







目录
1. 自然语言处理技术的发展
语言,作为一种复杂的符号系统,其数学本质可被精炼地理解为一种高度精细的编码机制。在这套体系中,语法相当于是语言编解码过程中的一套算法。当我们企图将内心的思想与情感转化为可交流的信息时,我们依赖这些算法——无论是下意识地还是有意识地——来构造合乎规则的语句。说话者通过这种算法将意图编织成语言的丝线,而听话者则借助相同的语法线索,将这些缠绕的丝线重新解译为可理解的思想。
然而,如何让计算机掌握并处理我们的自然语言,这一直是人工智能领域研究者所追求的圣杯。这不仅仅是一个技术挑战,更是一个多学科交叉的科学探索,涉及到语言学、心理学、数学和计算机科学等多个领域。机器学习和数据科学的专家致力于开发和改进算法,以便能够捕捉到自然语言中那些微妙且复杂的规律性,从而赋予计算机理解和生成自然语言的能力。
1.1 基于规则的方法(上世纪70年代以前)
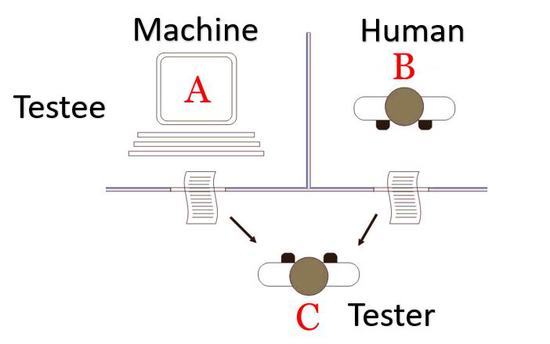
自然语言处理(NLP)的现代历史通常被追溯到1950年,当时计算机科学的先驱艾伦·图灵提出了一项具有里程碑意义的测试——图灵测试。图灵测试的核心理念在于评估机器是否能展现出与人类不可区分的语言理解与应答能力。具体而言,该测试涉及让人类评判者通过文本交流来辨识其对话对象是人还是机器。如果评判者无法一致区分出其对话伙伴的身份,那么可以宣称机器具备了通过图灵测试的能力,从而展示出与人类相似的语言处理智能。
然而,尽管图灵为人工智能和自然语言处理领域勾勒出了这一令人向往的远景,他并没有提供一套明确的技术路线图来实现机器智能。实际上,图灵测试更像是一个哲学上的思想实验,它揭示了人工智能的终极目标,而非具体的科学实现方案。
于是在1958年,10位IT领域的科学家(包括大家熟知的香农、麦卡锡、明斯基等)组织了一场名为“达特茅斯夏季人工智能研究会议”,在会议上他们头脑风暴、集思广益,提出了许多前沿的理论和想法,比如“人工智能”的提法就出自这个会议。但遗憾的是,当时这些科学家对于如何让机器理解自然语言的问题上,思路比较惯性,总是认为机器必须学习人类理解语言的方式进行学习。这在一定程度上限制了自然语言技术的发展。为啥呢?这就得讲到人类是怎么学习语言的了。
于是在1958年,一群科技界的先驱人物,包括克劳德·香农、约翰·麦卡锡和马文·明斯基等杰出科学家,汇集于达特茅斯学院,共同参与了一场具有开创性意义的科学研讨会——达特茅斯夏季人工智能研究会议。在这次历史性的会议上,参与者们通过自由的头脑风暴和深入的交流,催生了一系列革命性的人工智能理论与概念,正是在这次会议上,"人工智能"这一术语首次被正式提出并定义。
尽管此次会议点燃了人工智能领域的火花,但在自然语言理解的探索上,这些顶尖科学家们的思路却受到了当时流行观点的限制。他们普遍认为,要使计算机能够理解并处理自然语言,就必须让其模仿人类学习语言的方式。这种以人类为中心的思路,虽然在当时看来是合理的假设,但后来证明在某种程度上制约了自然语言处理技术的发展。为何如此呢?这涉及到对人类语言习得过程的理解。
通常,当我们开始掌握一门语言时,首先接触并学习的是语法结构——在计算机科学中,这一过程被称作句法分析。为了阐释这一概念,作者举出了一个文学史上著名的例子:“徐志摩喜欢林徽因。”这句简单的表述,在我们大脑中迅速触发了一系列复杂且精细的语言处理机制。
在人的心智中,我们会不自觉地解构这个句子,分析其各个成分,并理解它们之间的语法关系。如果将这一内在的思考过程外化,它可以被描述为一张句法分析树(Parse Tree)。这棵树以一种图形式展现了句子的结构,其中每个节点代表了句子中的一个词或短语,而节点之间的连接则代表了它们之间的语法依存关系。例如,在这个句子中,“喜欢”是核心动词,它连接着两个名词“徐志摩”和“林徽因”,显示出动作发出者和接受者的关系。
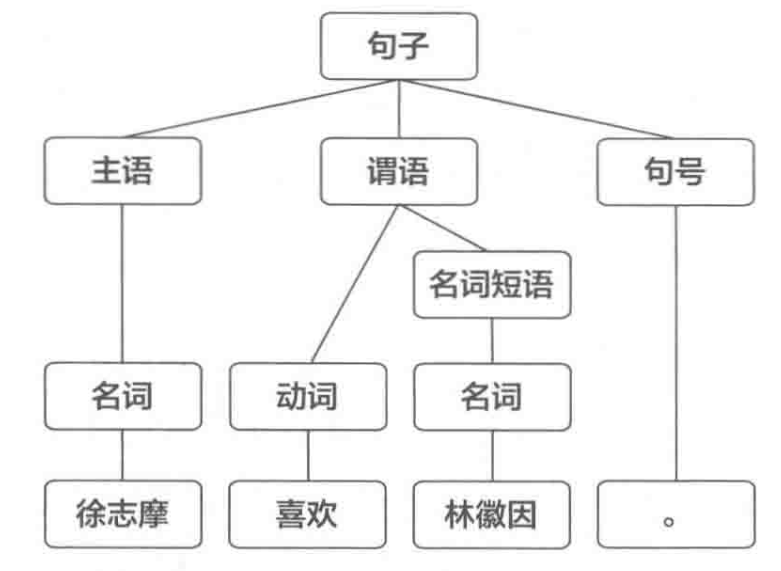
同时也会形成对应的文法规则:

为了实现计算机对句子语法结构的自动识别,早期的自然语言处理研究者们投入了大量精力去编码和输入繁复的语法规则。他们的目标是教导机器区分名词、动词、主语、谓语等基本的语言构成要素。当时的科学界存有一种“天真”的信念:只要足够精细且全面地总结出语法规则,机器便能够像人类一样理解和处理自然语言。然而,这一理想主义的途径很快遭遇了严峻的挑战,面临着两个主要的难题:
难题一:语言的语法体系之繁杂几乎难以尽数,并且无法涵盖所有可能的语言使用场景。每种语言都拥有其独特的语法结构,这些结构不仅内容复杂,而且梳理起来极为费力。更为棘手的是,语言本身是动态发展的——随着社会变迁和文化演进,新的表达方式不断涌现,而现有的语法规则往往跟不上这种发展速度,因此无法覆盖所有的实际语言使用情境。
难题二:基于规则的语法分析方法计算量巨大,效率低下。即便是对于简单的例句“徐志摩喜欢林徽因”,最终生成的二维句法分析树也相当复杂。作者以一个实际的例子来说——“美联储主席本·伯南克昨天告诉媒体7000亿美元的救助资金将借给上百家银行、保险公司和汽车公司。”这样一句并不甚长的话语,如果进行详尽的句法分析,其结果之庞大甚至无法在一张纸上完整呈现。句法分析的复杂性不仅限于此,它进一步影响到后续的语义分析阶段。由于语言在其演化过程中形成了与上下文紧密相关的词义特征,这增加了语义分析的难度,导致计算量剧增。据理论分析,对于考虑上下文相关性的文法,其解析复杂度通常达到句子长度的六次方,这样的计算负担实在是令人望而却步。
1.2 基于统计的方法(上世纪70年代以后)
在20世纪70年代之前,自然语言处理领域的研究几乎完全依赖于基于语法规则的解析方法。然而,这一传统途径因进展缓慢而令学术界、政府以及自然科学基金会深感失望,导致该领域的研究资金日益减少。直至“天降猛男”弗里德里克·贾里尼克(Frederick Jelinek)及其领导的IBM华生实验室(T.J. Watson)的出现,局面才发生了革命性的变化。他们采用了基于统计的方法进行研究,大幅提高了语音识别的准确率,将识别率从70%提升至90%,同时将识别词汇量的规模从几百个单词跃升至数万个单词。
然而,在基于统计的新方法提出之初,科学界对于是否应该放弃基于规则的传统方法,全面转向新方法,曾犹豫了长达15年。在此期间,相关的学术会议常常见证两派的分歧:一派坚守旧制,另一派则拥抱创新。两种方法之间的对峙持续了许久,原因有二:
1)新方法在初期总是不尽完善。早期的统计模型,如基于通信系统和隐马尔可夫模型(Hidden Markov Models),在处理一维符号序列时表现尚可,但在句法分析和机器翻译等领域遇到了障碍。这是因为句法分析要求输出二维结构(例如,二维的分析树),而机器翻译则需要重新排列词序(两种语言对同一事物的描述可能截然不同)。因此,坚持传统方法的保守派批评新方法只能解决NLP的表层问题,而无法深入理解语言结构。面对这些挑战和质疑,支持新方法的科学家们不得不投入大量时间进行理论完善和实践创新。最终,随着谷歌基于统计方法的翻译系统彻底击败基于规则方法的SysTran翻译系统,保守派的最后防线被突破,基于统计的自然语言处理方法成为行业标准。
2)在新旧观念对立的历史时刻,保守派往往坚守自己的既得利益,直到他们退休或退出领域,为新生代腾出空间,创新派才得以引领潮流。这似乎印证了一句讽刺性的调侃:所谓的“老科学家”既可以解读为“老的科学家”,也可以理解为“老科学的家”。从现代的视角来看,采用基于统计的方法无疑是正确的选择。作者感慨,在这15年的过渡期间,那些坚持基于规则方法的博士和科学家们,在科学界的竞争力上已大为减弱。
如今,自然语言处理技术已经取得了长足的进步,基于统计和机器学习的方法——包括深度学习——已成为该领域的主流。这些方法不仅在语音识别、语义理解和机器翻译等方面取得了显著成果,还在不断推动着人机交互、信息获取和知识发现等领域的边界。尽管挑战依旧存在,但NLP的研究和应用前景从未像现在这样光明。后续的读书笔记将讲到相关的内容,敬请期待!!
2. 引用



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









