









 本文介绍了一个基于深度学习的人脸微笑表情生成项目。项目使用CelebA数据集训练,并详细记录了从代码准备到训练及推理的过程。尽管训练效果仍有提升空间,但展示了深度学习在人脸特效方面的应用潜力。
本文介绍了一个基于深度学习的人脸微笑表情生成项目。项目使用CelebA数据集训练,并详细记录了从代码准备到训练及推理的过程。尽管训练效果仍有提升空间,但展示了深度学习在人脸特效方面的应用潜力。
参考代码来源于:https://github.com/tgeorgy/mgan
人脸生成笑脸表情
1、有趣的项目
之前没事会经出翻github看项目,也会发现很多有趣的项目。迫于没什么时间,就过一眼就关了。
所以就特地开了这个发现有趣项目的板块,想有时间的时候就把这些有趣的项目记录下来。但刚开始写之后,翻github就想找有趣的项目,却怎么也找不到。(amazing!😂)
所以我就换了个思路。平时没事我也会经出刷抖音,过一段时间就会有新出的特效什么的,其实就很有意思。而这些实际上都是用深度学习实现的。比如说,这次要写的笑脸生成,之前很火的人物与海报融合,换脸技术,蚂蚁鸭霍这些。而看到这些视频,我也会有兴趣去想它是根据什么实现的,需要怎么做,我也可以自己做到吗?
所以趁着有时间,就找了个最简单的笑脸表情生成来试试看。
项目一开始是通过知乎找到的,然后就直接去github上面看。但是网络没有提供预训练模型,也没有提供任何训练的权重包。就只有作者告诉我们用的什么训练集,怎么样去训练的代码。代码量相对也很少,所以跑通起来非常简单。
2、准备代码和数据集
代码直接从github上面clone下来或者download下来就行了。
然后数据集,再官方readme上也有写,需要在http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html 这个地址上下载,img_align_celeba.zip and list_attr_celeba.txt这两个文件。(需要科学一下)
然后如下图准备好,蓝框的要自己新建一下空文件夹。
红框的就是你准备的数据集,.zip要解压一下。
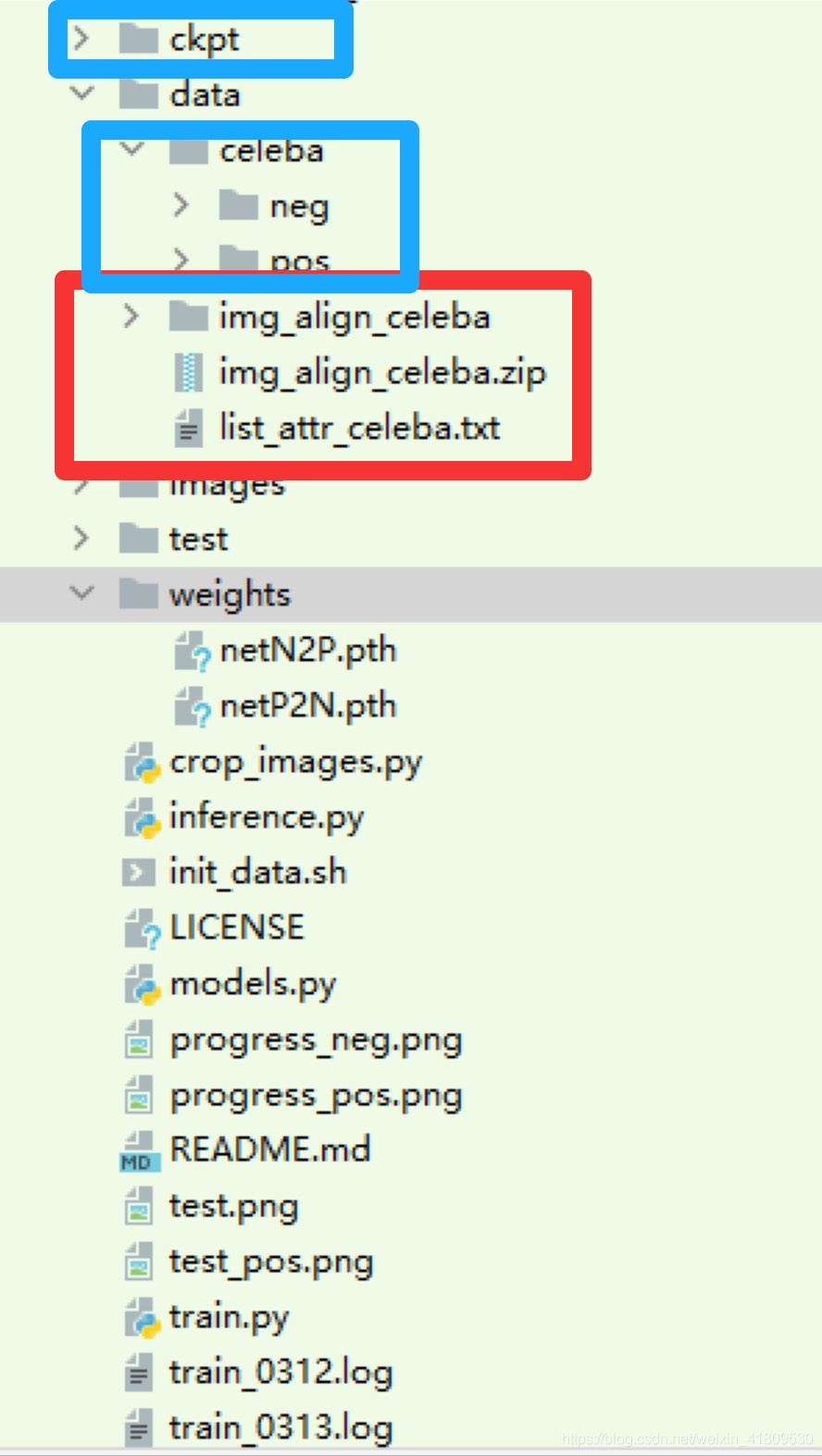
准备完毕后,先运行crop_images.py这个文件。他会自动把数据集种的正样本/负样本(笑脸/不笑的)挑出来。接着就可以训练了。
3、 训练
训练环境作者没有写,但是我随便用了之前配置好的环境可以直接运行。
我的torch版本是1.6.0,所以你也可以参照着来配置。出现缺什么库就再pip一下就好了。
然后跑通train.py开始训练,如下。
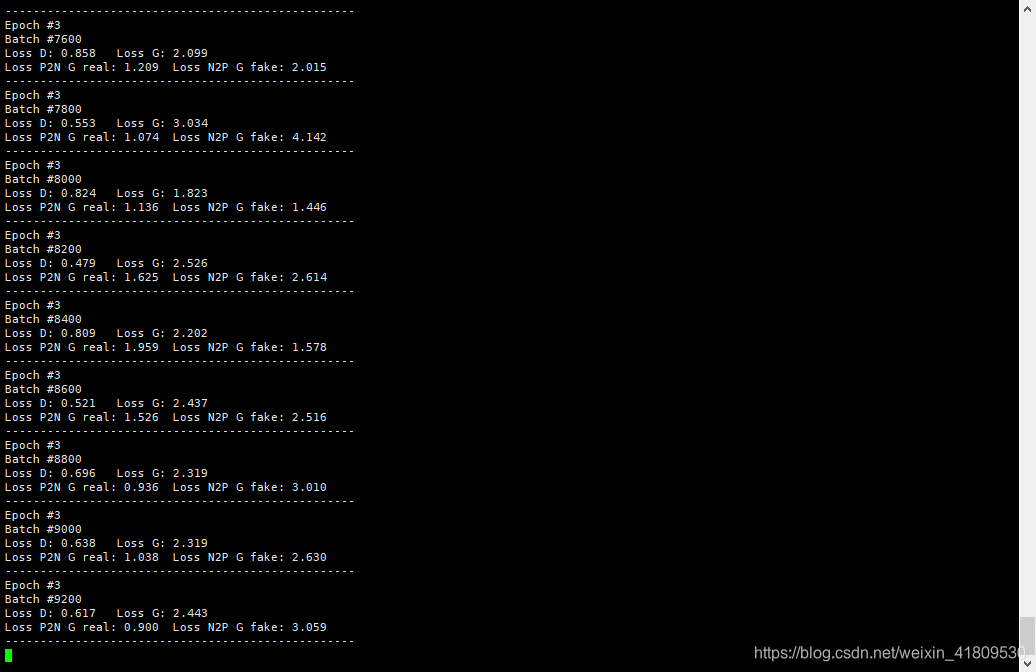
训练会生成两个模型,一个是P2N也就是笑脸变不笑,N2P不笑变笑脸。然后训练途中会根据设置的batch数生成可视化效果图。
我这里生成的效果图如下:(训练了4个小时左右吧,上午开始跑的,还在跑)
看起来再训练集上的效果还不错,就是除了嘴以外,其他部分,眼睛脸部鼻子头发背景也会跟着改变,所以我在想是不是训练的时候可以控制数据集只训练小区域位置会不会比较好。(当然没有相应的数据集也无法实现)
P2N:

N2P:

4、推理/生成人脸
因为作者只提供了训练代码,所以我这里学着他的训练代码,尝试自己输入图片进行推理。
推理的话我们只需要生成网络,不需要判别网络。(这里可以去了解一下生成式网络的结构,如下pix2pix的讲解https://www.jianshu.com/p/8c7a7cb7198c)
所以代码中,我就把标签、判别那些部分全部删去了。
代码如下,我只生成了笑脸,也就是只跑了N2P部分,效果的话,我拿了自己的证件照照片做例子,为科学献身。。。。成效的话,看最后吧。。忍住不笑哈哈哈哈哈。
import itertools
import sys
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '3'
import torch
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
from torchvision.utils import save_image
import torchvision
import cv2
from models import Generator, Discriminator
input_shape = (216, 176)
cudnn.benchmark = True
# Init dataset
transformer = torchvision.transforms.Compose([
# torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# torchvision.transforms.Lambda(
# lambda img: img[:, 1:-1, 1:-1]),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# Init models
# netP2N = Generator().cuda()
# netN2P = Generator().cuda()
netP2N = torch.load('ckpt/netP2N.pth').cuda()
netN2P = torch.load('ckpt/netN2P.pth').cuda()
test = cv2.imread('test/cpy.jpg')
test = cv2.cvtColor(test, cv2.COLOR_BGR2RGB)
test = cv2.resize(test,(input_shape[1],input_shape[0]))
test = transformer(test).cuda()
# Init tensors
test_pos = torch.zeros(1, 3,
input_shape[0], input_shape[1]
).cuda()
test_neg = torch.zeros(1, 3,
input_shape[0], input_shape[1]
).cuda()
print('Inference...')
# real_pos.copy_(pos)
test_neg.copy_(test)
#
# # Train P2N Generator
# real_pos_v = Variable(real_pos)
# fake_neg, mask_neg = netP2N(real_pos_v)
# rec_pos, _ = netN2P(fake_neg)
#
# # Train N2P Generator
real_neg_v = Variable(test_neg)
fake_pos, mask_pos = netN2P(real_neg_v)
# rec_neg, _ = netP2N(fake_pos)
# save_image(fake_pos.cpu()[0]*0.5+0.5,'test.png')
save_image(torch.cat([
test_neg.cpu()[0]*0.5+0.5,
mask_pos.data.cpu()[0],
fake_pos.data.cpu()[0]*0.5+0.5], 2),
'test_pos.png')
训练一两个小时的结果:

训练四五个小时的结果:

哈哈哈哈太难了我。可以看到效果还不是很好,后面那张虽然图片扭曲比第一张小了,但也没露出牙齿。毕竟不是训练集的效果,也可能才训练一上午的效果并不是很好,等我训练一个周末再看看结果吧哈哈哈。。(源码作者也是说可能正常找到一个正确的随机种子,效果就好了。所以深度学习也是一门玄学,但是研究和发展还是有必要一直持续下去的,我对未来科技有信心hhh,respect!)
如果训练效果还不错的话,我就集成一下人脸检测网络,做一下,检测人脸,替换笑脸这些功能。(但我觉得我会很懒不想做。。哈哈哈)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









