







1. DBPN
(Deep Back-Projection Networks For Super-Resolution, CVPR2018)
这篇文章提出了一种迭代地计算上采样和下采样投影误差的错误反馈机制,对重建过程进行引导以得到更好的结果。文章提出的上采样和下采样映射单元如下图所示。

以上采样单元为例。先将输入的低分辨率尺寸映射到高分辨率特征图,接着再将这个高分辨率的特征图映射回输入尺寸大小的特征图,计算其与输入特征图的残差,再次将这个残差映射到高分辨率尺寸,与之前的高分辨率特征图相加得到最后的输出。这一具体过程让我想到了cycleGAN的思想,即需要同时考虑正向和反向的映射,对生成的高分辨率图像进行下采样也应能够与输入的低分辨率图像相近。在以上结构中,通过计算与输入数据的残差,实现了错误反馈的机制。下采样单元则是将上采样单元的放大尺寸和缩小尺寸的顺序颠倒一下。

DBPN的网络结构如上所示。通过采用稠密连接的方式,将多个上采样单元和下采样单元堆叠起来,最终通过一个卷积层重建出超分辨率结果。此方法在NTIRE2018比赛中8倍的bicubic上采样任务上拿到了第一名,PIRM2018比赛中也拿到了Region 2的第一名。
github(caffe): https://github.com/alterzero/DBPN-caffe
github(pytorch): https://github.com/alterzero/DBPN-Pytorch
2. IDN
(Fast and Accurate Single Image Super-Resolution via Information Distillation Network, CVPR2018)
这篇文章关注的问题是,大多数方法为了获得更好的结果,都趋向于将网络加深或者扩大,实际的应用性很低。于是文章从特征图的通道维度入手,提出了一种叫做信息蒸馏块的结构。网络结构如下图所示,由特征提取块,堆叠的信息蒸馏块和重建块组成。

每个信息蒸馏块由增强单元和压缩单元组成。增强单元结构如下。

增强单元中,可以将上面的三个卷积层和下面的三个卷积层分别看成一个模块。其中上面的模块输出局部短路径信息,下面的模块输出局部长路径信息。每个模块中,第一个卷积层输出的通道数比第二个卷积层输出的通道数大,第三个卷积层输出的通道数比第一个卷积层输出的通道数大。上面的模块输出的局部短路径信息在通道维度上被划分为两部分,一部分与输入数据串联起来,另外一部分输入下面的模块。最后,将输入的数据,保留的局部短路径信息以及下面的模块输出的局部长路径信息相加,即得到增强单元的输出。
增强单元的输出都会输入到压缩单元中。所谓的压缩单元,就是一个1×1的卷积层,将特征图的通道维度进行压缩,蒸馏掉冗余的信息。
其实这篇文章方法的网络结构与VDSR或是LapSRN的网络结构很相似,都是学习高分辨率图像和低分辨率图像之间的残差,与bicubic上采样后的低分辨率图像相加得到输出。IDN通过压缩网络中特征图通道维度的方式,在减小网络参数,提高速度的情况下,还保证了重建的结果。
github(caffe): https://github.com/Zheng222/IDN-Caffe
3.RDN
(Residual Dense Network for Image Super-Resolution, CVPR2018)
这篇文章的方法从名字上也能看出来吧。用了dense的方法,堆叠多个残差稠密块,提出了一个残差稠密网络,充分利用网络中各个层级的特征。与ICCV2017的SRDenseNet很像,不过SRDenseNet只有dense连接,本章方法多了1×1卷积后在相加的步骤,所以这个方法叫做residual dense。作者为在残差稠密块中的1×1卷积起名叫局部特征融合,残差稠密网络最后的1×1卷积起名叫全局特征融合。残差稠密网络和残差稠密块的结构分别如下所示。


github(torch): https://github.com/yulunzhang/RDN
github(tensorflow): https://github.com/hengchuan/RDN-TensorFlow
4.RCAN
(Image Super-Resolution Using Very Deep Residual Channel Attention Networks, ECCV2018)
这篇文章中提到,越来越深的卷积神经网络是使得超分辨率任务的精度越来越高了,然而之前的网络中的特征包含有多余的低频信息,但是网络对于所有信息是同等对待的,从而限制了网络的表达能力。于是,这篇文章将通道维度的注意力机制引入了超分辨率任务中。网络结构如下。

网络结构由特征提取部分,堆叠的残差组用于提取深层特征,放大尺寸模块和重建部分组成。每个残差组包含多个残差通道注意力块。作者把这种结构起名叫残差中的残差,包含有长跳跃连接和短跳跃连接。作者指出,图像的低频信息可以通过这多个跳跃连接传递到网络深层,从而让网络关注于高频信息。我认为其实这本来就是残差网络的恒等映射的优点,并且可以让网络变得更深的原因吧。残差通道注意力块的结构如下图所示。

残差通道注意力块中用一个全局平均池化操作来获得每个通道的全局空间信息的表达。然后使用sigmoid函数实现门控机制,从而赋予网络通道注意力机制。
文章给出的视觉结果全是图像中高频信息十分丰富的部分,都是很密集的线或者很密集的网格,与其他结果相比确实好很多,说明文章中所说的让网络关注于重建图像的高频信息部分,确实有很好的效果。
github(pytorch): https://github.com/yulunzhang/RCAN
5.MSRN
(Multi-scale Residual Network for Image Super-Resolution, ECCV2018)
这篇文章的出发点也是为了充分利用低分辨率图像的特征,从而提出了一个多尺度残差块的结构。所谓的多尺度残差块,就是将残差块和inception块进行了结合,使用了不同尺寸的卷积核,从而可以在不同的尺寸上获取图像的特征。文章指出这是第一次在残差结构上使用多尺度的模式。在多尺度残差块中,会对提取的局部多尺度特征进行融合。多尺度残差网络则由多个多尺度残差块堆叠而成,在网络的最后部分,将每一个多尺度残差块的输出结合在一起进行全局特征融合,从而重建出超分辨率结果。多尺度残差网络和多尺度残差块的结构示意图分别如下所示。

github(pytorch): https://github.com/MIVRC/MSRN-PyTorch
6.CARN
(Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network, ECCV2018)
这篇文章的出发点也是为了减轻网络的体量,增强实用性。作者采用了一种级联机制来实现目的,提出了级联残差网络。网络结构如下。
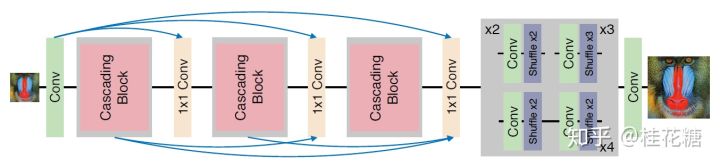
在级联残差网络中,包含多个级联块。级联块内部也包含多个跳跃的连接,这样就使得级联残差网络在局部和全局都可以混合多级的特征。网络使用亚像素卷积层进行尺寸的放大。级联块的结构如下所示。

为了提高网络的效率,作者提出了上图(b)的残差-E块,使用的是与MobileNet类似的方法,不过是使用分组卷积替换深度卷积。上图(c)则是级联块的结构。为了进一步减少参数,可以像递归网络一样,对级联块的参数进行共享,如上图中的(d)。
7.ZSSR
(“Zero-Shot” Super-Resolution using Deep Internal Learning, CVPR2018)
主页:http://www.wisdom.weizmann.ac.il/~vision/zssr/
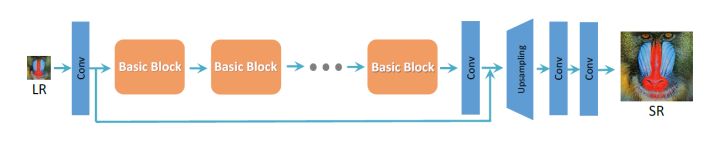
这一篇文章叫做“零样本”超分辨率,我个人觉得也算是一个比较另辟蹊径(新颖)的想法吧。所谓的“零样本”超分辨率,作者采用的做法是利用图像的内部信息,用图像本身来训练网络。由于只有一个实例,因此先对这张图像进行不同倍率的下采样,得到这张图像本身以及多个不同的下采样版本,这些图片就被用来当作训练网络用的标签。再将这些图片进行目标倍率的下采样,即可得到训练的输入数据。对数据集再进行一些旋转、翻转等增强操作,然后用增强后的数据集训练一个相对轻量的卷积神经网络。由于训练数据都是由图像本身得到的,数据分布比较集中,因此网络能够很快得到收敛。再将图像本身输入到网络中,即可完成对原始图像的上采样操作。论文中的过程示意图如下。

作为一个无监督的方法,ZSSR重建的图像的PSNR与一众用大量数据训练的监督方法相比还是会低一些,不过作者指出ZSSR更加适应真实场景中的图像超分辨率,除了对图像进行超分辨率外,还能够解决传感器噪声、图像压缩等问题,这都是只用bicubic下采样生成的数据集训练的方法完成不了的。我认为这篇文章真的是很有意思的一个想法,不过ZSSR应该不太适用于较大倍率的超分辨率任务。
github(tensorflow): https://github.com/assafshocher/ZSSR
8. SFTGAN
(Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform, CVPR2018)
这篇文章的主要目标是在超分辨率结果中恢复出自然真实的纹理。为了实现这一目标,文章将语义分割概率图作为语义类别先验条件,即确定图像中属于天空、水或者草地等的区域,从而有助于生成更加丰富真实的纹理。作者提出了一种空间特征调制层,将语义类别先验结合到网络中。网络结构示意图如下所示。

空间特征调制层的过程是由先验条件中得到仿射变换和平移的参数,再对网络的中间特征进行仿射变换操作。训练网络时使用的感知损失和对抗损失。
github(pytorch/torch): https://github.com/xinntao/SFTGAN
9. SRFeat
(SRFeat: Single Image Super-Resolution with Feature Discrimination, ECCV2018)
这篇文章中说到,虽然已有的基于GAN的超分辨率方法能够被用来生成真实的纹理信息,但是它们都倾向于生成与输入图像无关的不太有意义的高频噪声。于是,作者增加了一个作用于特征域的判别网络,使得生成网络能够生成与图像结构相关的高频特征。生成网络的结构如下。

生成网络中间部分由多个残差块以及远程跳跃连接组成,这样的结构可以更有效地传递远程层之间的信息。之后由亚像素卷积层完成尺寸放大的操作。判别网络结构如下。

训练网络时,作者先用均方误差预训练生成网络,然而,此时得到的结果并不能得到视觉上让人满意的结果。接下来,再用感知损失和两个对抗损失来训练网络。一个对抗损失对应的是图像判别网络,也就是和原有方法一样,对图像的像素值进行评判。另外一个对抗损失则对应的是特征判别网络,是对图像的特征图进行评判,即将感知损失中计算的对象交由判别网路进行判断。通过添加这个特征判别网络,生成网络被训练得能够合成更多有意义的高频细节。作者提到,他们尝试了多种特征判别网络的结构,但是得到的结果都很接近。
从文章给出的视觉结果来看,添加了特征判别网络后,确实能够生成更加真实丰富的细节。
10.ESRGAN
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks, ECCV2018 PIRM Workshop)
这一篇文章为了去除SRGAN的结果中的人工伪影,增强结果的视觉质量,从生成网络,判别网络和感知损失三个方面进行了提升。首先,生辰网络的结构图下。
图中橙色表示的基础块,可以选择残差块(与SRGAN一样),稠密块,或者是本文提出的残差中的残差稠密块。残差中的残差稠密块结构如下。
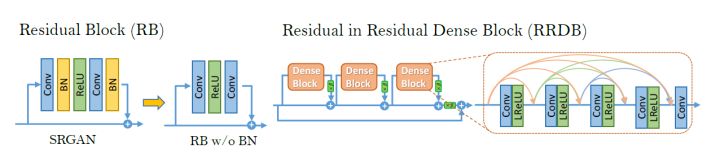
在EDSR中就指出了去掉BN层能够给超分辨率任务的结果带来提升。作者将BN层去掉,同时将原始残差块中的残差映射分支结构改为稠密连接的结构。一个残差中的残差稠密块中包含多个修改后残差块以及一个长跳跃连接的恒等映射,所以叫做残差中的残差。作者指出,由于这个结构使得网络更深并且更复杂,给结果的提升带来了好处。为了训练这么深的网络,同时使结果更好,还使用了残差缩放、更小的初始化等操作。
判别网络的改进是将原先标准的判别网络改为了相对的判别网络,即原先的判别网络是判断输入图像是否是真实的,而现在判别网络是判断输入图像是否比假的图像更加真实,比较的对象是对一个mini-batch中所有假数据取平均值。使用相对的判别网络以后,反向传播给生成网络的梯度能来自生成数据和真实数据,而不像以前只能来自生成数据,因此生成网络能够生成更加锐利的边缘和更加丰富的纹理细节。
对感知损失的改进是使用的是激活函数之前的数据,而不是使用激活函数输出的数据。由于激活函数是稀疏的,因此激活函数带了了非常弱的监督。同时,作者还发现使用激活函数输出的数据,会带来重建图像与GT亮度不一致的问题。在参加PIRM2018比赛中,作者尝试了不同的感知损失,还专门fine-tuned了VGG网络用于材料识别任务,因为这个任务更加注重于纹理而不是物体。
文章中还提到了网络插值的操作。即先用均方误差训练好一个生成网络,再基于GAN训练一个生成网络,将两个训练好的网络中的所有参数赋予权重进行插值,即可得到一个插值的网络。通过调节权重,即可以平衡模型的视觉质量与逼真度。
此方法在PIRM2018比赛中拿到了Region 3的第一名。
github(pytorch): https://github.com/xinntao/ESRGAN















 2257
2257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









