



参考
计算病理学——图像分割的评价指标梳理
mIoU及pixel accuracy |图像语义分割/语义图像生成中的评估指标 | 公式解析附代码
AJI
AJI(Aggregated Jaccard Index )增强版的IOU,基于连通域的图像分割结果评判
Aggregated Jaccard Index
公式:

关键词在于,连通域。具体讲解可以参考参考链接。
计算代码参考 hovernet 中的实现 (https://github.com/vqdang/hover_net/tree/master/metrics)
def get_fast_aji_plus(true, pred):
"""AJI+, an AJI version with maximal unique pairing to obtain overall intersecion.
Every prediction instance is paired with at most 1 GT instance (1 to 1) mapping, unlike AJI
where a prediction instance can be paired against many GT instances (1 to many).
Remaining unpaired GT and Prediction instances will be added to the overall union.
The 1 to 1 mapping prevents AJI's over-penalisation from happening.
Fast computation requires instance IDs are in contiguous orderding i.e [1, 2, 3, 4]
not [2, 3, 6, 10]. Please call `remap_label` before hand and `by_size` flag has no
effect on the result.
给出的 true, pred 中的数值必须是连续的 0,1,2,3这种,不能是跳跃的整数。
"""
true = np.copy(true) # ? do we need this
pred = np.copy(pred)
true_id_list = list(np.unique(true))
pred_id_list = list(np.unique(pred))
true_masks = [
None,
]
for t in true_id_list[1:]:
t_mask = np.array(true == t, np.uint8)
true_masks.append(t_mask)
pred_masks = [
None,
]
for p in pred_id_list[1:]:
p_mask = np.array(pred == p, np.uint8)
pred_masks.append(p_mask)
# prefill with value
pairwise_inter = np.zeros(
[len(true_id_list) - 1, len(pred_id_list) - 1], dtype=np.float64
)
pairwise_union = np.zeros(
[len(true_id_list) - 1, len(pred_id_list) - 1], dtype=np.float64
)
# caching pairwise
for true_id in true_id_list[1:]: # 0-th is background
t_mask = true_masks[true_id]
pred_true_overlap = pred[t_mask > 0]
pred_true_overlap_id = np.unique(pred_true_overlap)
pred_true_overlap_id = list(pred_true_overlap_id)
for pred_id in pred_true_overlap_id:
if pred_id == 0: # ignore
continue # overlaping background
p_mask = pred_masks[pred_id]
total = (t_mask + p_mask).sum()
inter = (t_mask * p_mask).sum()
pairwise_inter[true_id - 1, pred_id - 1] = inter
pairwise_union[true_id - 1, pred_id - 1] = total - inter
#
pairwise_iou = pairwise_inter / (pairwise_union + 1.0e-6)
#### Munkres pairing to find maximal unique pairing
paired_true, paired_pred = linear_sum_assignment(-pairwise_iou)
### extract the paired cost and remove invalid pair
paired_iou = pairwise_iou[paired_true, paired_pred]
# now select all those paired with iou != 0.0 i.e have intersection
paired_true = paired_true[paired_iou > 0.0]
paired_pred = paired_pred[paired_iou > 0.0]
paired_inter = pairwise_inter[paired_true, paired_pred]
paired_union = pairwise_union[paired_true, paired_pred]
paired_true = list(paired_true + 1) # index to instance ID
paired_pred = list(paired_pred + 1)
overall_inter = paired_inter.sum()
overall_union = paired_union.sum()
# add all unpaired GT and Prediction into the union
unpaired_true = np.array(
[idx for idx in true_id_list[1:] if idx not in paired_true]
)
unpaired_pred = np.array(
[idx for idx in pred_id_list[1:] if idx not in paired_pred]
)
for true_id in unpaired_true:
overall_union += true_masks[true_id].sum()
for pred_id in unpaired_pred:
overall_union += pred_masks[pred_id].sum()
#
aji_score = overall_inter / overall_union
return aji_score
举例子我们需要计算的 true, pred 分别为
true = np.array([[1, 1, 1],
[0, 1, 1],
[1, 0, 2]])
pred = np.array([[0, 1, 1],
[0, 0, 0],
[0, 0, 1]])
计算步骤为
1、对真实值的每个 instance_id(除了背景0),遍历 pred 中的不同 instance,计算各自的intersection,union, IoU
2、对每个 instance_id, 取 IoU 最大的形成配对
然后把配好对的 intersection加在分子上,再把配好对的 union 加在分母上
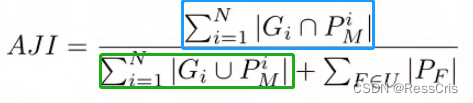
3、将没有配对的部分加在分母上
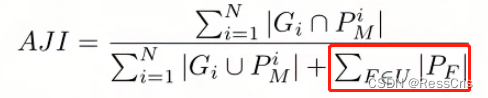
回到刚刚的案例
因为 true 除了0之外有两个 instance id,遍历pred计算两两 intersection,两两 union 分别为:
注意,这里描述的mask是指只有 0,1 取值的mask。也就是 true_instance 1 = np.where(true1, 1, 0); true_instance 2= np.where(true2, 1, 0). * 代表两个矩阵对应位置元素相乘。
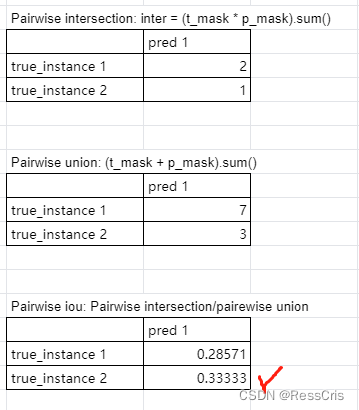
由 IoU 最大选择配对,即 true_instance2 和 pred 1配对成功。

这里的计算和公式似乎有点不符,公式中未配对的部分计算的是 pred 中的id,但是代码中计算的是 true 中的id?这块的理解需要注意。
DICE
Metric评价指标-Dice 与损失函数-Dice Loss
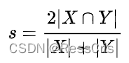
hovernet 中给出了两份代码计算
def get_dice_1(true, pred):
"""Traditional dice."""
# cast to binary 1st
true = np.copy(true)
pred = np.copy(pred)
true[true > 0] = 1
pred[pred > 0] = 1
inter = true * pred
denom = true + pred
return 2.0 * np.sum(inter) / np.sum(denom)
####
def get_dice_2(true, pred):
"""Ensemble Dice as used in Computational Precision Medicine Challenge."""
true = np.copy(true)
pred = np.copy(pred)
true_id = list(np.unique(true))
pred_id = list(np.unique(pred))
# remove background aka id 0
true_id.remove(0)
pred_id.remove(0)
total_markup = 0
total_intersect = 0
for t in true_id:
t_mask = np.array(true == t, np.uint8)
for p in pred_id:
p_mask = np.array(pred == p, np.uint8)
intersect = p_mask * t_mask
if intersect.sum() > 0:
total_intersect += intersect.sum()
total_markup += t_mask.sum() + p_mask.sum()
return 2 * total_intersect / total_markup
get_dice_1 将所有不是大于0的数都设置为1,然后进行计算。
get_dice_2 则分别处理了不同的 instance,提取每个 instance 的mask分别计算,相当于取了一个加权平均。
不过看其他的计算方法中,在 pred 中可以是预测的概率,直接点乘法,而不需要转换为 mask 0,1 取值的方式。

参考 dice loss 的实现
def dice_loss(true, pred, smooth=1e-3):
"""`pred` and `true` must be of torch.float32. Assuming of shape NxHxWxC."""
inse = torch.sum(pred * true, (0, 1, 2))
l = torch.sum(pred, (0, 1, 2))
r = torch.sum(true, (0, 1, 2))
loss = 1.0 - (2.0 * inse + smooth) / (l + r + smooth)
loss = torch.sum(loss)
return loss
Panoptic Quality
可以参考这篇 panoptic-segmentation-the-panoptic-quality-metric
来自论文 hovernet
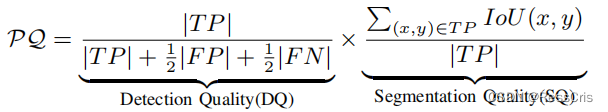

在 AJI 中计算的这个示例中,由于两个 inter 值都不超过 0.5, 所以值都是0.
所以可以看到, PQ值首先对IoU的设定设置了门槛。
def get_fast_pq(true, pred, match_iou=0.5):
"""`match_iou` is the IoU threshold level to determine the pairing between
GT instances `p` and prediction instances `g`. `p` and `g` is a pair
if IoU > `match_iou`. However, pair of `p` and `g` must be unique
(1 prediction instance to 1 GT instance mapping).
If `match_iou` < 0.5, Munkres assignment (solving minimum weight matching
in bipartite graphs) is caculated to find the maximal amount of unique pairing.
If `match_iou` >= 0.5, all IoU(p,g) > 0.5 pairing is proven to be unique and
the number of pairs is also maximal.
Fast computation requires instance IDs are in contiguous orderding
i.e [1, 2, 3, 4] not [2, 3, 6, 10]. Please call `remap_label` beforehand
and `by_size` flag has no effect on the result.
Returns:
[dq, sq, pq]: measurement statistic
[paired_true, paired_pred, unpaired_true, unpaired_pred]:
pairing information to perform measurement
"""
assert match_iou >= 0.0, "Cant' be negative"
true = np.copy(true)
pred = np.copy(pred)
true_id_list = list(np.unique(true))
pred_id_list = list(np.unique(pred))
true_masks = [
None,
]
for t in true_id_list[1:]:
t_mask = np.array(true == t, np.uint8)
true_masks.append(t_mask)
pred_masks = [
None,
]
for p in pred_id_list[1:]:
p_mask = np.array(pred == p, np.uint8)
pred_masks.append(p_mask)
# prefill with value
pairwise_iou = np.zeros(
[len(true_id_list) - 1, len(pred_id_list) - 1], dtype=np.float64
)
# caching pairwise iou
for true_id in true_id_list[1:]: # 0-th is background
t_mask = true_masks[true_id]
pred_true_overlap = pred[t_mask > 0]
pred_true_overlap_id = np.unique(pred_true_overlap)
pred_true_overlap_id = list(pred_true_overlap_id)
for pred_id in pred_true_overlap_id:
if pred_id == 0: # ignore
continue # overlaping background
p_mask = pred_masks[pred_id]
total = (t_mask + p_mask).sum()
inter = (t_mask * p_mask).sum()
iou = inter / (total - inter)
pairwise_iou[true_id - 1, pred_id - 1] = iou
if match_iou >= 0.5:
paired_iou = pairwise_iou[pairwise_iou > match_iou]
pairwise_iou[pairwise_iou <= match_iou] = 0.0
paired_true, paired_pred = np.nonzero(pairwise_iou)
paired_iou = pairwise_iou[paired_true, paired_pred]
paired_true += 1 # index is instance id - 1
paired_pred += 1 # hence return back to original
else: # * Exhaustive maximal unique pairing
#### Munkres pairing with scipy library
# the algorithm return (row indices, matched column indices)
# if there is multiple same cost in a row, index of first occurence
# is return, thus the unique pairing is ensure
# inverse pair to get high IoU as minimum
paired_true, paired_pred = linear_sum_assignment(-pairwise_iou)
### extract the paired cost and remove invalid pair
paired_iou = pairwise_iou[paired_true, paired_pred]
# now select those above threshold level
# paired with iou = 0.0 i.e no intersection => FP or FN
paired_true = list(paired_true[paired_iou > match_iou] + 1)
paired_pred = list(paired_pred[paired_iou > match_iou] + 1)
paired_iou = paired_iou[paired_iou > match_iou]
# get the actual FP and FN
unpaired_true = [idx for idx in true_id_list[1:] if idx not in paired_true]
unpaired_pred = [idx for idx in pred_id_list[1:] if idx not in paired_pred]
# print(paired_iou.shape, paired_true.shape, len(unpaired_true), len(unpaired_pred))
#
tp = len(paired_true)
fp = len(unpaired_pred)
fn = len(unpaired_true)
# get the F1-score i.e DQ
dq = tp / (tp + 0.5 * fp + 0.5 * fn)
# get the SQ, no paired has 0 iou so not impact
sq = paired_iou.sum() / (tp + 1.0e-6)
return [dq, sq, dq * sq], [paired_true, paired_pred, unpaired_true, unpaired_pred]
计算步骤
1、和 AJI 一样,都是先计算两两 pairwise_iou
2、根据 IoU > 0.5, 选择好配对.
3、计算F1score, SQ,得到结果。
[目标检测/实例分割评价指标] mAP
https://zhuanlan.zhihu.com/p/462844609
mmdetection 中好像就用了这个指标。
mIoU(语义分割)
语义分割中的标准评估指标,评估粒度是类别。
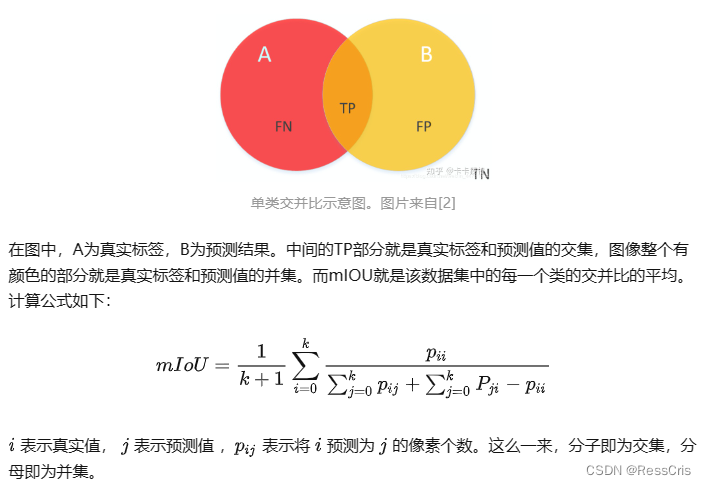 、
、
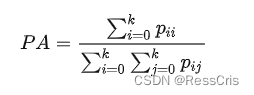
Pixel accuracy解析(语义分割)
Pixel Accuracy (PA)即像素准确率,很明显就是预测像素的准确率高低的评价标准。方法也很简单: PA = 预测正确像素个数 / 总预测像素个数。公式写成:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











