







官网地址:https://pocketflow.github.io/
1、Pocketflow介绍
深度学习模型压缩和加速的开源模型框架
易使用:开发者只需要指定需要的压缩和加速率,然后pocketflow会自动选择合适的超参数来生成压缩模型。
2、框架组成
由两部分组成:学习模块和超参数优化模块。
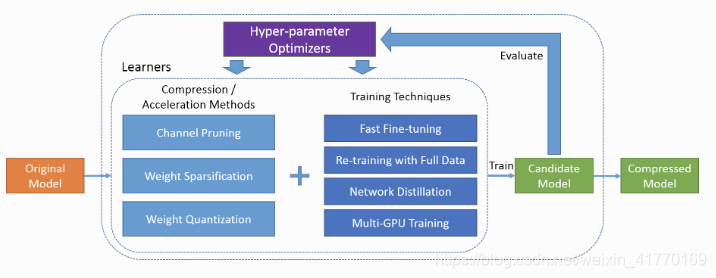
初始模型,经过学习模块后,使用一些随机选择的超参数来产生候选的压缩模型。候选模型的精度和计算效率作为超参数优化模块的输入,来决定下一次学习模块的超参数选择。
经过多次上述迭代,最优的候选模型作为最终输出的压缩模型。
(1)学习模块
学习模块是指一些模型压缩方法。pocketflow目前支持的模型压缩算法如下:
剪枝、权重稀疏和量化,通过剪枝mask或者量化函数实现。生成的模型可以通过小数据集进行部分迭代即可快速finetune。也可以通过完整的训练集进行finetune,这样精度更高,但耗时更长。

整体总结如下:
| 压缩方法 | 描述 |
| 通道剪枝(2种) | 2017/2018 |
| 权重稀疏 | 2018 |
| 权重量化(3种) | 2018/TF/2016 |
| 网络蒸馏 | 为进一步降低精度损失,将压缩前模型的输出作为参考,来指导压缩模型的训练。 |
| 多GPU训练 | 加快训练速度 |
(2)超参数优化模块
压缩算法的超参数很难人工设定,尤其是对于不熟悉算法细节的开发者。Google的Cloud AutoML可以实现很好人工干预的算法训练。2018年的AMC提出一种用于通道剪枝和finetune剪枝的自动模型压缩方法。
Pocketflow介绍一种迭代获取最优超参数的方法。首先提供一些基于GP/TPE/DDPG等模型的超参数优化器,然后通过迭代的方式进行超参数优化。
每一个迭代:
超参数优化模块选择一些超参数的组合
学习模块通过快速tune的方式产生一个候选的压缩模型
候选模型被用来评估当前超参数的选择,超参数模块更新模型,产生更好的超参数
多个迭代后,选出最优模型。
这个模型可以通过使用全部的训练数据训练,从而降低损失。
3、表现
列举了剪枝和权重稀疏前后的精度对比,没有说速度。
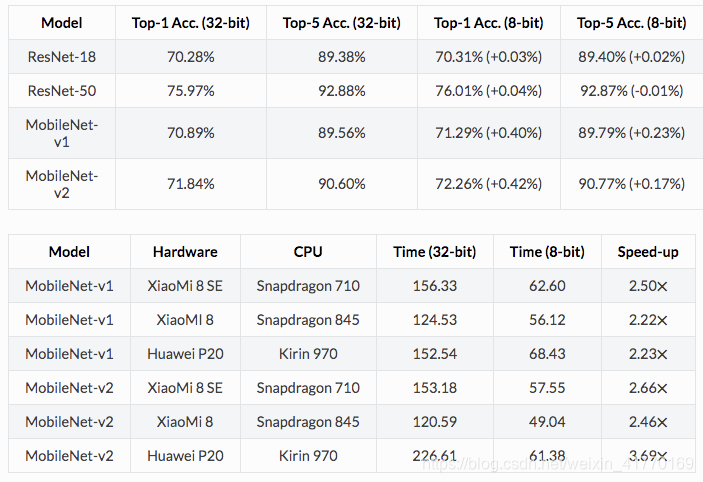
如下是权重量化的对比结果:
看小模型mobilenet表现,8bit量化前后,精度不仅无损失还有所提高;同时速度提升2倍多。
我这里要做的是对keras的xception进行优化。因此,第一步采用8bit量化。如果能有2倍提升,已经可以初步满足要求了。如果还需要提升速度,再来考虑剪枝和权值稀疏。

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









