










 本文深入探讨了HTTP协议中GET和POST方法的本质区别,从RFC标准出发,解析了它们的安全性、幂等性和缓存性特征。并通过报文格式对比,澄清了常见误区,如参数长度限制和TCP数据包数量。
本文深入探讨了HTTP协议中GET和POST方法的本质区别,从RFC标准出发,解析了它们的安全性、幂等性和缓存性特征。并通过报文格式对比,澄清了常见误区,如参数长度限制和TCP数据包数量。
这篇文章传播得超广的,https://mp.weixin.qq.com/s?__biz=MzI3NzIzMzg3Mw==&mid=100000054&idx=1&sn=71f6c214f3833d9ca20b9f7dcd9d33e4#rd 好多回答都是这个版本,它提到:
GET和POST还有一个重大区别,
简单的说:GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,
服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,
浏览器再发送data,服务器响应200 ok(返回数据)。
而在W3school中关于 POST 和 GET 的区别的描述是这样的:
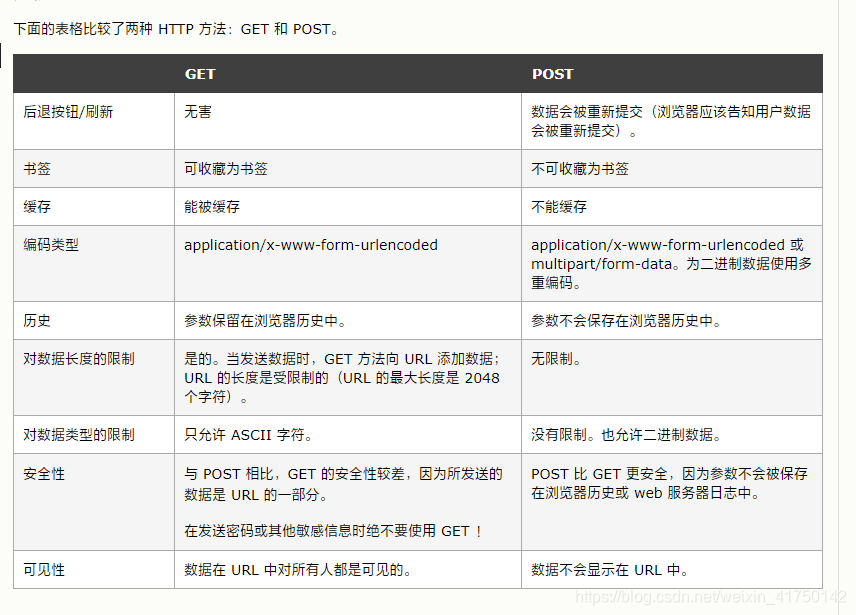
与此同时,又有些文章表示上述区别是浏览器与服务器限制导致的,从 RFC (Request For Comments,是一系列以编号排定的文件。文件收集了有关互联网相关信息,以及UNIX和互联网社区的软件文件。RFC文件是由Internet Society(ISOC)赞助发行。基本的互联网通信协议都有在RFC文件内详细说明) 看来, POST 和 GET 的区别并不是上述,因此… … 我看了 RFC 的说明:(不打算看文档的直接看高亮内容即可。)
(链接🔗在此:https://tools.ietf.org/html/rfc2616#section-9.3)
一、从 RFC 上看
1.RFC中对于 GET 方法的描述:
GET方法表示检索任何信息(作为实体),由Request-URI标识。
如果请求URI引用,对于数据生成过程,应将生成的数据作为响应中的实体返回,而不是处理后的源文档,除非该文档恰好是处理的输出。
( 原谅我渣翻译,原文是这样的: it is the produced data which shall be
returned as the entity in the response and not the source text of the
process, unless that text happens to be the output of the process.)
(1) 如果GET方法的语义更改为“条件GET”,请求消息包括If-Modified-Since,If-Unmodified-Since,If-Match,If-None-Match或If-Range标头字段。
有条件的GET方法(“conditional GET”)要求仅在 条件标头字段描述的情况,旨在减少不必要的网络.
通过允许高速缓存的实体无需刷新即可使用多个请求 或 传输已由客户端保存的数据。
(2)如果GET方法的语义更改为“部分GET”, 请求消息包含范围标头字段。部分GET请求仅转移实体的一部分。部分GET方法旨在减少不必要的 通过允许部分取回的实体成为网络来使用,无需传输客户端已经拥有的数据即可完成。
( The conditional GET method is intended to reduce unnecessary network usage by allowing cached entities to be refreshed without requiring
multiple requests or transferring data already held by the client.)
对GET请求的响应只有在满足HTTP缓存要求时才可缓存。
(好些狗屁不通的话,实在是我翻译能力有限QAQ)
2.RFC中对 POST 方法的描述:
POST 方法用于请求原始服务器接受请求中包含的实体作为资源的新下属,由请求行中的Request-URI标识。
POST被设计允许采用统一的方法来覆盖以下功能:
-注释现有资源;
-将消息发布到公告板,新闻组,邮件列表,
或类似的文章;
-提供数据块,例如提交数据的结果
形式,到数据处理过程;
-通过附加操作扩展数据库。
POST方法执行的实际功能由服务器,通常取决Request-URI。
过帐的实体从属于该URI的方式,与从属于文件的方式相同。
在包含该目录的目录中,新闻文章从属于发布到的新闻组,或记录从属于数据库。
POST方法执行的操作可能不会导致可以由URI标识的资源。在这种情况下,无论是200(OK)或204(No Content)是适当的响应状态,
取决于响应是否包括一个实体描述结果。
如果在原始服务器上创建了资源,则响应应该为201(已创建),并包含描述
请求的状态,并引用新的资源和位置。
对此方法的响应是不可缓存的,除非响应 包含适当的Cache-Control 或Expires头字段。然而,303 (See Other)响应可用于将用户代理定向到 检索可缓存的资源。
POST请求必须遵守规定的消息传输要求。
安全注意事项见15.1.3节。
3.RFC 中关于 安全 和 幂等方法 的描述
9.1安全和幂等方法
9.1.1安全方法
实施者应注意,该软件代表用户,他们在互联网上的互动,因此应谨慎允许用户要意识到他们可能会执行的任何操作对自己或他人的意想不到的意义。
特别是,已经约定,GET、 HEAD方法 不应该采取行动,除了检索。 这些方法应该被认为是“安全的”。
这允许用户代理代表其他方法,例如POST,PUT 和DELETE(以一种特殊方式),以便使用户知道事实,要求采取可能不安全的措施。
自然,不可能确保服务器不会由于执行GET请求而产生副作用;在实际上,一些动态资源认为该功能。重要的这里的区别是用户没有要求副作用,
因此,不能对他们负责。
(
Safe - 安全.
这里的「安全」和通常理解的「安全」意义不同,如果一个方法的语义在本质上是「只读」的,那么这个方法就是安全的。
客户端向服务端的资源发起的请求如果使用了是安全的方法,就不应该引起服务端任何的状态变化,因此也是无害的。
此RFC定义,GET, HEAD, OPTIONS 和 TRACE 这几个方法是安全的。
但是这个定义只是规范,并不能保证方法的实现也是安全的,服务端的实现可能会不符合方法语义,正如上文说过的使用GET修改用户信息的情况。
引入安全这个概念的目的是为了方便网络爬虫和缓存,以免调用或者缓存某些不安全方法时引起某些意外的后果。User Agent(浏览器)应该在执行安全和不安全方法时做出区分对待,并给用户以提示。
)
9.1.2等幂方法
方法还可以具有“幂等”的特性。
多次请求与单个请求相同产生的副作用相同。(除了错误或到期问题)GET,HEAD方法、PUT 和 DELETE 共享此属性。另外,方法OPTIONS 和 TRACE不应有副作用,因此是固有幂等的。
(
Idempotent - 幂等。
幂等的概念是指同一个请求方法执行多次和仅执行一次的效果完全相同。
按照RFC规范,PUT,DELETE和安全方法都是幂等的。
同样,这也仅仅是规范,服务端实现是否幂等是无法确保的。
引入幂等主要是为了处理同一个请求重复发送的情况,比如在请求响应前失去连接,如果方法是幂等的,就可以放心地重发一次请求。这也是浏览器在后退/刷新时遇到 POST 会给用户提示的原因:POST语义不是幂等的,重复请求可能会带来意想不到的后果。
)
(再有一个 缓存性
Cacheable - 可缓存性 。
顾名思义就是一个方法是否可以被缓存,此RFC里GET,HEAD和某些情况下的POST都是可缓存的,但是绝大多数的浏览器的实现里仅仅支持GET和HEAD。)
从 RFC 标准上来看,GET 和 POST 的区别如下:
(1)GET 用于获取信息,是无副作用的,是幂等的,且可缓存
POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存
GET 和 POST 只是 HTTP 协议中两种请求方式,而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。
二、从 报文上看
从报文的角度看,GET 和 POST 方法没有实质区别,只是报文格式不同。
报文格式上,不带参数时,最大区别 就是第一行方法名不同。
(1)POST方法请求报文第一行是这样的 POST /uri HTTP/1.1 \r\n
(2)GET方法请求报文第一行是这样的 GET /uri HTTP/1.1 \r\n
不带参数时他们的区别就仅仅是报文的前几个字符不同而已。
带参数时报文的区别呢? 在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中。
举个例子,如果参数是 name=qiming.c, age=22。
GET 方法简约版报文是这样的
GET /index.php?name=qiming.c&age=22 HTTP/1.1
Host: localhost
POST 方法简约版报文是这样的
POST /index.php HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
name=qiming.c&age=22
两种方法本质上是 TCP 连接,没有差别,也就是说,如果我不按规范来也是可以的。我们可以在 URL 上写参数,然后方法使用 POST;也可以在 Body 写参数,然后方法使用 GET。当然,这需要服务端支持。、
三、常见问题
1.GET 方法参数写法是固定的吗?
在约定中,我们的参数是写在 ? 后面,用 & 分割。
我们知道,解析报文的过程是通过获取 TCP 数据,用正则等工具从数据中获取 Header 和 Body,从而提取参数。
也就是说,我们可以自己约定参数的写法,只要服务端能够解释出来就行,一种比较流行的写法是 http://www.example.com/user/name/chengqm/age/22。
2.POST 方法比 GET 方法安全?
按照网上大部分文章的解释,POST 比 GET 安全,因为数据在地址栏上不可见。
然而,从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。
要想安全传输,就只有加密,也就是 HTTPS。
3.GET 方法的长度限制是怎么回事?
在网上看到很多关于两者区别的文章都有这一条,提到浏览器地址栏输入的参数是有限的。
HTTP 协议没有 Body 和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因。
浏览器原因就不说了,服务器是因为处理 长 URL 要消耗比较多的资源,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
4.POST 方法会产生两个TCP数据包?
有些文章中提到,post 会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body。
HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且实际测试(Chrome)发现,header 和 body 不会分开发送。
所以,header 和 body 分开发送是部分浏览器或框架的请求方法,不属于 post 必然行为。
talk is cheap show me the code
如果对 get 和 post 报文区别有疑惑,直接起一个 Socket 服务端,然后封装简单的 HTTP 处理方法,直接观察和处理 HTTP 报文,就能一目了然
import socket
HOST, PORT = '', 23333
def server_run():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print('Serving HTTP on port %s ...' % PORT)
while True:
# 接受连接
client_connection, client_address = listen_socket.accept()
handle_request(client_connection)
def handle_request(client_connection):
# 获取请求报文
request = ''
while True:
recv_data = client_connection.recv(2400)
recv_data = recv_data.decode()
request += recv_data
if len(recv_data) < 2400:
break
# 解析首行
first_line_array = request.split('\r\n')[0].split(' ')
# 分离 header 和 body
space_line_index = request.index('\r\n\r\n')
header = request[0: space_line_index]
body = request[space_line_index + 4:]
# 打印请求报文
print(request)
# 返回报文
http_response = b"""\
HTTP/1.1 200 OK
<!DOCTYPE html>
<html>
<head>
<title>Hello, World!</title>
</head>
<body>
<p style="color: green">Hello, World!</p>
</body>
</html>
"""
client_connection.sendall(http_response)
client_connection.close()
if __name__ == '__main__':
server_run()
上面代码就是简单的打印请求报文然后返回 HelloWorld 的 html 页面,我们运行起来:
[root@chengqm shell]# python httpserver.py
Serving HTTP on port 23333 ...
然后从浏览器中请求看看
打印出来的报文
然后就可以手动证明上述说法,比如说要测试 header 和 body 是否分开传输,由于代码没有返回 100 状态码,如果我们 post 请求成功就说明是一起传输 (Chrome/postman)。
又比如 w3school 里面说 URL 的最大长度是 2048 个字符,那我们在代码里面加上一句计算 uri 长度的代码
#解析首行
first_line_array = request.split('\r\n')[0].split(' ')
print('uri长度: %s' % len(first_line_array[1]))
我们用 postman 直接发送超过 2048 个字符的请求看看
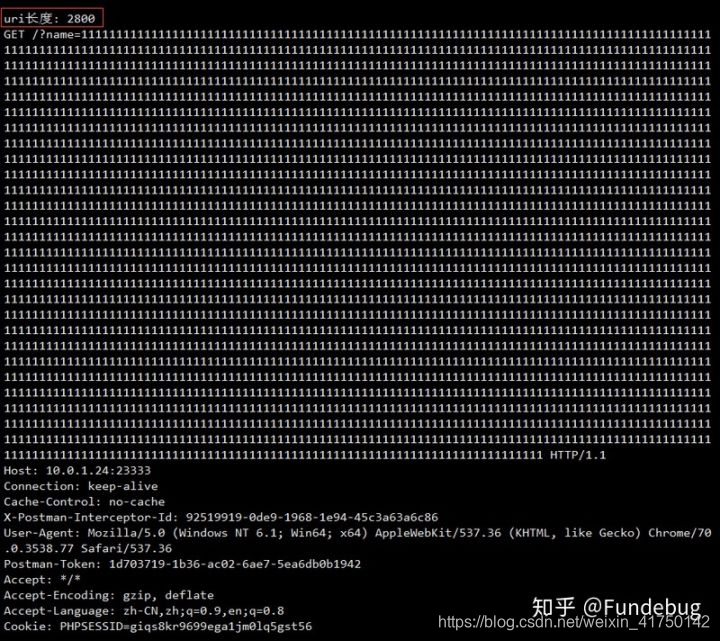
然后我们可以得出结论,url 长度限制是某些浏览器和服务器的限制,和 HTTP 协议没有关系。
本篇博客引用了下述链接:
GET 和 POST 到底有什么区别? - 杨光的回答 - 知乎
https://www.zhihu.com/question/28586791/answer/145424285
https://tools.ietf.org/html/rfc2616#section-9.3


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









