







验证码在爬虫的工作中已经是不可避免的一环,本文将介绍一种传统的验证码识别流程,可以轻松应对一些不是特别复杂的验证码。
一、识别流程
流程:灰度–>二值化–>去干扰线及噪点–>切割成单个字符–>标注–>识别学习并得到模型–>使用模型识别
从某网站获取到的原始验证码:

处理流程总共分为以下几步:
1.读取图片,并根据需要决定是否调整图片尺寸;
2.对图片进行灰度处理;

3.根据自己设置的阈值,对图片进行二值化处理;

4.降噪处理,去除干扰的像素点及像素块;

5.对图片进行切割,获得单个字符,并进行人工标注;


6.使用sklearn的svm分类器进行训练,得到模型;
7.使用训练得到的模型进行验证码识别;
二、部分代码,详细见项目:
2.1、图片处理
img = cv2.imread("image14.png") # 读取图片
im_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图
# 二值化处理
ret, im_inv = cv2.threshold(im_gray, 150, 255, 0)
show_gray_img(im_inv)
img_clear = noise_remove_cv2(im_inv, 1) # 去除噪点
去燥点的原理及代码
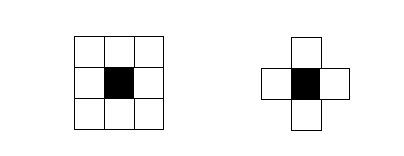
一般常规的判断一个像素是否为噪点的方法有4邻域或8邻域判断法,即通过统计某个像素点周围4个或8个像素点中白色像素的个数来判断该像素点是否为孤立的,上图所示的这种肯定都为孤立像素,应该被去除掉。具体的实现代码如下:
# 去除噪点
def noise_remove_cv2(image, k):
def calculate_noise_count(img_obj, w, h):
"""
计算邻域非白色的个数
"""
count = 0
width, height = img_obj.shape
for _w_ in [w - 1, w, w + 1]:
for _h_ in [h - 1, h, h + 1]:
if _w_ > width - 1:
continue
if _h_ > height - 1:
continue
if _w_ == w and _h_ == h:
continue
if img_obj[_w_, _h_] < 230: # 二值化的图片设置为255
count += 1
return count
w, h = image.shape
for _w in range(w):
for _h in range(h):
if _w == 0 or _h == 0:
image[_w, _h] = 255
continue
# 计算邻域pixel值小于255的个数
pixel = image[_w, _h]
if pixel == 255:
continue
if calculate_noise_count(image, _w, _h) < k:
image[_w, _h] = 255
return image
2.2、图片切割
# 垂直分割投影法分割图片
img_list = cut_vertical(img_clear)
t = 1
for i in img_list:
resize_img = cv2.resize(i, (15, 30)) # 重新定义大小
# 这里可以对切割到的图片进行操作,显示出来或者保存下来
cv2.imwrite(os.path.join(new_image_path, file + "_" + str(t) + '.jpg'), resize_img)
t += 1
def cut_vertical(img_list, cvalue=255):
"""
投影法竖直切割图片的数组
:param img_list: 传入的数据为一个由(二维)图片构成的数组,不是单纯的图片
:param cvalue: 切割的值 同cut_level中的cvalue
:return: 切割之后的图片的数组
"""
# 如果传入的是一个普通的二值化的图片,则需要首先将这个二值化的图片升维为图片的数组
if len(np.array(img_list).shape) == 2:
img_list = img_list[None]
r_list = []
for img_i in img_list:
end = 0
for i in range(len(img_i.T)):
if count_number(img_i.T[i], cvalue) >= img_i.shape[0]:
star = end
end = i
if end - star > 1:
r_list.append(img_i[:, star:end])
return r_list

三、训练及识别
3.1、模型训练
因为标注数据里将标注数据作为了文件夹的名称,所以文件夹内的文件作为训练数据,文件夹名作为标签,这里使用sklearn.svm 支持向量机的算法,来对数据进行训练。(关于svm的讲解,可以看看知乎大神的理解https://www.zhihu.com/question/21094489 ),通过fit进行训练后,将训练的结果保存到pkl文件里,其实里面都是0和1的特征值。
import os
import cv2
import joblib
from sklearn.svm import SVC
train_set_x = []
train_set_y = []
path = "./train_img"
# 遍历文件夹 获取下面的目录
for category in os.listdir(path): # listdir的参数是文件夹的路径
for dir_name in os.listdir(os.path.join(path, category)):
for file_name in os.listdir(os.path.join(path, category, dir_name)):
img1 = cv2.imread(os.path.join(path, category, dir_name, file_name), cv2.IMREAD_GRAYSCALE)
res1 = cv2.resize(img1, (28, 28))
res1_1 = res1.reshape(784) # 将表示图片的二维矩阵转换成一维
res1_1_1 = res1_1.tolist() # 将numpy.narray类型的矩阵转换成list
train_set_x.append(res1_1_1) # 将list添加到已有的list中
train_set_y.append(dir_name)
letterSVM = SVC(kernel="linear", C=1).fit(train_set_x, train_set_y)
# 生成训练结果
joblib.dump(letterSVM, './model_data/letter.pkl')
3.2、使用训练好的模型进行识别
识别流程要与我们训练时步骤一样,先灰度,再二值化,然后降噪,切割,使用模型分类,识别结果就出来了。
import cv2
import joblib
from matplotlib import pyplot as plt, cm
from split_image import noise_remove_cv2, cut_vertical
def ocr_img(file_name):
captcha = []
clf = joblib.load('model_data/letter.pkl')
img = cv2.imread(file_name)
# 转换为灰度图
im_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化处理
ret, im_inv = cv2.threshold(im_gray, 140, 255, 0)
# 去除孤立点,噪点
img_clear = noise_remove_cv2(im_inv, 1)
# 垂直分割投影法分割图片
img_list = cut_vertical(img_clear)
for i in img_list:
res1 = cv2.resize(i, (28, 28))
data = res1.reshape(784)
data = data.reshape(1, -1)
one_letter = clf.predict(data)[0]
captcha.append(one_letter)
captcha = [str(i) for i in captcha]
print("the captcha is :{}".format("".join(captcha)))
plt.imshow(img, cmap=cm.gray)
plt.show()
if __name__ == '__main__':
ocr_img("./test_img/test_img_1.png")
识别效果如下图:

源码及训练的图片等已上传github(https://github.com/deepcoldwing/verification_code)
本文中的方法,更多的目的是介绍一种通用的识别原理。后续还将继续将自己知道的一些方法分享给大家,包括像点选验证码,滑动验证码,不定长验证码等等。















 2944
2944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









