







 本文深入探讨了排序算法,包括直观的选择排序和插入排序,以及高效的归并排序、堆排序和快速排序。分析了这些算法的时间复杂度、空间复杂度和稳定性,并举例说明了如何在特定情况下优化排序算法,如内省排序和蒂姆排序。此外,还提出了赛跑问题和区间排序的解决方案,展示了解决此类问题的思路。
本文深入探讨了排序算法,包括直观的选择排序和插入排序,以及高效的归并排序、堆排序和快速排序。分析了这些算法的时间复杂度、空间复杂度和稳定性,并举例说明了如何在特定情况下优化排序算法,如内省排序和蒂姆排序。此外,还提出了赛跑问题和区间排序的解决方案,展示了解决此类问题的思路。
1.4 关于排序的讨论
排序算法:
人们曾经研究最多的一类算法
依然是最基础的、在程序中使用频率最高的算法之一
排序算法根据时间复杂度分两类:
- 复杂度为 O ( N 2 ) O(N^2) O(N2)的算法
- 复杂度为 O ( N l o g N ) O(NlogN) O(NlogN)的算法
1.4.1 直观的排序算法时间到底浪费在哪里
(1)选择排序 (Selection Sort)
步骤
- 从1~N,比较相邻两个元素,若前一个元素比后一个大,则这两个元素位置互换;
- 从1~N-1,重复步骤1;
- 从1~N-2,继续重复上述步骤,直到扫描N次,得到的结果就是从小到大排列的数组。
时间复杂度
( N − 1 ) + ( N − 2 ) + . . . + 1 = N ( N − 1 ) / 2 = O ( N 2 ) (N-1) + (N-2) + ... + 1 = N(N-1)/2 = O(N^2) (N−1)+(N−2)+...+1=N(N−1)/2=O(N2)
代码实现
# python
def selection_sort(nums):
for i in range(len(nums), 1, -1):
for j in range(0, i-1):
if nums[j] > nums[j+1]:
temp = nums[j]
nums[j] = nums[j+1]
nums[j+1] = temp
return nums
# example
nums = [12, 9, 3, 6, 7, 14, -6, 13, 24, 7, 6, -9, 5, 0, 5, 6, 14, 16, 12, 18, 18]
print(selection_sort(nums))
代码运行结果:

分析
“最坏”的排序算法,因为在一个长为N的数组中挑出最大的那个数,最多需要进行 O ( N ) O(N) O(N)次操作,整个数组最多这样重复 N N N次,也就排好序了。所以 O ( N 2 ) O(N^2) O(N2)可以说是排序算法的上界。
(2)插入排序 (Insert Sort)
步骤
对于未排序数组,不断从后向前扫描,对于每一个扫描的元素,找到相应的位置插入:小的数字插入数组的前面,大的插入后面(像打扑克牌时的抓牌过程)。所有的元素扫描一遍,全部插入相应的位置,也就实现了排序。
时间复杂度
仍然是
O
(
N
2
)
O(N^2)
O(N2)
原因:插入的这个动作复杂度是
O
(
N
)
O(N)
O(N),因为插入时需要插入位置后面所有的元素都后移一位。所以即使数组只扫描一遍,时间复杂度并没有改变。
代码实现[1]
# python
def insert_sort(nums):
for i in range(1, len(nums)):
temp = nums[i]
j = i -1
while j>=0 and temp < nums[j]:
nums[j+1] = nums[j]
j -= 1
nums[j+1] = temp
return nums
# example
nums = [12, 9, 3, 6, 7, 14, -6, 13, 24, 7, 6, -9, 5, 0, 5, 6, 14, 16, 12, 18, 18]
print(insert_sort(nums))
代码运行结果:

分析
虽然从前向后只扫描了一遍数据,但是插入的时候从后向前需要再扫描一遍数据给需要插入的数据腾出位置,所以算法复杂度依然是 O ( N 2 ) O(N^2) O(N2)。
讨论
(1)和(2)两种算法做了很多次无谓的比较和数据的移动:
选择排序中,
- 将所有数字都两两比较了一次,没有必要,因为如果已经比较出 X < Y , Y < Z X < Y, Y< Z X<Y,Y<Z, 那就没有必要再比较 X X X和 Z Z Z了。
- 做了很多无谓的位置互换,假如一个数组已经是从大到小的逆序状态了,此时第一、二个数据的有效移动都应该是往后移,但是选择排序的第一步是把第二个数据往前移到第一个的位置,属于无用功。
插入排序中,
- 数字的比较虽然比选择排序少,但也是 O ( N ) O(N) O(N)级的
- 为了给某个数腾出位置,做了太多无用的数据移动
1.4.2 有效的排序算法效率来自哪里
(1)归并排序 (Merge Sort)
提出人:冯·诺伊曼(于1945年。分治算法和递归的典型应用。)
步骤
- 假设序列 a [ 1 , . . . , N ] a[1, ..., N] a[1,...,N]前后两部分分都是排好序的,将其分成前后两个数组 b 和 c b和c b和c,接下来采用一步归并操作,把这两个子序列合并起来;
- 若 b [ 1 ] < c [ 1 ] b[1] < c[1] b[1]<c[1],则 a [ 1 ] = b [ 1 ] a[1]=b[1] a[1]=b[1],否则 a [ 1 ] = c [ 1 ] a[1]=c[1] a[1]=c[1];
- a [ 2 ] = m i n ( b [ 2 ] , c [ 1 ] ) a[2]=min(b[2], c[1]) a[2]=min(b[2],c[1]),如果送进 A A A序列的元素是 b [ 2 ] b[2] b[2],则下一次比较 b [ 3 ] 和 c [ 1 ] b[3]和c[1] b[3]和c[1],如此重复下去。
- 若最后 C C C序列中元素都已经放完了,而 B B B序列中剩余的元素已经排好序,且都比 A A A序列中的元素大,直接将这些元素放在 A A A序列末尾即可。
(其中 B , C B, C B,C序列的排序过程采用递归算法即可)
时间复杂度
递归次数 O ( l o g N ) O(logN) O(logN),每次递归的计算量都是 O ( N ) O(N) O(N),所以时间复杂度是 O ( N l o g N ) O(NlogN) O(NlogN)。
代码实现[2]
# python
def merge_sort(nums):
if len(nums) <= 1:
return nums
mid = len(nums) // 2
left = merge_sort(nums[: mid])
right = merge_sort(nums[mid:])
return merge(left, right)
def merge(left, right):
result = [] # 这里新建了个list,存储空间额外占用 O(N)
i = 0
j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
nums = [12, 9, 3, 6, 7, 14, -6, 13, 24, 7, 6, -9, 5, 0, 5, 6, 14, 16, 12, 18, 18]
print(merge_sort(nums))
代码运行结果:

分析
- 在归并排序中,两个序列合并的过程中,获得当前最小的元素只需要让两个可能的最小元素进行一次比较,因为利用了“ X < Y , Y < Z X<Y, Y<Z X<Y,Y<Z, 则一定有 X < Z X<Z X<Z”的逻辑。而选择排序和插入排序中,元素间的比较有很多无用功。这便是归并排序省时间的根本原因。
寻找更优化算法的精髓就在于少做无用功。
- 归并排序有一个问题:需要额外的存储空间保留中间结果——在把两个子序列合并为一起时,需要额外 O ( N ) O(N) O(N)大小的存储空间。
在计算机科学中很难有绝对的好,因为衡量好的标准有很多维度。
- 归并排序算法在使用空间的维度上就不算太经济,因此有人试图寻找一种时间复杂度是 O ( N l o g N ) O(NlogN) O(NlogN),同时又不占用额外存储空间的排序算法。
(2)堆排序(Heap Sort)
提出人:加拿大计算机科学家约翰·威廉斯 (于1964年)。
步骤
- 将序列构造成一个大顶堆,序列的最大值为根结点;
- 将根结点与序列的最后一个元素交换;
- 将根结点到序列倒数第二个元素再构造成一个大顶堆。如此往复,最终得到一个递增序列。
代码实现[3]
# python
# 看讲解利用完全二叉树排序很简单,代码就迷糊了
def heap_sort(nums):
n = len(nums)
for i in range(n // 2 - 1, -1, -1):
heapify(nums, n, i)
for i in range(n - 1, 0, -1):
nums[i], nums[0] = nums[0], nums[i]
heapify(nums, i, 0)
return nums
def heapify(nums, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and nums[i] < nums[l]:
largest = l
if r < n and nums[largest] < nums[r]:
largest = r
if largest != i:
nums[i], nums[largest] = nums[largest], nums[i]
heapify(nums, n, largest)
return nums
nums = [12, 9, 3, 6, 7, 14, -6, 13, 24, 7, 6, -9, 5, 0, 5, 6, 14, 16, 12, 18, 18]
print(heap_sort(nums))
代码运行结果:

分析
- 满足前面提到的两个要求:
- O ( N l o g N ) O(NlogN) O(NlogN)的时间复杂度
- 不占用额外的空间(也被称为就地特征 (in place characteristic))
- 不满足稳定性要求(稳定性指两个相同的元素在排序前后相对位置维持原有的次序)。
(3)快速排序(Quick Sort)
提出人:英国计算机科学家托尼·霍尔
步骤
- 从序列中挑选出一个元素,作为“基准”(pivot);
- 重新排序数列,所有比基准值小的元素放在基准值左边,大的放在基准值右边,相等的放在任一边都可;
- 递归的将小于基准值和大于基准值的子序列分别排序。
代码实现[4]
# python
def quick_sort(nums, low, high):
if low < high:
temp = partition(nums, low, high)
quick_sort(nums, low, temp-1)
quick_sort(nums, temp+1, high)
return nums
def partition(nums, low, high):
i = low - 1
pivot = nums[high]
for j in range(low, high):
if nums[j] <= pivot:
i = i + 1
nums[i], nums[j] = nums[j], nums[i]
nums[i+1], nums[high] = nums[high], nums[i+1]
return i + 1
nums = [12, 9, 3, 6, 7, 14, -6, 13, 24, 7, 6, -9, 5, 0, 5, 6, 14, 16, 12, 18, 18]
print(quick_sort(nums, 0, len(nums)-1))
代码运行结果:

分析
- 比归并排序算法和堆排序算法快两三倍
- 只需要 O ( l o g N ) O(logN) O(logN)的额外空间
- 也不满足稳定性要求(稳定性指两个相同的元素在排序前后相对位置维持原有的次序)。
- 虽然平均时间复杂度是 O ( N l o g N ) O(NlogN) O(NlogN),但在极端的情况下时间复杂度是 O ( N 2 ) O(N^2) O(N2)
讨论:三种时间复杂度为 O ( N l o g N ) O(NlogN) O(NlogN)的算法
| 算法 | 平均时间复杂度 | 最坏时间复杂度 | 额外空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 归并排序 | O ( N l o g N ) O(NlogN) O(NlogN) | O ( N l o g N ) O(NlogN) O(NlogN) | O ( N ) O(N) O(N) | ✔ |
| 堆排序 | O ( N l o g N ) O(NlogN) O(NlogN) | O ( N l o g N ) O(NlogN) O(NlogN) | O ( 1 ) O(1) O(1) | ✗ |
| 快速排序 | O ( N l o g N ) O(NlogN) O(NlogN) | O ( N 2 ) O(N^2) O(N2) | O ( l o g N ) O(logN) O(logN) | ✗ |
三种排序算法各有千秋,体现出在计算机科学领域做事的两个原则:
- 尽可能的避免做了大量无用功的方法,如选择排序和插入排序,一旦不小心采用了那样的方法,带来的危害有时是灾难性的
- 接近理论最佳值的算法可能有很多种,除了单纯考量计算时间外,可能还有很多考量的维度,因此有时不存在一种算法就比另一种绝对好的情况,只是在设定的边界条件下,某些算法比其他更合适罢了。
1.4.3 针对特殊情况,我们是否还有更好的答案
归并排序、堆排序和快速排序至今仍在使用,但是它们都不圆满。
科学家们依然在考虑在某个特定的应用中寻找一些更好的排序算法,但一种排序算法可能难以兼顾前面讲到的各个维度的多种需求。所以,现在人们对排序算法的改进大多是结合几种排序算法的思想,形成混合排序算法。
(1)内省排序 (Introspective Sort)
- 快速排序和堆排序结合起来产生的算法
- 是大多数标准函数库 (STL) 中的排序函数使用的算法
(2)蒂姆排序 (Timsort)
- 2002年,由蒂姆·彼得斯发明
- 插入排序节省内存,归并排序节省时间,结合了这两种排序算法的特点产生的
- 最坏时间复杂度控制在 O ( N l o g N ) O(NlogN) O(NlogN)量级,同时还能够保证排序稳定性
- 最初在Python语言中实现,今天依然是Python语言默认的排序算法
- 可以看成是以块为单位的归并排序,而这些块内部的元素是排好序的(从小到大或从大到小排序均可)。
任何一个随机序列内部通常都有很多递增的子序列或者递减的子序列,相邻两个数总是一大一小交替出现的情况并不多。
蒂姆排序就是利用了数据的这个特性来减少排序中的比较和数据移动的。
步骤
- 找出序列中各个递增和递减的子序列。若子序列太短(小于一个预先设定的常数(通常为32或64)),则用简单的插入排序将其整理为有序的子序列。寻找插入位置时使用的是二分查找。然后将这些有序子序列一个一个放入一个临时的存储空间(堆栈)中。
- 按照规则合并这些块。合并的过程是先合并两个最短的。合并的原理与归并排序相同,但是通过批处理的方式进行归并。采用跳跃式预测的方式得到被归并组的边界。
实际应用时蒂姆排序要比归并排序快几倍
蒂姆排序速度和快速排序基本相当
蒂姆排序是一种稳定的排序算法,便于多列列表的排序,今天应用非常广泛
思考题1.4
Q1. 赛跑问题 (GS)
假定有25名短跑选手比赛争夺前三名,赛场上有五条赛道,一次可以有五名选手同时比赛。比赛并不计时,只看相应的名次。假设选手的发挥是稳定的,也就是说如果约翰比张三跑得快,张三比凯利跑得快,约翰一定比凯利跑得快。最少需要几次比赛才能决出前三名?(在第6章给出了这一问题的解答。(难度系数3颗星))[5]
步骤:
- 5个赛道,将25名选手分成5组;
- 对分好的5组选手进行比赛,每组做出排名;# 赛5场
- 每组的第一名再比一次决出整体第1名; # 赛1场
- 将步骤3得出的第4,5名选手及他们在步骤2中所属的组的组员全部删除,再让步骤3的第2名和第3名,以及步骤3的第2名在步骤2中所属的组的对应的第二名,步骤3中第1名在步骤2中所属的组的第二,三名全部拎出来,这5名选手再比一场,即可决出整体的第2,3名。 # 赛1场
答案
所以最少赛7场就能决出前三名。
代码实现:
# python
import numpy as np
def merge_sort(nums): # 归并排序,后面题目代码偷懒会用到,所以这里列出来了
if len(nums) <= 1:
return nums
mid = len(nums) // 2
left = merge_sort(nums[: mid])
right = merge_sort(nums[mid:])
return merge(left, right)
def merge(left, right): # 归并排序的一部分
result = []
i = 0
j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
def run(nums): # 比赛的代码
nums = np.array(nums) # 25名选手
nums = nums.reshape(5, 5) # 分成5组
sorts = []
for i in range(5):
sorts.append(merge_sort(list(nums[i]))) # 5次比赛(每组用归并排序从小到大排好序)
for i in range(5):
for j in range(i + 1, 5):
if sorts[i][0] > sorts[j][0]: # 根据每组的第一名将5组排序,1次比赛,决出第一名
temp = sorts[i]
sorts[i] = sorts[j]
sorts[j] = temp
second_third = [sorts[0][1], sorts[0][2], sorts[1][0], sorts[1][1], sorts[2][0]] # 选出可能是第二名,第三名的选手
second_third = merge_sort(second_third) # 1次比赛, 决出第二名和第三名(根据归并排序从小到大排序)
return sorts[0][0], second_third[0], second_third[1] # 返回前三名
# example
nums = [12, 9, 3, 23, 33, 30, 15, 13, 24, 7, 11, 4, 5, 1, 8, 6, 14, 16, 21, 31, 18, 20, 22, 2, 25]
print(merge_sort(nums)) # 归并排序排出的结果
print(run(nums)) # 7次比赛得出的最终结果(与上面归并排序的前三名相同)
代码运行结果:

Q2 区间排序
如果有 N N N个区间 [ l 1 , r 1 ] , [ l 2 , r 2 ] , … , [ l N , r N ] [l_1, r_1], [l_2, r_2], …, [l_N, r_N] [l1,r1],[l2,r2],…,[lN,rN],只要满足下面的条件我们就说这些区间是有序的:存在 x i ∈ [ l i , r i ] x_i ∈ [l_i, r_i] xi∈[li,ri],满足 x 1 < x 2 < . . . < x N x_1<x_2<...<x_N x1<x2<...<xN。其中 i = 1 , 2 , … , N i = 1,2,…,N i=1,2,…,N。
比如,[1, 4]、[2, 3]和[1.5, 2.5]是有序的,因为我们可以从这三个区间中选择1.1、2.1和2.2三个数。同时[2, 3]、[1, 4]和[1.5, 2.5]也是有序的,因为我们可以选择2.1、2.2和2.4。但是[1, 2]、[2.7, 3.5]和[1.5, 2.5]不是有序的。
对于任意一组区间,如何将它们进行排序?(难度系数3颗星) [6]
分析
-
N
N
N个区间有交集,则
N
N
N个区间无论如何排列都是有序的;
如图3个区间 [ l 1 , r 1 ] , [ l 2 , r 2 ] , [ l 3 , r 3 ] [l_1, r_1], [l_2, r_2], [l_3, r_3] [l1,r1],[l2,r2],[l3,r3]存在交集(灰色的公共区域),则这三个区间无论怎么排序都是有序的。
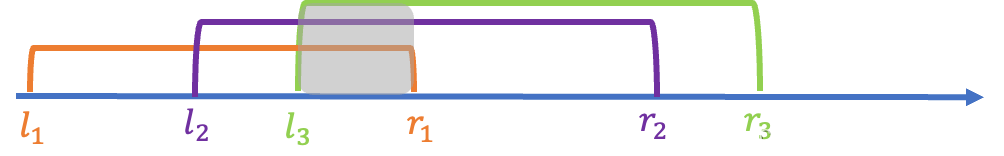
-
N
N
N个区间没有交集,但是存在
K
K
K(
2
<
K
<
N
2<K<N
2<K<N)个区间有交集的情况,则将这
K
K
K个区间的并集与其他没有交集的区间左端点或右端点进行排序,得到的区间顺序即为有序区间;
如图4个区间 [ l 1 , r 1 ] , [ l 2 , r 2 ] , [ l 3 , r 3 ] , [ l 4 , r 4 ] [l_1, r_1], [l_2, r_2], [l_3, r_3], [l_4, r_4] [l1,r1],[l2,r2],[l3,r3],[l4,r4],其中前三个区间存在交集,但是与 [ l 4 , r 4 ] [l_4, r_4] [l4,r4]没有交集,则用 [ l 1 , r 1 ] , [ l 2 , r 2 ] , [ l 3 , r 3 ] [l_1, r_1], [l_2, r_2], [l_3, r_3] [l1,r1],[l2,r2],[l3,r3]的并集 [ l 1 , r 3 ] [l_1, r_3] [l1,r3]与 [ l 4 , r 4 ] [l_4, r_4] [l4,r4]进行端点排序决定 [ l 4 , r 4 ] [l_4, r_4] [l4,r4]的位置是在它们的左侧还是右侧即可,对这三个区间的位置可以随意排放。

-
N
N
N个区间没有交集,但是存在两个区间有交集的情况,则需要这两个区间的并集与其他无交集的区间的左端点或右端点进行排序,得到的区间顺序即为有序区间;
如图4个区间,只有两个区间有交集,则只需要将这两个区间并集与其他区间进行端点比较即可。

-
N
N
N个区间没有交集,但存在区间两两有交集,成“链式”结构,则将这些成链式结构的区间当成无交集区间与其他区间左端点或右端点进行排序即可;
如图5个区间,虽然其中三个两两有交集,但是是链式的,只需要把所有5个区间进行端点排序即可。

代码
综上,发现1~3中存在交集的区间排序与否都是可以的,但是分析4中的区间必须排序,所以如果用暴力解法,只需要将所有区间的左端点或右端点进行排序即可(上面的分析是基于少做无用功的原则,代码我写不出来T.T,真是一顿操作猛如虎,一看战绩0杠5…)代码如下:
# python
def interval_sort(nums):
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i][0] > nums[j][0]: # 这里选择左端点排序
temp = nums[i]
nums[i] = nums[j]
nums[j] = temp
return nums
# example
nums = [[1,2], [1.5, 4], [1, 3], [2, 9], [11, 12]]
print(interval_sort(nums))
代码运行结果:

参考:
[1] 插入排序代码实现:https://www.runoob.com/python3/python-insertion-sort.html
[2] 归并排序代码实现:https://www.jianshu.com/p/3ad5373465fd
[3] 堆排序代码实现:https://zhuanlan.zhihu.com/p/105624690
[4] 快速排序代码实现:https://www.runoob.com/python3/python-quicksort.html
[5] 赛跑问题:https://blog.csdn.net/laozhuxinlu/article/details/51745463
[6] 区间排序:https://blog.csdn.net/sinat_40896008/article/details/126571560

















 4336
4336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









