







强化学习的目标是训练出一个智能体,使其拥有独立自主完成某种任务的能力。
这就要先给问题抽象成模型,使用的模型就是马尔可夫过程。
马尔可夫过程包含状态、动作、转移函数、奖励。
动作的选择是智能体的随机性,进入哪个下一状态是环境的随机性。
为了确定哪些动作是“好的”,可以达到长期收益最大,给每个动作附加一个价值,这个价值就是Q值;也可以给每个状态附加一个价值,这是V值。选择好的动作、进入好的状态,则表示到最终状态能获得的平均奖励会更高。
- V值:未来所获得的奖励总和的平均值,代表了这个状态今后能获得的奖励的期望。随策略变化而变化。
- Q值:在某个状态选取动作,直至最终状态所获得的奖励总和的平均值,受环境的状态转移概率影响,但是环境的状态转移概率是不变的。
蒙特卡洛算法估算V值:
- 从某个状态开始做某一个任务直至任务最终状态;
- 重复1很多次;
- 回溯计算每个状态上的G值;
- 平均每个状态的G值,就得到每个状态的V值。
(G值:某个状态到最终状态的奖励总和,G = 奖励r + 折扣因子gamma*下一状态的G值G’)
更新目标:V= V + alpha * (G - V)(每次向G靠近一点)
动态规划算法是事先知道从某个状态开始所有未来直至最终状态的可能性,然后计算每个状态的Q值和V值,这样消耗太大了且有些情况下很难实现,于是使用了蒙特卡洛算法(MD):从随机某状态走到终点状态很多次,然后通过G值的平均估算每个状态的V值。但是这样的缺陷是每次游戏/任务都要从头到尾结束后,回溯更新,如果环境的状态空间非常大、最终状态很难达到或者说没有最终状态,那么,就出问题了。**时序差分算法(TD-error)**就是用来解决MD的这个不足的。
TD算法:
- 走N步就可以回溯更新V值(不用像MC一样走到最终状态);
- 第N步之前走过就用之前的V值作为状态价值,没有走过则状态价值=0。
- 更新目标:V= V + alpha * (r + gamma * V‘ - V)
TD是估计V值的,如果想估计Q值,则既需要估算Q值又需要估算V值,比较麻烦。
解决办法是:用某一状态下选择某一动作的Q值代替V值,直接将这个Q值带入贝尔曼方程计算。例如:如果是在相同策略下产生动作a’,然后用其Q值代替,这就是SARSA算法的原理(为啥这样做?因为这样做管用,并没有严谨的理论证明);如果是用产生最大Q值的下一步动作a‘,将此Q值带入计算,这就是Q-learning(为啥这样做?因为目标是寻找获得最高奖励的动作,Q值代表的是未来获得奖励的期望,选最大的,可以代替V值)。(另:Q- learning和SARSA都是基于TD(0)的)。
Q-learning算法是训练一个表格出来,表格的横坐标是状态,纵坐标是动作空间,内容是Q值,适用于离散状态和离散动作空间。如果问题是连续状态空间的,则可以考虑DQN算法。
DQN:deep network + Q -learning
Q- learning的原理是输入状态,对状态值进行查表(找S- A的对应关系),找到这个状态下Q值最大的那列对应的动作。
DQN的原理是:如果状态是连续的,表格无法表示,则用一个函数来找状态-动作的对应关系:F(S)=A。
训练网络数据采集太慢:跟网络训练速度相比。所以训练的瓶颈一般在智能体跟环境互动的过程中。这时候,考虑把互动的数据都存起来,等到数据足够多再训练网络,这就叫经验回放。
如果只用一个Q网络同时计算Q值和目标值y,则会导致网络学习效率低且训练不稳定,给目标Q值(y值)设置一个Q- target网络,更新速度比计算Q的网络慢,这就是DoubleDQN网络。
如果把预估的Q值分为两部分:S值和A值。S值代表该状态下的Q值的平均,限制A值的平均数为0,S值与A值的和,就是原来的Q值。网络更新S值的时候,在该状态下的所有Q值都更新一遍(因为更新的S值是该状态下的Q值的平均值),优点就是更少的次数更新更多的值。这就是Dueling DQN的原理。
从动态规划到蒙特卡洛到TD-error,到Q- learning再到DQN,都是以求V值和Q值为目的。但是我们的根本目标是找到一个能获得最多奖励的策略,可以考虑直接找而不是通过Q值V值找,策略梯度算法就是直接找的方法。
DQN:TD+神经网络;策略梯度(PG):MC+神经网络,pi=Magic(state),输出的是一个策略,用G值评价动作的好坏,决定策略中每种动作的概率。PG利用带权重的梯度下降方法更新策略,权重是用MC计算的G值。PG没有memory replay,每次数据都是用完即扔。
PG实际效果不是很稳定,且使用了MC的方式,需要走到最终状态才能更新,且数据只能用来更新一次,效率不高。那么,将MC的方式改成TD的方式,也就是从计算G值变成估算Q值,这就是Actor-Critic方法。AC是TD版本的PG。
Actor- Critic网络:包含两个神经网络,Actor网络,Critic网络,输入的状态都是一样的,但是在Actor中,输入状态,输出动作,在Critic中,输入状态和Actor中输出的动作,计算动作的得分。解决了连续动作空间的问题。
DQN估计的是Q值,而AC中的Critic预估的是V值。因为如果用Q值代替V值,可能会出现某一动作概率持续增高的情况(初始状态每个动作的概率都平均的策略下,用PG的带权重方法更新策略,权重就是Q值,当Q值为正时,若随机选择的动作不是最大的Q值那个,后续策略会更倾向于选择这个动作,然后概率更大,使得其概率持续升高。掉进了正数陷阱。),因为Q值是一个正数,权重为正,则意味着提高对应动作的概率。若有足够的迭代次数,这个问题也能解决,但是往往强化学习没有足够的时间与环境充分互动,运气不好就会出现一个很好的动作没有被采样到。解决方法就是减去一个baseline,使权重有正有负。而baseline,一般选择权重平均值,而权重Q的期望就是V值,所以权重从Q(s,a)变为:Q(s,a)-V(s)。
但是估计Q和V两个比较麻烦,如果只估计V,则Q可以通过换算:Q(s,a)=gammaV(s’)+r 得到。那么 TD-error = gammaV(s’) + r - V(s) —— 这就是Critic网络的损失函数。
同时也是Actor网络更新策略时的权重值。
PPO就是基于AC框架。连续型策略问题,就是将策略分布用函数表示。但是神经网络预测输出的策略是一个固定的shape,不是连续的,解决办法就是,先假定策略分布函数服从一个特殊的分布,这个特殊的分布可以由一两个参数表示,如正态分布,只需要确定均值mu和方差sigma两个参数。让神经网络确定mu和sigma的值,就可以获得整个概率密度函数。然后选择动作时从概率密度函数中抽样出来一个动作即可。在更新动作的概率时,可以是更新mu值,也可以是更新sigma值,也可以两者都更新。
至于AC产生的数据只能用一次的问题,PPO用重要性采样IS技术,让数据可以多次使用。如果想使用策略B产生的数据更新策略P,则只需要将 td-error 乘以一个重要性权重 IW = P(a)/B(a)。在PPO中,可以理解为目标策略出现动作a的概率除以行为策略出现动作a的概率。
这样,就可以将AC的在线策略,变成离线策略。然后使用TD(n),使用N步更新方法。
但是P策略和B策略的差异并不能太大,为了处理这个问题,有两个做法:PPO-KL和PPO-clip。
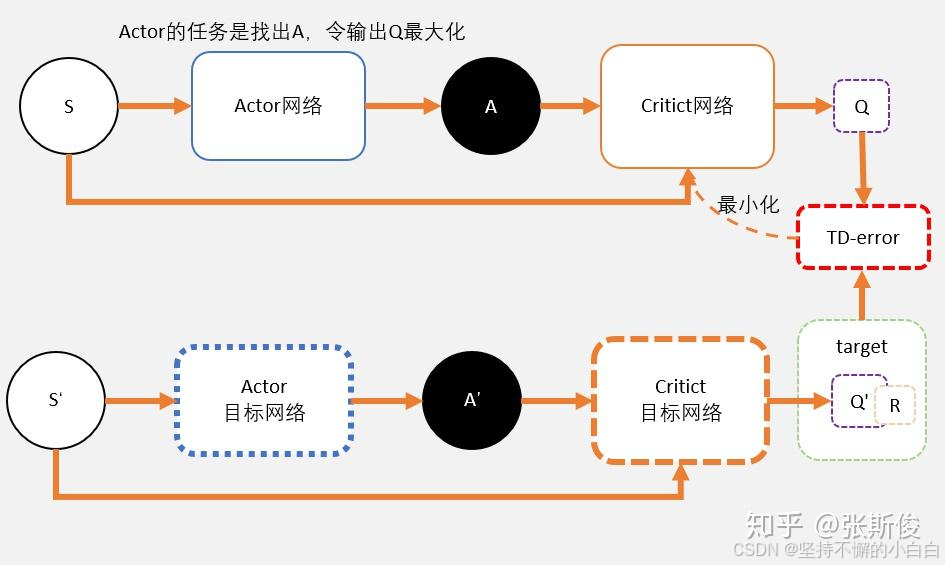
如果让策略函数输出的结果直接是一个动作(而不是像PPO输出一个概率函数),这就是DDPG算法。DDPG是从DQN那里改进过来的,DQN预测的是Q值,且处理连续状态空间,离散动作空间的问题。如果想处理连续动作空间的问题,用一个magic函数代替max Q的功能,这就是DDPG中的Actor网络。Actor网络输出的是一个动作(这个动作输入到Critic中,能获得最大的Q值),与AC中的输出动作概率密度函数不同。且这里Actor的更新方式是梯度上升,而不是带权重的梯度更新。
DDPG使用的是梯度上升,寻找最大Q值的动作,并没有使用PG技术做带权重的梯度更新。所以DDPG是一个离线策略,可以多次更新且不使用IS。DDPG中的Critic网络预估的是Q值,而不是V值,与AC中的预估V值不一样。
所以说DDPG源于DQN而不是AC。但是在DQN中,计算的是Q(s),把该state下的所有动作Q值都输出,选择Q值最大的那个对应的动作。而在DDPG中,会把动作a也作为输入投入到critic网络中,让其评判这个action的值,所以这里是计算Q(s, a)。
为了保证选出来的动作具有随机性,能充分探索环境,DDPG使用的是正态分布抽样(DQN使用的是epsilon-greedy算法),使用输出的动作a作为均值,加上一个VAR,构造成正态分布,然后从这个正态分布中随机抽出一个新的动作代替a。a作为正态分布的均值,有最大的概率可以获得。VAR可以控制探索的程度:VAR越大,正态分布图像越“矮胖”,选择a的概率更小,探索程度更高;VAR越小,正态分布越“高瘦”,选择a的概率越大,开发程度更高。
在DQN算法中,Q值会被高估,这个问题在DDPG中也存在,解决这个问题的思路就是使用target网络。TD3(Twin Delayed Deep Deterministic policy gradient algorithm,双延迟深度确定性策略梯度算法)中用了两套网络估算Q值,估算出来的值相对较小的作为更新目标。需要注意的是,TD3是DDPG的改进,DDPG用了4个网络,TD3用到了6个网络。
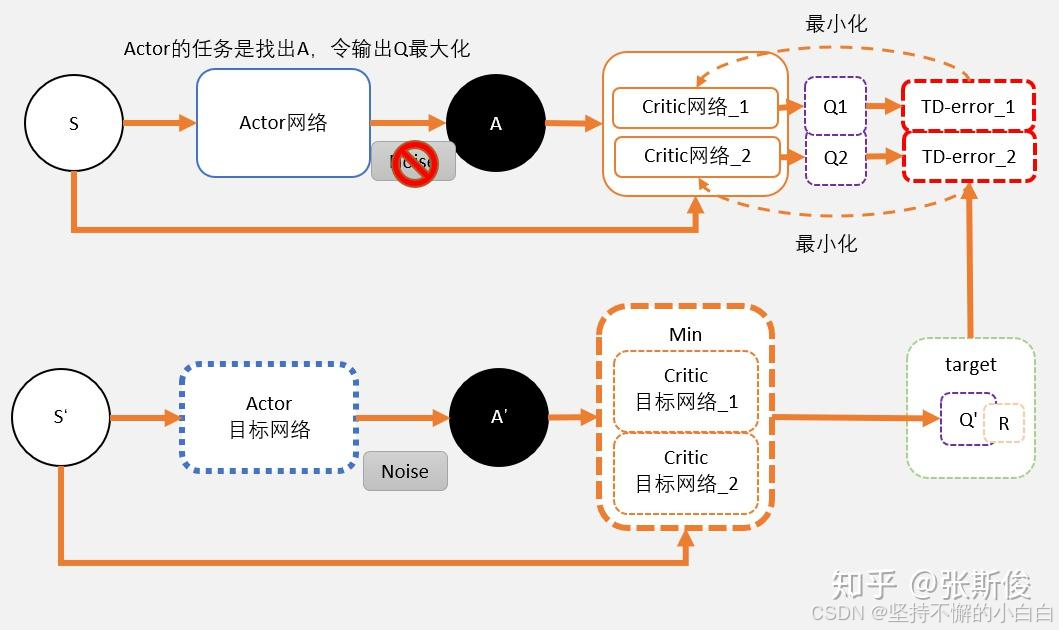
TD3的两个Critic目标网络是独立运行的,生成不同的更新目标值,然后取最小的那个值用来更新两个独立的Critic网络。目标Q值计算方式为:target = min(Q1,Q2) * gamma + r。
虽然Critic网络的更新目标一样,两个Critic网络会越来越趋向于真实的Q值,但是由于网络初始参数值不一样,会导致计算出来的值有所不同,有一定空间选择最小的值,一定程度上避免了Q值被高估。
对于actor网络来说,它的目标是找到某一动作,Q值最大。
delayed:这里指actor更新比critic网络的更新延迟一点,因为如果actor跟critic一起更新,critic还没有稳定的时候,对actor来说目标总是变化,导致actor更新的不稳定。可以让critic先多更新几次,变得更确定了,再去更新actor。
除此之外,在TD3中,价值函数的更新目标每次都在action上加一个小扰动,即 target policy smoothing regularization 技术。能减少策略过度乐观的偏差,提升算法的稳定性,网络的健壮性。实现的时候,可以从标准正态分布中抽取noise,然后根据动作值大小对noise进行缩放。
RL一个难点是智能体用于学习的数据是实时交互来的,数据太少且耗费时间。用多个智能体与环境互动,每个智能体产生的数据都给模型学习(算法使用AC架构),这样数据量就大了,这就是A3C的思想。但是A3C的每个直接与环境互动的worker提交给全局网络的数据是梯度,而不是直接提交互动的数据。
AC是on-policy,产生的数据的策略和更新的策略需要是同一个网络,所以A3C只能worker先计算梯度再将梯度传给全局网络。但是PPO解决了离线更新策略的问题,所以,DPPO的worker只需要收集数据,然后传给全局网络,由全局网络从数据中直接学习即可。需要注意的是DPPO中的数据收集阶段和网络训练阶段不能同时进行,需要两组线程交替运行。
链接: 参考

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









