非常高。
而finite-state方法的拓扑图是独立于底层引擎的,
对话逻辑的debug不需要程序员参与,
对话设计者可以依靠authoring tool查看流程图中每个节点的状态,
也可以对拓扑图进行覆盖率检查1。
Pieraccini,R.,Huerta, J., 2005.Where do we go from here? Research and commercial spoken dialog systems.
In: Proc.
5th SIGDIAL Workshop on Discourse and Dialogue, pp. 1–10.
Pieraccini,R.,Huerta,J.,2005。我们从哪里开始?研究与商业口语对话系统。
载于:Proc.
第5届SIGDIAL话语与对话研讨会,第1-10页。
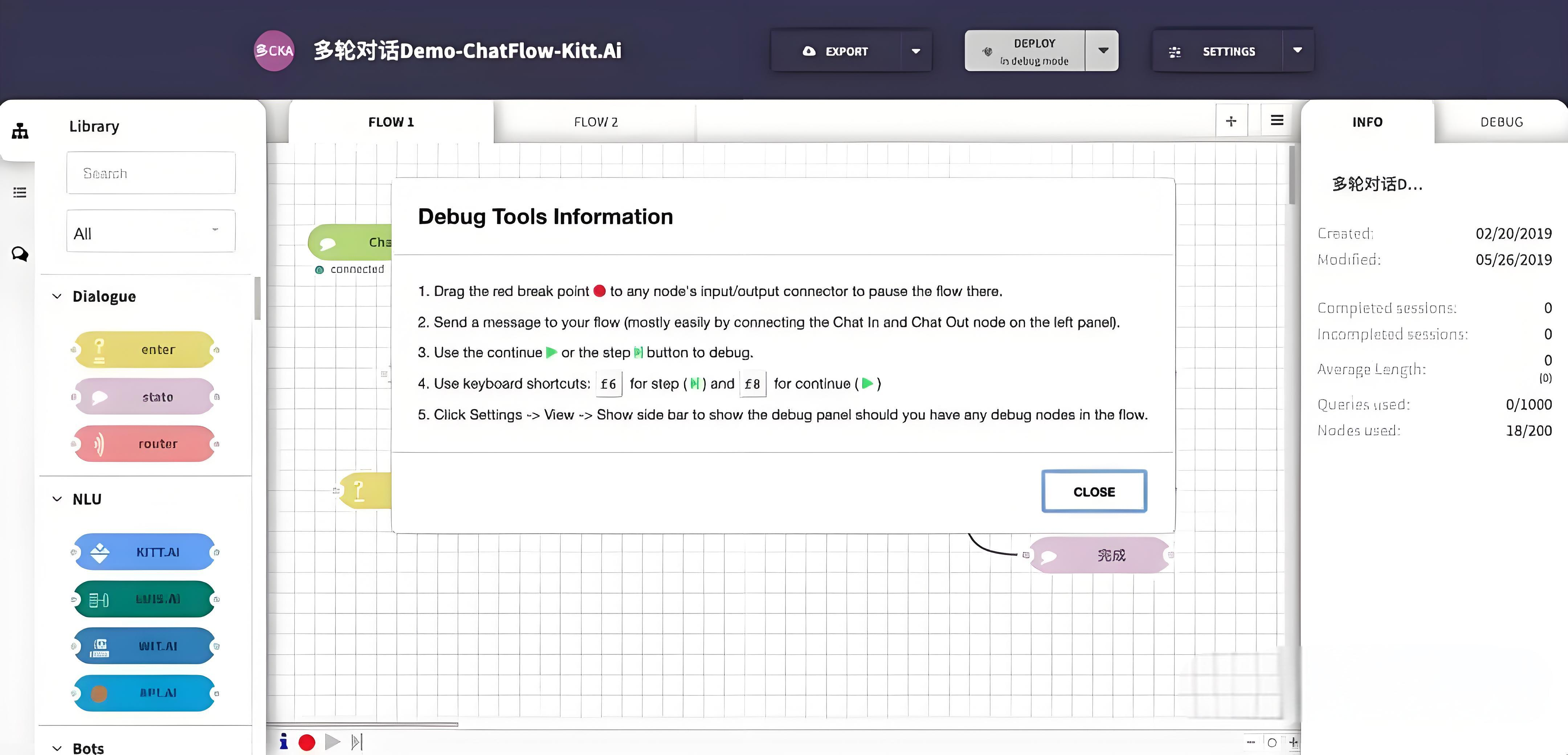
1、Drag the red break point to any node's input/output connector to pause the flow there.
2、Send a message to your flow (mostly easily by connecting the Chat in and Chat Out node on the left panel).
3、Use the continue or the step button to debug.
4、Use keyboard shortcuts(f6) for step and (f8) for continue.
5、Click Setings -> View -> Show side bar to show the debug panel should you have any debug nodes in the flow.
1、将
红色断点拖到任意节点的输入/输出连接器上以暂停该位置的流程。2、向您的流程发送消息(最简便的方式是在
左侧面板上连接聊天输入和聊天输出节点)。3、使用
继续或单步执行按钮进行调试。4、使用键盘快捷键(f6)进行
单步执行,使用(f8)进行继续。5、如果您在流程中有任何调试节点,请点击设置 -> 视图 -> 显示侧边栏以显示
调试面板。
红色断点
继续执行按钮
单步执行按钮
节点面板
调试面板
但finite-state方法非常不灵活,
如果对话任务中
有多个需要用户提供的信息时尤为如此。
举个被用烂的例子,
订机票任务中有四个需要用户提供的信息,
出发地、目的地、日期、确切时间,
一种交互流程是系统依次向用户询问:
出发地 > 目的地 > 日期 > 时间,
designer根据这种交互顺序来创建流程图。
但用户可能在说出发地的时候一并把其他信息也说了,
或者用户对已询问的信息做了修改,
或者用户并没有按要求回答,
也就是说用户可能并没有完全按系统预设的路径走,
即用户主导了对话的进行(user initiative)。
如果finite-state方法需要支持user initiative,
那就需要考虑用户反馈所有可能性,
状态跳转的可能路径会非常多,
对话流会变得非常复杂,
最后变得无法维护3。
McTear,
M.F.Modelling Spoken Dialogues with State Transition Diagrams: Experiences with the CSLU Toolkit.
In Proceedings of 5th International Conference on Spoken Language Processing (ICSLP ’98).
Sydney,
Australia,
Dec 1998.
[3]
McTear,
M.F.使用状态转移图对口语对话进行建模:使用CSLU工具包的体验。
在第五届国际口语处理大会(ICSLP '98)论文集上。
悉尼,
澳大利亚,
1998年12月。
下图是finite-state实现的订机票场景,
虽然考虑了部分user initiative交互,
但仍然存在诸多问题,
第一它并未考虑对话中很多实际情况,系统超时怎么办;
第二实现信息的更新很麻烦,需要在图上把信息更新的交互也画出来;
第三信息收集的过程用图形式实现很繁琐,对话开发效率很低。
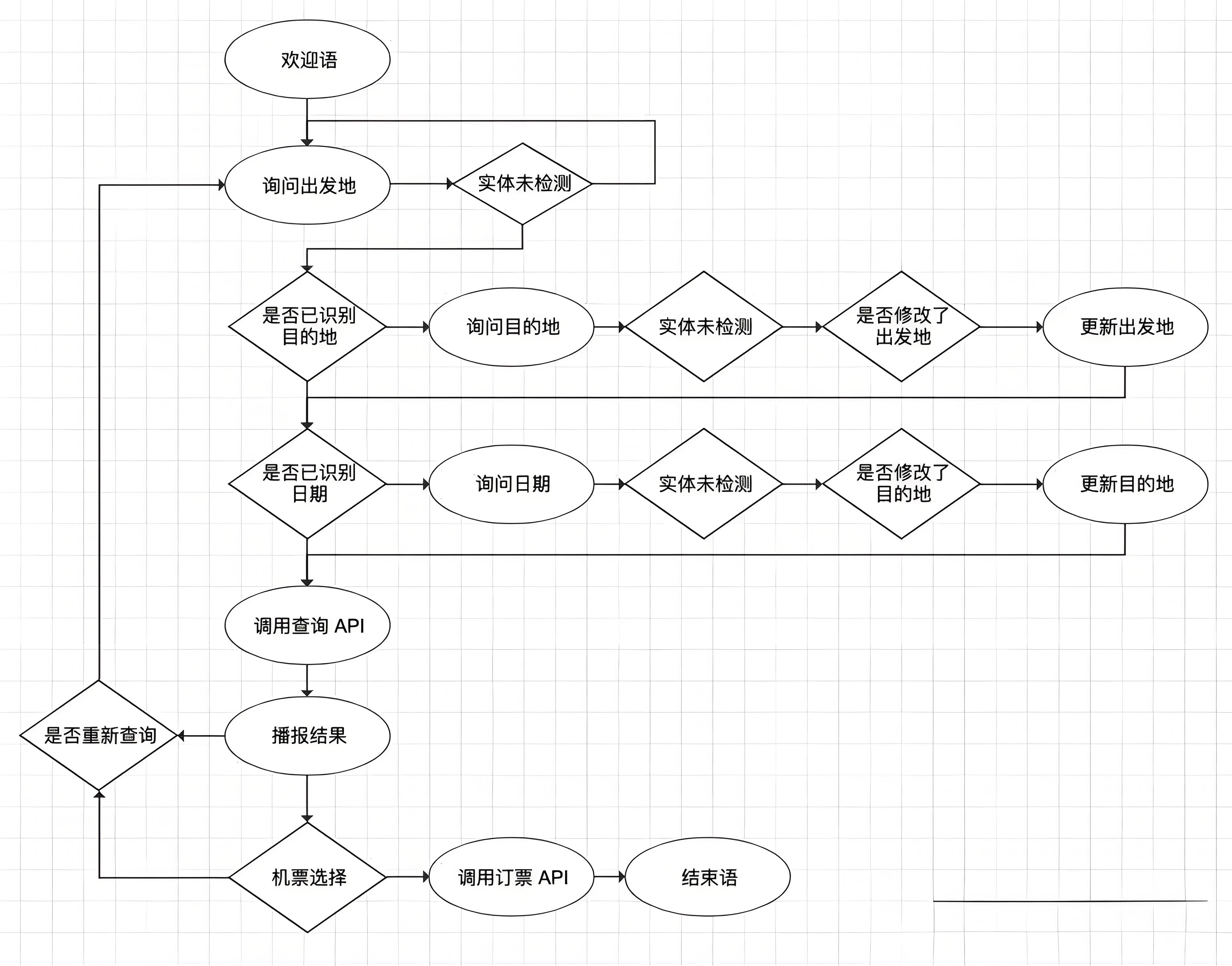
早期我们公司做的任务型对话管理也是用类似的方法,
用对话流表示对话的所有状态和跳转逻辑,
这种方法很类似我们工作中用的流程图,
容易被大家接受、学习成本不高。
有新的对话项目时,
运营同学一般会先画对话交互的visio图,
然后将visio图映射成对话拓扑图,
这个过程比较自然,
运营同学上手很快。
但当对话逻辑很复杂时,
通常初始的visio图考虑不到所有情况,
只包含对话交互一个很小的子集。
当项目上线后(或小范围测试),
运营同学会不断的丰富对话逻辑,
对话拓扑图会越来越大
(对话任务本身有可能并不复杂,
但如果要考虑到所有的交互逻辑,
流程图也会变大非常庞大)。
对话任务本身不复杂
考虑所有交互逻辑,流程图很大;
尤其是遇到刚才提到的任务中
要获取多个信息的场景(即填槽场景),
由于成本太高,
一般我们都不会画出所有的路径,
最后导致开发出来的对话交互在实际运行时比较死板,
让用户觉得很不「智能」。
缺点
1、优点:擅长处理流程简单、系统主导的任务;
2、优点:一定程度解决了对话调试的困难;
3、缺点:非常不灵活,尤其是填槽场景;
4、缺点:对话任务不复杂,考虑所有逻辑就复杂,权衡成本不画所有逻辑,效果不智能
基于Frame的方法 - 填槽式对话管理
一种既能提高灵活性,
又能保持低成本的方法
是基于frame方法。
Frame的概念在人工智能中的应用
可以追溯到马文 · 明斯基(Marvin Minsky)提出的
知识表示框架4。
Minsky, M.A Framework for Representing Knowledge,
in: Winston, O. (Ed.),
The psychology of Computer Vision (McGraw-Hill, NY, 1975).
明斯基, M.知识表示的一个框架,
收录于:温斯顿, O. (主编),
《计算机视觉心理学》(McGraw-Hill, 纽约, 1975)。
Minsky期望用一种数据结构来表示一类情景/场景(a stereotyped situation),
a stereotyped situation: 一种陈规化的情境
这个数据结构被Minsky称为frame,
例如用一个frame表示「去参加孩子的生日派对」这个场景。
Frame的概念后来被迁移到很多理论中,
比如应用到semantic frame5、
semantic network6、
knowledge representation language7等,
但frame本质并没有太大变化,
都可以概括为:
一种用于将知识结构化的数据结构,
这种结构能方便解释、处理和预测信息
a structure that is used to organize our knowledge, as well as for interpreting, processing or anticipating information8。
一个用于
组织我们的知识,以及用于解释、处理或预测信息的结构
Petruck, M.(1996):Frame Semantics,
in:
Verschueren,J.,J-O Östman,J. BlommaertandC. Bulcaen(eds.),Handbook of Pragmatics, 1–13.
Amsterdam: Benjamins.
佩特鲁克, M.(1996):frame语义学,
收录于:
弗斯赫伦,J.、J-O 奥斯特曼、J. 布洛马尔特和C. 布尔卡恩(编),《语用学手册》,1–13。
阿姆斯特丹:本杰明斯出版社。
JF Sowa,Semantic Networks,
http://www.jfsowa.com/pubs/semnet.htm,
[last accessed 10/2/05].
JF Sowa,语义网络,
http://www.jfsowa.com/pubs/semnet.htm,
[最后访问时间 2005年10月2日]。
Daniel G Bobrow,
Ronald M Kaplan,
Martin Kay,
Donald A Norman,
Henry Thompson,and
Terry Winograd.
GUS, a frame-driven dialog system.
Artificial intelligence, 8(2):155–173.
丹尼尔 G. 鲍布罗,
罗纳德 M. 卡普兰,
马丁 凱,
唐纳德 A. 诺曼,
亨利 汤普森,和
特里 维诺格拉德.
GUS,一个基于frame的对话系统。
人工智能,8(2):155–173。
A. GangemiandV. Presutti,Towards a pattern science for the semantic web,
Semantic Web 1(1–2) (2010), 61–68.
A. Gangemi和V. Presutti,迈向语义网的模式科学,
Semantic Web 1(1–2) (2010),61–68。
受到Minsky的启发,
Daniel尝试用一种知识表征语言(knowledge representation language)来构建语言理解系统7,
用陈述性的知识表示来描述人类语言。
Daniel G Bobrow,
Ronald M Kaplan,
Martin Kay,
Donald A Norman,
Henry Thompson,and
Terry Winograd.
GUS, a frame-driven dialog system.
Artificial intelligence, 8(2):155–173.
丹尼尔 G. 鲍布罗,
罗纳德 M. 卡普兰,
马丁 凱,
唐纳德 A. 诺曼,
亨利 汤普森,和
特里 维诺格拉德.
GUS,一个基于frame的对话系统。
人工智能,8(2):155–173。
这套知识表示框架后来被Daniel等人迁移到了人机对话系统,
每一个frame代表会话中的一部分信息,
Daniel假设这样就可以用一系列的frames来
描述并引导人机对话的整个过程。
现在frame-based方法一般被称为槽填充方法,
它用一个信息表维护对话任务中没有顺序依赖的信息,
信息表包含完成对话任务所必需(或可选)的槽位,
该方法的目标就是引导用户回答对话信息表当中的槽位,
一旦信息表填满后,
对话任务所预设的响应将被执行。
用户可以以任意次序提供槽位信息,
顺序的多样性并不增加对话管理的复杂度。
还拿订机票举例,
信息表中的槽位包含
必填槽位: 出发地、目的地和日期,
以及
可选槽位: 时间(当然对于有的机票任务,时间可能是必填项)。
Frame-based方法
将对话开发者
从路径跳转设计中解放出来,
一个简单的信息表就能代替信息收集的流程图。
任务信息表被对话管理的槽填充模块解析,
根据解析的数据类型,
填写不同的槽位,
并且支持对槽位的修改更新。
槽填充的实现方法有很多,
常见的方法是
用树结构表示一个frame,
根节点为frame的名字,
叶子节点表示槽位,
槽填充通过不断遍历叶节点,
执行未填充叶节点的响应(例如一段机器回复),
直到一棵树被填充完整为止。
Frame-based方法提出后
被应用到很多商用对话系统中,
工业界对话系统的标准语言-语音标记语言VoiceXML就
主要基于frame-based方法。
VoiceXML的对话逻辑用XML来定义,
frame(在VoiceXML中被称为form)是XML文档的核心组成部分,
其FIA(Form Interpretation Algorithm,表单解析算法)算法
通过不断遍历frame中所有槽位,
找到未填充槽位后,
将其对应的回复(prompt)输出给TTS,
TTS生成一段语音给用户,
一种FIA实现可见下图。
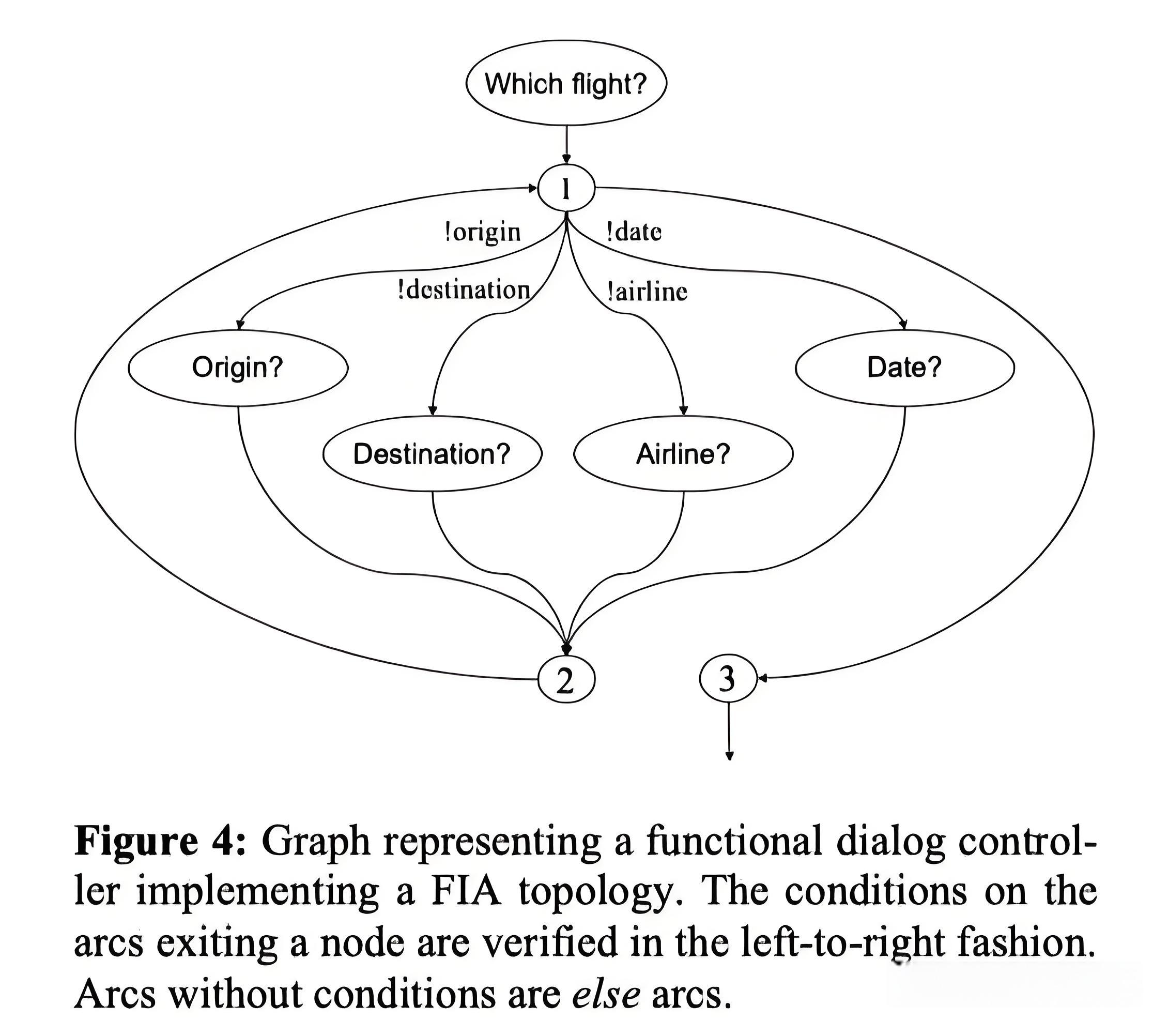
Figure 4:
Graph representing a functional dialog controller implementing a FIA topology.
图表展示了实现
FIA拓扑的功能性对话控制器。
The conditions on the arcs exiting a node are verifed in the left-to-right fashion.
从节点发出的弧上的条件是从左到右的方式验证的。
Arcs without conditions are else arcs.
没有条件的
弧是另一种类型的弧。
下图是IBM Watson Assistant槽填充界面
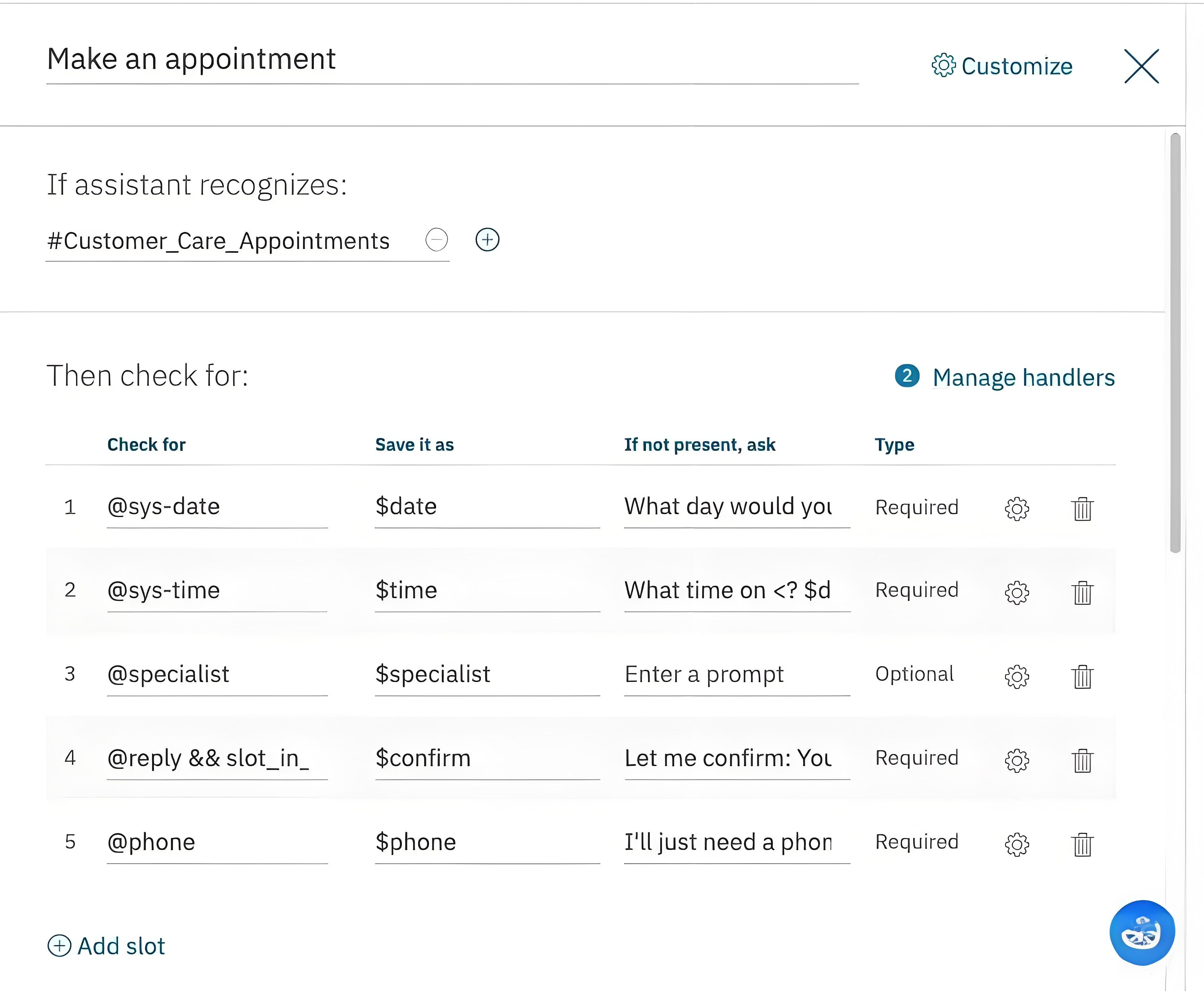
make an appointment
if assistant recognizes:
customer_care_appointments
@sys-date $date
@sys-time $time
@specialist $specialist
@reply && slot_in_
@phone
对话交互中的任务被一个个的frame表单表示,
frame之间通过特定跳转逻辑连接,
或用一个流程图来连接,
一个多任务的对话项目就能快速开发出来。
现在大多通用chatbot/智能对话平台仍然会采用槽填充方法,
例如图6 IBM Watson的对话配置界面。
面试题
槽位和变量的关系是什么?
缺点
1、优点:将对话开发者从路径跳转设计中解放出来
2、缺点:frame解决一些固定逻辑的任务
基于目标的方法
从上面的三种方法的发展趋势来看,
提高对话逻辑的灵活性一直是推动人机对话系统前进的一个重要动力。
上面讨论了,
早期对话描述直接嵌入在代码中,
修改和维护非常不便。
后来研究者将其抽象成流程拓扑图,
虽然降低了对话开发的耦合度,
但由于人类对话的复杂和多样性,
流程图难以低成本地覆盖足够多的状态跳转。
为了再一次提高对话描述的抽象层次,
研究者引入frame数据结构来表示固定的对话任务,
将特定任务的对话逻辑隐藏在frame框架中。
基于frame的方法主要解决了一些固定逻辑的任务,
但对话管理不仅处理一个个小的对话任务,
还需要考虑对话任务的顺序、任务的层级结构、任务之间的场景切换,
以及能动态添加新任务的机制。
1、对话任务的顺序
2、任务的层级结构
3、任务之间的场景切换
4、动态添加新任务
在90年代研究者提出了一种新的人机对话模式 - 基于目标的方法,
这种方法将人类的沟通模式迁移到了人机对话当中。
Charles Rich等人认为
人机交互的核心在于
交互双方通过不断调整各自的行为,
合作完成一个共同目标,
并假设当机器遵守人类交流的规则和习惯时,
使用者将更容易学习使用这个交互系统9。
任务型的对话就很适合这个理论。
Rich, C.,
Sidner, C., 1998.COLLAGEN: a collaboration manager for software interface agents.
An International Journal: User Modeling and User–Adapted Interaction 8 (3/4), 315–350.
Rich, C.,
Sidner, C.,1998。COLLAGEN:一个用于软件界面代理的协作管理器。
国际期刊:用户建模与用户适应交互 8 (3/4),315–350。
对于任务型对话,
虽然可以假设user在使用对话系统前就已经有清晰的目标,
但对话过程肯定不是一帆风顺,
对话多样性太复杂,
例如:
用户并不会按照一个固定的流程进行对话、
用户可能想修改之前的一些选择、
系统也可能因为误识别而出现信息不对称,
对话目标也可能涉及到多个对话任务、
对话任务之间的关系可能是多样的,
这些都需要交互双方根据实际情况,
动态调整交互行为,
而这些都无法靠一个静态的流程图和一个个预配置好的frames来实现。
为了在人机对话中实现目标合作理论,
Grosz等人将任务型对话结构分成三个部分:
用来表示语言序列的结构(linguistic structure,语言结构),
用来表示对话意图的结构(intentional structure,意图结构),
和用来表示当前对话焦点的状态(attentional state,注意力状态)[^10]。
对话结构 = 序列结构 + 意图结构 + 焦点状态
Grosz假设
任务型的对话结构
可以按意图/目标(purpose)
划分成
多个相互关联的子段落(segment),
每个segment表示一个目标,
segment中可以嵌套更小的segment表示更小一级的子目标。
这样对话就可以看成多层级的结构。
一个对话对应一个主要目标,
其下划分成的多个段落,
对应多个子目标。
在对话进行的过程中,
每一时刻交互
双方都会将注意力集中到一个目标。
根据实际情况,
下一时刻双方可能还在沟通这个目标,
也可能聚焦到另外一个目标,
对话焦点在对话期间会动态地变化,
直到完成对话中所有的子目标,
对话沟通就完成了。
简单理解,
linguistic structure就表示对话的段落(segment)结构,
intentional structure即表示对话的意图结构,
attentional state指的就是每一个时刻的对话焦点。
根据基于目标的对话理论框架,
研究者们开始考虑
如何将其应用到人机对话系统,
典型的代表有Collagen9和RavenClaw[^11]。
要实现基于目标的对话理论,
首先需要考虑用什么样的方式来表示这样的对话结构。
一般的做法是,
用树(tree)表示整个对话的组织结构,
用栈(stack)维护对话进行中每一时刻的对话焦点,
用字典(dict)存储对话栈中每个对话目标所依赖的信息。
由于一个对话任务的总目标总是可以拆分成多个小目标,
所以对话目标可以看成一个层次结构,
这就很适合用树形结构表示。
举个实际例子,
这次我们不再用订机票、订酒店这类被用烂的例子,
我们拿一个简化版的信用卡还款业务来做示例。
如图7,
这个对话主要目标是信用卡还款,
为了完成主要目标,
对话被分成了多个小目标(可以暂且称为二级目标),
分别是:
用户初始化、获取账号信息、询问还款信息、还款操作,以及结束语。
为了完成对话的二级目标,
也可以继续将目标拆分成三级目标,
这样整个对话的多层次树结构就出来了。
在RavenClaw中,
树结构中的节点分成两类,
一类是叶节点 - 响应节点(图7中灰色部分),
代表无法再进行拆分的对话响应,
例如调取一个API、回复用户一段话等等。
另一类是非叶节点 - 控制节点(图7中白色节点),
它的职责是控制子节点在对话运行时的状态,
封装抽象程度更高的对话目标。
对话的树形结构包含了整个对话的任务说明(dialog specification),
但在对话运行时如何解析这个specification,
就需要另一个数据结构:对话栈(dialog stack)。
为了实现Grosz提出的对话焦点的理论,
系统从左向右依次遍历整个对话树,
每一时刻将一个节点送入stack,
这个节点在该时刻就成了对话焦点(dialog focus)。
每一时刻系统将执行栈顶focus节点的响应,
当节点的状态为「已完成」时,系统将该节点出栈,
下一个节点成为栈顶focus节点,
以此系统可将对话树中所有节点的操作执行完。
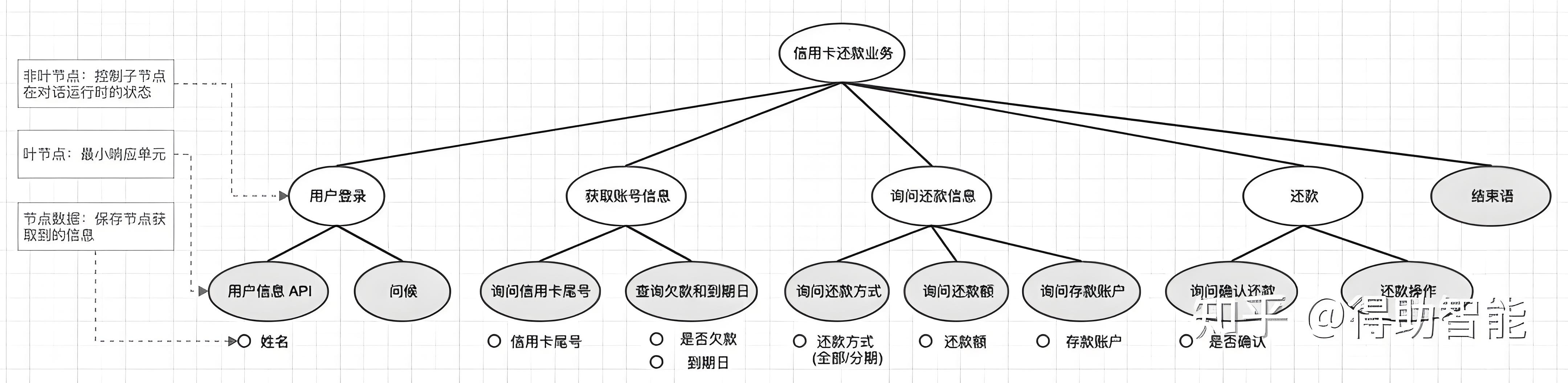
我们还以信用卡还款业务为例,
图中时刻1
信用卡还款root节点入栈,
系统执行根节点的操作,
注意控制节点(非叶节点)的action就是
将其子节点从左至右依次送入stack,
所以时刻2「用户登录」节点入栈。
同样的逻辑,
时刻3「用户信息API」节点入栈,
由于该节点为叶节点,
响应操作是调用API,
执行完该操作后,
「用户信息API」节点状态被标记为「已完成」,
该节点被系统出栈。
时刻4,
执行「用户登录」节点,
将其未完成的子节点「问候」入栈,
系统回复一个问候语后,
该节点被标记完成并出栈。
下一时刻,
由于「用户登录」所有子节点都已完成,
则该节点也被标记完成并出栈。
就这样,
系统依次遍历对话树所有节点,
直到所有节点都标记为「已完成」,
该任务对话运行结束。















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









