







源码路径:https://github.com/ultralytics/yolov5
yoloV5 官方项目爬坑
最近整理了下我之前github上传的一个人脸识别项目,然后把一些组件稍微整理了一下。
还有就是最近在玩一个手势检测的项目,也用到了yoloV5的源码。但在加载模型torch.load()的时候就出现了ModuleNotFoundError: No module named 'models'这个问题。
也有粉丝跟我反馈说出现了这个问题。如下图。(因为之前上传的时候,我是在pycharm设置了yoloV5文件夹为根目录的操作,才不会报错。)

另一个问题就是出现了 'XX' object has no attribute 'inplace',的问题;如下:torch.nn.modules.module.ModuleAttributeError: 'Hardswish' object has no attribute 'inplace'(这两个基本是同一问题)
问题一:ModuleNotFoundError: No module named 'models'
这个问题我也通过百度&谷歌找了文章,都没有很好的解释。在yoloV5官方github下的issue里面有一个解释最清晰的是:https://github.com/ultralytics/yolov5/issues/353
原因大概就是,yoloV5我们在训练train.py完后是这样保存权重的。torch.save(model, PATH)

这样的方式保存的权重包,会将你模型的源代码的相对位置也默认保存(这里指yolov5里面的models文件夹和utils文件夹)。如下这个默认路径,所以使用torch.load() 的时候也要保持这个路径。例如你运行detect.py 也是符合这个路径的。
- yolov5-master
- models
- utils
- train.py
- detect.py
而在我那个人脸识别源码里面,我把路径改变成了如下。
- yoloV5-arcface_forlearn
- yoloV5_face
- models
- utils
- main.py
- yoloV5_face
因此我在main.py里面加载模型的时候就会出错。
解决方案:
这里我使用的解决方案是,将我上面这个路径下的,yoloV5_face也设置为根目录。
import sys
sys.path.append("./yoloV5_face")
这里还有其他几种方案,不过我没去尝试。一种是说直接保存模型权重的参数值,然后再加载模型,加载权重包。一种是说保存为jit / onnx格式。这两种应该是相同的方法。
还有一种如下加载。
model = torch.hub.load('ultralytics/yolov5', 'custom', path_or_model='yolov5s_voc_best.pt')
问题二: 'XX' object has no attribute 'inplace'
我出现这个问题的主要原因是因为,我把文件夹路径修改后,把各个模块代码引用import也改了。
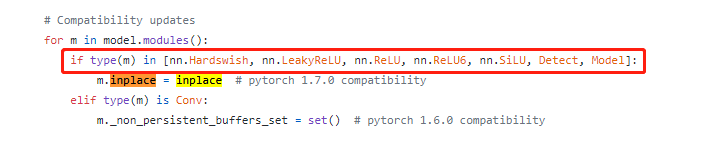
如果出现问题的话,可以检查一下models/experimental.py里面这一段代码,里面的type(m)和对应的模块例如:nn.Hardswish和Detect是否相同。(这里是和import路径对应的,如果更改的路径,相应的值也会更改,导致模块no attribute 'inplace')
解决方案的话跟上面一样,把这个文件夹当成根目录,里面的import也不需要更改就可以直接用。
import sys
sys.path.append("./yoloV5_face")
而类似于网上有说这个问题,都是直接降版本到torch1.6,说是不支持torch1.7的。其实最好就是如果你用1.7训练的,后面不管是模型转换或者推理都用1.7以上的版本,如果你训练时候是1.6的版本,这样就没问题了。
解决方案:转成ONNX再进行模型推理
通过运行yolov5官方提供的源码,就可以将训练好的模型转换成ONNX格式。
python export.py --weights yolov5s.pt --img 608 --batch 1
这里我用python对onnx进行推理。因为我本地的yolov5版本好像比较老,可能有些地方不太一样,具体如果有错误的话,欢迎大家指出。(onnx是可以在不同语言上加载,进行模型推理的。详细可以根据你使用的语言查看相应的官方文档)
class Predict:
def __init__(self, onnx_model_path):
self.imgsz = 608
self.device = 'cuda:0'
self.session = InferenceSession(onnx_model_path)
self.session.set_providers(['CUDAExecutionProvider'])
def scale_coords(self, img1_shape, coords, img0_shape, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding
coords[:, [1, 3]] -= pad[1] # y padding
coords[:, :4] /= gain
clip_coords(coords, img0_shape)
return coords
def non_max_suppression(self, prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False,
multi_label=False,
labels=()):
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
def to_numpy(self, tensor):
# return tensor.detach().cuda().numpy() if tensor.requires_grad else tensor.cuda().numpy()
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def letterbox(self, img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True,
stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
def to_numpy(self, tensor):
# return tensor.detach().cuda().numpy() if tensor.requires_grad else tensor.cuda().numpy()
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def load_image(self, img_raw_data):
img = cv2.imdecode(np.asarray(bytearray(img_raw_data), dtype=np.uint8),
cv2.IMREAD_COLOR)
return img
def run(self, bgr_img):
img0 = bgr_img.copy()
# Padded resize
img = self.letterbox(img0, self.imgsz, stride=32, auto=False, scaleFill=False, scaleup=True)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
inputs = {'images':self.to_numpy(img)}
# input_names = ['images']
outputs = self.session.run(None, inputs)
print(outputs)
filterd_predictions = non_max_suppression(torch.tensor(outputs[0]), conf_thres = 0.25, iou_thres = 0.45)
print(filterd_predictions)
filterd_predictions[0][:, :4] = scale_coords(img.shape[2:], filterd_predictions[0][:, :4], img0.shape).round()
for pred in filterd_predictions[0]:
print(pred)
rect = pred[:4]
cv2.rectangle(img0,(int(rect[0]),int(rect[1])),(int(rect[2]),int(rect[3])),(255,0,0),3)
cv2.imwrite('output.jpg',img0)
if __name__ == '__main__':
img_data = cv2.imread('test/100_0.jpg')
onnx_path = 'weights/best.onnx'
p = Predict(onnx_path)
p.run(img_data)















 3865
3865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









