







 本文探讨了在SQL查询中,WHERE子句与HAVING子句在处理分组查询时的效率差异。尽管两者都能实现对分组结果的过滤,但在任何可能的情况下,应优先使用WHERE,因为它通常具有更高的效率。WHERE在分组前进行筛选,而HAVING则在分组后过滤,因此在不需要使用分组函数的条件下,WHERE更为高效。然而,当筛选条件涉及分组函数时(如平均薪资),就必须使用HAVING来完成查询。
本文探讨了在SQL查询中,WHERE子句与HAVING子句在处理分组查询时的效率差异。尽管两者都能实现对分组结果的过滤,但在任何可能的情况下,应优先使用WHERE,因为它通常具有更高的效率。WHERE在分组前进行筛选,而HAVING则在分组后过滤,因此在不需要使用分组函数的条件下,WHERE更为高效。然而,当筛选条件涉及分组函数时(如平均薪资),就必须使用HAVING来完成查询。
MYSQL笔记-关于分组查询中的where和having效率问题
前言
最近在学习SQL语法时,遇到了一个where和having的效率问题,感觉非常值得注意,所以记录下来便于复习和与各位网友分享。
结论放前面
时间紧迫的同学可以直接看结论,where和having都可以达到对分组查询后的结果再过滤的目的,但在任何情况下请优先考虑使用where,where处理不了的再使用having,因为where的效率更高。
情景
现在有一张表emp,存储的数据分别为empno(员工编号),ename(员工姓名),job(岗位),mgr(上级领导工号),hiredate(入职日期),sal(工资),comm(补贴),depto(部门编号)。
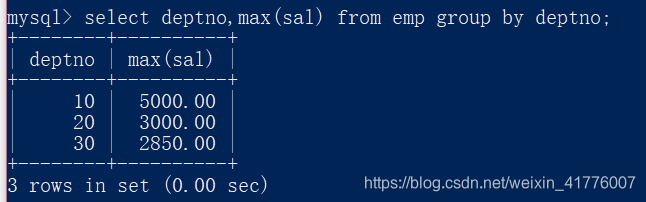
要求1:找出每个部门最高薪资
解答:可以很容易的写出sql语句select deptno,max(sal) from emp group by deptno;
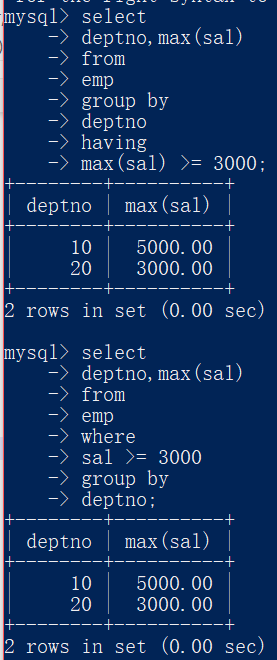
要求2:找出每个部门最高薪资,显示其中大于等3000的。
解答1:select deptno,max(sal) from emp group by deptno having max(sal) >= 3000;
解答2:select deptno,max(sal) from emp where sal >= 3000 group by deptno;
使用以上2条sql语句都能得到结果:
问题
select deptno,max(sal) from emp group by deptno having max(sal) >= 3000;
select deptno,max(sal) from emp where sal >= 3000 group by deptno;
以上两条语句的操作过程是怎么样的?效率是否有区别?
1、select deptno,max(sal) from emp group by deptno having max(sal) >= 3000;
先按照分组查询emp表中的全部数据,显示出每一个deptno中最大的sal,再执行having语句筛选分组查询结果中大于等于3000的数据。
分组时给到了分组查询操作表内所有数据,然后再对分组查询结果进行筛选。
2、select deptno,max(sal) from emp where sal >= 3000 group by deptno;
先对emp表中的数据进行筛选选出其中sal大于等于3000的,再按照分组查询显示每一个deptno中最大的sal。
分组时直接给到了表中符合要求的数据,分组查询结果就是我们要的结果。
结论
很明显,使用where的语句执行过程中减少了最后对分组查询结果的二次筛选,使得sql语句的效率比使用having更高,因此在开发过程中我们要有意识优先使用where来解决分组查询结果筛选的问题。
但是,当筛选条件为需使用到分组函数时我们就只能使用having来做二次筛选,因为sql查询语句中的执行顺序为:1. from 2. where 3. group by 4. select 5. order by。在group by分组前无法使用分组函数,所以二次筛选条件自然不能写在where中。
就像下面的这个情景:找出每个部门平均薪资,要求显示平均薪资高于2500的数据。
就只能使用having来解决问题:select deptno,avg(sal) from emp group by deptno having avg(sal) > 2500;


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









