






数据处理
使用数据——ipinyou 1458数据集,包含train.log.txt和test.log.txt等。
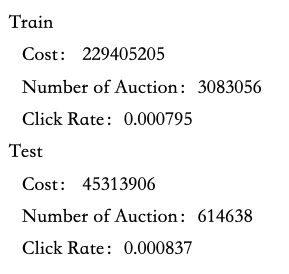
1、统计数据分布,观察数据
2、用RL模型做简单的ctr预测,得到pctr
3、将时间按照十五分钟为间隔划分,即一天96个时段,两天就192个时段,以此类推
4、数据列表[click, pctr, payprice, timestep]

代码编写
1、出价计算规则
def bid_func(pctrs, lamda):
lamda_list.append(lamda)
return pctrs / lamdavalue的计算可以通过pctr来衡量,每一个时段调整一次来调整出价,调整率即对应的action为:
[-0.08, -0.03, -0.01, 0, 0.01, 0.03, 0.08]2、设计DQN网络和RewardNet网络
两个网络结构相同,原本想在训练的时候给每一层做归一化处理的,但是后来代码出了问题就没有再改这里了。
class Net(nn.Module):
def __init__(self, feature_numbers, reward_numbers):
super(Net, self).__init__()
# 第一层网络的神经元个数,第二层神经元的个数为动作数组的个数
neuron_numbers_1 = 100
# 第二层网络的神经元个数,第二层神经元的个数为动作数组的个数
neuron_numbers_2 = 100
self.fc1 = nn.Linear(feature_numbers, neuron_numbers_1)
self.fc1.weight.data.normal_(0, 0.1) # 全连接隐层 1 的参数初始化
self.bn1 = nn.BatchNorm1d(num_features=neuron_numbers_1, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
self.fc2 = nn.Linear(neuron_numbers_1, neuron_numbers_2)
self.fc2.weight.data.normal_(0, 0.1) # 全连接隐层 2 的参数初始化
self.bn2 = nn.BatchNorm1d(num_features=neuron_numbers_2, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
self.fc3 = nn.Linear(neuron_numbers_1, neuron_numbers_2)
self.fc3.weight.data.normal_(0, 0.1) # 全连接隐层 2 的参数初始化
self.bn3 = nn.BatchNorm1d(num_features=neuron_numbers_2, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
self.out = nn.Linear(neuron_numbers_2, reward_numbers)
self.out.weight.data.normal_(0, 0.1)
def forward(self, input):
x_1 = self.fc1(input)
x_1 = F.relu(x_1)
x_2 = self.fc2(x_1)
x_2 = F.relu(x_2)
x_3 = self.fc3(x_2)
x_3 = F.relu(x_3)
actions_value = self.out(x_3)
return actions_value3、训练
每次都将参数重新初始化,包括,如果不重新初始化lamda,很可能会因为一开始学坏了导致后面一直学坏。
因为每一次存储到记忆池的数据都是[state, action, reward, next_state],因此每一次都需要计算下一个时段的state。代码实现的时候是先计算的前一个时段,得到前一个时段的state,action,reward,在合并当前时段进行存储,这样在处理循环结构的时候更方便。
# 第一个时段另外计算
auc_t_datas = train_data[train_data.iloc[:, 3].isin([1])]
auc_t_data_pctrs = auc_t_datas.iloc[:, 1].values
# 观测当前状态
last_state_t, B_t, last_reward_t, t_clks, bid_arrays, t_win_imps, t_real_imps, t_real_clks, t_spent \
= state_(budget, auc_t_datas, auc_t_data_pctrs, lamda_t_next, B_t, 1, action, config['train_step'])
# 执行动作
lamda_t_next = lamda_t_next * (1 + action)
#观测当前状态
state_t, B_t, reward_t, t_clks, bid_arrays, t_win_imps, t_real_imps, t_real_clks, t_spent\
= state_(budget, auc_t_datas, auc_t_data_pctrs, lamda_t_next, B_t, t+1, action, config['train_step'])
# 存储记录到回忆池
experience = np.hstack((last_state_t, action, reward_t, state_t))
RL.store_transition(experience)















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









