






目录
论文:https://arxiv.org/pdf/1904.05059.pdf
摘要
年龄检测是计算机视觉的传统学习问题。目前有很多大而深,性能好的卷积模型,比如:AlexNet, VggNet, GoogleNet, ResNet。然而,这些模型对于嵌入式/移动设备来说是无法使用的。近来,一些参数更少,更轻量级的模型被提出,比如mobilenet和shufflenet。但是,由于深度可分离卷积的使用使他们的表征被弱化了。这篇论文中,我们调研了小模型对小尺度图像的限制,提出了一种基于内容的集联小模型进行年龄估计:C3AE。提出的模型参数是mobilenet和shufflenet的1/9,vggnet的1/2000,同时性能也很有竞争力。我们通过集联模型的方式,用2点表示来定义年龄估计问题;并且,为了更好的利用面部上下文信息,提出多分支CNN网络来联合多尺度上下文信息。最后通过在3个数据集上进行验证,提出的小模型性能达到最优。
1、介绍
近年来,为了达到更高的精度,CNN越来越深,越来越大。这导致训练和部署的代价越来越大。尤其是,鉴于模型大小和计算消耗的角度,部署现有的传统大模型,比如:Alexnet,VggNet,ResNet到移动手机,汽车以及机器人上,几乎是不可能的。
为了解决这个问题,近来提出了通过深度可分离卷积来减少参数的mobielenet,shufflenet模型。在这些模型中,传统的卷积层被拆成2个卷积:过滤层和合并层。比如,mobilenet中,过滤层先分别卷积通道,能够减少很多参数。再通过1*1卷积合并个输入通道。对于大尺度的图像来说,由于图像需要通过大量的通道的来表示,因此这样的操作是合理的。比如VggNet的512个卷积和ResNet的384个卷积。然而,对于小尺度图像,比如低分辨率低纬度的图片,这样的预测需要打个❓。
与大尺度图像对比,用来表征小尺度图像的网络通道更少,参数和占用内存也更少。因此,小卷积核的标准卷积层和深度可分离卷积比起来,不需要更多的参数和内存。从图像表征来说,深度可分离卷积的输出通道比标准卷积要大很多倍。为了增强表征能力,深度可分离卷积的参数会不断增加。因此,我们相信,小卷积核的标准卷积层比深度可分离卷积更适合处理小尺度的图像。
我们经常会碰到需要用低性能的设备来存储和处理低分辨率、低尺度的图像。其中一个很突出的问题就是年龄估计。比如,人能够很容易的从图1的不同部分、分辨率的图片中估计出年龄。因此,我们猜测,CNN也具备这样的能力,设计一个使用标准卷积层的小型网络,用小尺度图像作为输入的年龄估计。

图1
最近的年龄估计通常可以分为2大类:(1)联合分类和回归,(2)分布匹配。对于(1),心理学表明,人们更倾向于给出分类而不是连续的年龄值。【Hao Liu, Jiwen Lu, Jianjiang Feng, and Jie Zhou. Ordinal deep feature learning for facial age estimation. In FGR, 2017. 2, 8】和【Songhe Feng, Congyan Lang, Jiashi Feng, Tao Wang, and Jiebo Luo. Human facial age estimation by cost-sensitive label ranking and trace norm regularization. IEEE Transactions on Multimedia, 19(1):136–148, 2017. 2, 8】使用了类别信息和序列信息进行分类和回归。对于(2),如果每张图像的类别分布都能提供,则可以取得很好的效果。但是,获取成千上万个人脸的类别分布是一个不可能的任务。在这篇论文中,我们通过联合分类,回归和标签分布来获取信息。可以通过在2个离散年龄level上将离散年龄值作为分布,训练的目标是最小化这些分布的匹配。在深度回归模型中,在特征层和年龄预测层之间,插入一个有语义分布的全连接层。
总结一下,我们设计了一个将小尺度图像作为输入的紧凑模型。特别的,我们使用了合适的核和通道数的标准卷积层,而不是深度可分离卷积层。据我们了解,这是目前位置人脸识别最小的模型,简单模型大小为0.19M,全模型大小为0.25M。然后,我们将离散年龄值作为一个分布,并设计了一个集联模型。另外,我们引入了一个基于内容的回归模型,将多个尺度的面部图像作为输入。通过这个紧凑的基础模型,集联训练和多尺度内容,我们能够进行小尺度图像的年龄估计。我们将这个模型称之为:C3AE。
我们的贡献如下。(1)我们学习了通道数和深度可分离卷积表征能力之间的关系,尤其是对于小尺度图像。我们的讨论和结果建议大家重新思考mobilenets和shufflenets对中小尺度图像的使用。(2)我们提出了一种融合分类,回归和标签分布来获取信息的年龄估计方法,并且设计了一个集联模型。(3)我们通过提出基于上下文的年龄预测方法,将不同尺度的图像作为输入。这个提出的模型叫C3AE,与紧凑模型相比,取得了最好成绩,甚至超过了很多大模型的性能。由于模型大小很小(0.19M精简版,0.25M全模型),C3AE能够很好的部署到移动端和嵌入式平台。
2、相关工作
年龄估计
年龄增长带来的面部变化是不可控,且个性化的,并且传统方法通常泛化不好。由于深度学习的应用,最近,在分类,语义分割,目标检测等应用,CNN都取得了非常好的成绩。对于年龄估计,CNN也由于强大的泛化能力得到了应用。【[39] Dong Yi, Zhen Lei, and Stan Z Li. Age estimation by multiscale convolutional network. In ACCV, 2015. 2】使用CNN模型,从几个面部区域中抽取特征,再用一个平方损失进行年龄估计。【[18] Gil Levi and Tal Hassner. Age and gender classification using convolutional neural networks. In CVPRW, 2015. 2】通过一个一维的年龄分组进行年龄分类。【[29] Rasmus Rothe, Radu Timofte, and Luc Van Gool. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vision (IJCV), 126(2- 4):144–157, 2016. 2, 5, 8】提出使用softmax概率和离散年龄值进行年龄估计。这是一个在测试阶段加权的softmax分类器。【[24] Zhenxing Niu, Mo Zhou, Le Wang, Xinbo Gao, and Gang Hua. Ordinal regression with multiple output cnn for age estimation. In CVPR, 2016. 2, 5, 8】通过多输出的CNN,将年龄估计作为一种顺序回归。延续[24]的思路,【[3] Shixing Chen, Caojin Zhang, Ming Dong, Jialiang Le, and Mike Rao. Using ranking-cnn for age estimation. In CVPR, 2017. 2, 8】使用一种排序CNN进行年龄估计,通过一系列基本CNN,联合得到最后的估计。【[9] Hu Han, Anil K Jain, Fang Wang, Shiguang Shan, and Xilin Chen. Heterogeneous face attribute estimation: A deep multi-task learning approach. IEEE Trans. on Pattern Analysis and Machine Intelligence, 40(11):2597–2609, 2018. 2】使用多属性进行多任务学习。【[6] Bin-Bin Gao, Chao Xing, Chen-Wei Xie, Jianxin Wu, and Xin Geng. Deep label distribution learning with label ambiguity. IEEE Trans. on Image Processing, 26(6):2825–2838, 2017. 2, 4】使用KL差异来评估预测年龄和实际年龄分布之间的相似性。【[25] Hongyu Pan, Hu Han, Shiguang Shan, and Xilin Chen. Mean-variance loss for deep age estimation from a face. In CVPR, 2018. 2, 4, 8】对分布学习设计了一个新的均值方差的损失函数。
然而,在实际应用中,人脸图像的分布通常是不可用的。在这篇论文中,我们同时考虑两个目标。(1)最小化分布间的KL(Kullback-Leibler,相对墒)损失。(2)最优化不同离散年龄值之间的平均损失。
紧凑模型
由于移动端/嵌入式设备跑深度学习的应用越来越多,提出了很多有效的模型,比如:GoogleNet,SqueezeNet, ResNet和SeNet等来满足这些需求。近来,深度可分离卷积在mobilenet和shufflenet中得到应用,从而来减少运算量和模型大小。他们的模型结构主要是开始引入深度可分离卷积,再使用Inception模型来减少计算量。特别的,将卷积通道分成过滤和应用。基于深度可分离卷积的mobilenet-v1lshufflenetv1使用有效的point-wise组卷积和通道shuffle在保持精度的同时减少计算量。mobilenet-v2提出一个基于线性的瓶颈的翻转残留。shufflenet-v2主要是分析模型的速度, 并给出有效模型设计的基线。
对于年龄估计,我们认为,对于小尺度图像的通道数一般都不多,深度可分离卷积并不合适。标准卷积对于精度和紧凑的折衷是满足条件的。
3、提出的模型
在这个部分,我们首先提出紧凑模型和结构,以及对于目前应用的一些讨论。接着,描述年龄的2点表征,使用集联方式进行插入。接下来,基于3种尺度的上下文信息作为一个回归模型的输入。最后,我们会给出一些讨论和思考。
3.1 对于小尺度图像的紧凑模型:标准卷积
我们提出的精简模型由5个标准卷积和2个全连接层构成。标准卷积层后加BN,Relu和平均池化。卷积核大小,通道数和参数分别为3,32和9248。作为一个基本模型,我们展示了为什么我们使用标准卷积而不是mobilenet和shufflenet中使用的可分离卷积。

在MobileNet中,分析参数和计算保存的状态,尤其是标准卷积和深度可分离卷积之间的对比。这个分析表明,深度可分离卷积对于大尺度图像是适合的,但是对于中小尺度图像效果并不好。
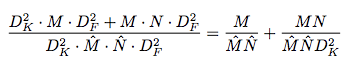
同样的效果,如果深度可分离卷积要实现和标准卷积一样的效果,需要更多的channel。
3.2 年龄的2点表示
这里提出将年龄表现看成在2个离散相邻饼的分布。
我的理解:每一个年龄都得到2个分组及其概率值,再通过加权得到最后的年龄值。
3.3 集联训练
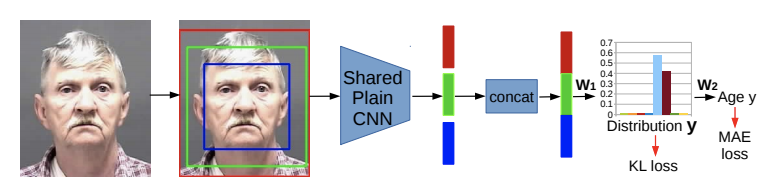
图2

训练的时候,采用了2个损失函数。w1:KL相对墒,w2:MAE。
![]()
3.4 基于上下文的回归模型
见图2,将输入从一个尺度的剪切改成3个尺度的联合信息。
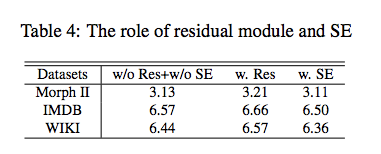
residual残留块:是否有必要用resnet中的residual模块,residual模块是用来解决深层模型中的梯度消失问题。对于小模型来说,本身就很少,没必要做residual。
SE模块:注意力机制引入。对大、小尺度图片都适用。对模型大小的影响很小。
4、实验
实验分成3部分。(1)使用基础模型与SSRNET,MobielentNet-V2和Shufflenet-V2进行对比。(2)集联模块和基于上下文模型的必要性;(3)与其他算法的对比。
4.1 数据集
wiki, morph2, fg-net
4.2 实现细节
学习率,迭代数等设置
4.3 学习
4.3.1 基础模型
描述标准卷积的性能由于mobilenetv2和shufflenet-v2的深度可分离卷积。

另外,Residual模块和SE模块是否有效:只用SE模块即可。
4.3.2 集联和基于内容的模块
没有集联,只有集联,集联+上下文。第三种效果最好。

4.4 与其他模型的对比:Morph2
















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









