









我公司的科室开始在公众号上规划一些对外的技术文章了,包括实战项目、模型优化、端侧部署和一些深度学习任务基础知识,而我负责人体图象相关技术这一系列文章。
文章在同步发布至公众号和博客,顺带做一波宣传。有兴趣的还可以扫码加入我们的群。
(文章有写的不好的地方请见谅,另外有啥错误的地方也请大家帮忙指出。)微信公众号:AI炼丹术
人体图像相关技术 - 概述

(图源:https://github.com/xuebinqin/U-2-Net)
一、相关技术背景和意义
我们人是一类感官动物,我们的眼睛每天接收着来自这个世界的无数视觉信息,我们的大脑通过对这些视觉信息(图像)进行处理,让我们对接受到的信息进行分类、目标定位、跟踪等。而计算机发明出来,世界的研究人员都希望计算机能代替我们去处理这些视觉信息,去实现分类、目标定位、跟踪……
而在我们处理这些视觉信息之中,人这一主体本身就是我们重点关注的对象。因此在对图像视觉领域上,对人体/人像方面吸引了众多研究学者的关注和研究。
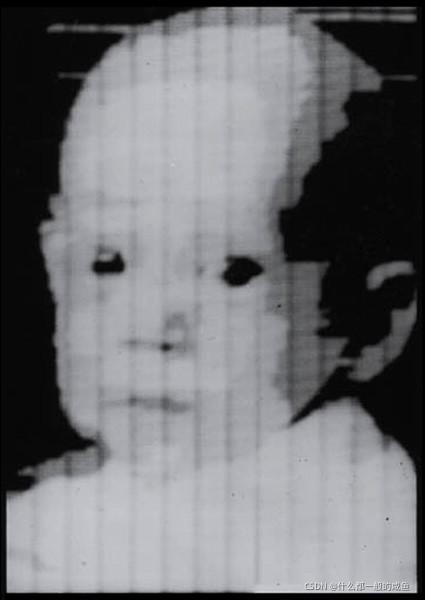
1959年,Russell和他的同学研制了一台可以把图片转化为被二进制机器所理解的灰度值的仪器。这开启了计算机视觉研究的历史,使得我们现在能够用不同的方法处理数字图像。
下图就是第一张被数字扫描的图片(Russell的婴儿照),由此可见,人们对视觉图像的处理的第一关注对象是我们人本身。(图源:https://www.engadget.com/2010-06-30-russell-kirsch-helped-create-them-now-he-wants-to-kill-square-p.html)
要研究图像中的人物,首先我们要确认图像中是不是有人,这就是一个图像分类任务;其次要知道这个人在图像上的位置,定位加分类得到人物的图像信息,这就是一个完整的目标检测任务。也是人体相关技术领域内的一项热点研究——行人检测技术。
完成行人检测技术,我们就使得计算机拥有了最简单的识别能力——找到人。但这是不够的,在我们的人的视觉里图像是一帧一帧的出现,我们处理信息也是在连续的画面中进行的。可能我们需要判断这个人正在做什么、将要做什么?这个时候一张图像提供的信息不足以给我们或计算机进行分析判断。因此,我们希望计算机可以处理视频内容。当我们要对同一个人在视频上的信息进行分析研究,就避免不了我们要对这个人进行持续性的定位。这也就是目标检测的进阶技术——行人目标跟踪。
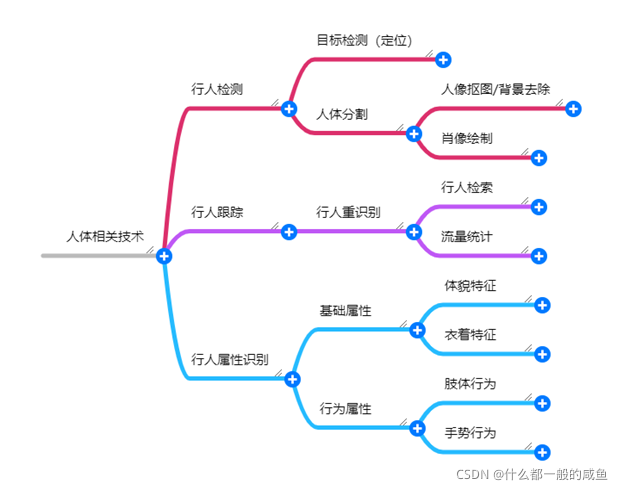
当我们实现了行人目标检测和目标跟踪之后,我们就可以完整的得到一个人在视频/图像上的数据,进而可以对数据进行分析提取我们想要的信息。所以这里就把人体的技术划分出了很多新的分支,想知道这个人的细节信息或轮廓信息:人体分割技术、想知道这个人的行为/动作:**人体行为识别、**想知道这个人的外貌特征/穿着打扮等等:**人体属性识别、**想不同视频画面中区分出每一个人:行人检索……
二、相关技术和应用简要介绍
这里主要关于人体相关技术点,进行简要概括,包括相关技术点使用的方法、以及相关应用。
1. 行人检测(Pedestrian Detection)简要介绍
研究人体相关技术(跟踪、行为、属性…)的一切前提是要把人物从图像/视频中定位出来。所以行人检测的首要目的就是获得人物在图像/视频中的位置信息。
(1)目标检测
目标检测的任务就是将目标从图像中定位出来(这里指矩形框),成功将图像中的所有行人,包括位置和大小信息获取到。这就是典型的目标检测问题。
行人检测按方法可分成传统方案和深度学习方案。
- 基于运动检测的算法,属于传统方案:通过背景建模在视频中提取运动目标,再通过分类器判断目标是否为人。存在的问题:受视频影响较大,视角要固定且环境噪声会影响;只能检测运动目标。
- 基于机器学习的算法,属于传统方案:候选框+手工特征提取+分类器。存在的问题:计算量大/速度慢;手工特征无法覆盖人体多样化情况;对于外观、视角、姿态各异的行人检测效果较差。
- 基于深度学习的算法:候选框+深度特征提取(卷积神经网络)+预测(分类+回归);存在的问题:数据不平衡(类别、尺度);行人遮挡;复杂背景。
而行人检测所存在的挑战也有很多。由下图所示,可以看到不同的人衣着、姿态都不一样;存在不同人物视角(背对、正对、侧对);并且存在人体图像不完整的情况(遮挡、图像外)。

由于行人的数据很容易收集,而且这项研究也持续了很多年。我们能很方便的找到许多开源的行人数据集,并且目前目标检测已有很多成熟的深度学习方案。在大数据时代下,针对这种多样化的人物视角、姿态和衣着,可以通过深度学习的方案得到有效的解决,例如RCNN系列目标检测、YOLO系列目标检测……基本上都可以解决日常场景下的行人检测问题。但是针对小目标、目标遮挡这些情况,许多研究者仍再不断的探索。
(2)人体分割
行人分割其实就是行人目标检测的一种,任务同样都是将人从图像中检测出来。只是需要逐点像素上进行分类,在精度要求上要高于矩形目标检测。所以在挑战上,同样拥有目标检测上所说的那些问题:数据不均衡、遮挡、场景/视角。因为分割广泛应用在在线直播(抠图)、自动驾驶、行人重识别,所以在技术上希望分割能达到一个实时检测,所以性能优化在分割领域上是个比较大的挑战,除此之外,目前还有一个很火的研究方向:3D人物分割,以及拓展的应用,三维人物重建等领域。
这里主要通过应用简单介绍深度学习的方案,常用的方案由FCN、SegNet、Unet系列、deeplab系列等。
Unet系列的模型参数会比较大,但相对的效果上表现会比较好。如下图所示,人物的发根细节都可以很好的分割出来。(图源 U-2Net论文: https://arxiv.org/pdf/2005.09007.pdf )

此外也有用U-2net做人物肖像画生成的。如下图,人物肖像画从结果上看有点类似与图像生成,但本质上还是对人物的细节特征进行分割。所以这里区别与生成式模型。(图源U2net源码仓库:https://github.com/xuebinqin/U-2-Net)

在直播场景中,也有对实时高清的视频人像进行前背景分割的研究,例如Background Matting;其中的图像分割网络就是利用了 Deeplabv3+来生成用于人物抠图的分割 mask。(下图源自Background MattingV2:https://github.com/PeterL1n/BackgroundMattingV2)

目前对人像分割的研究上大部分都是基于实际的业务应用来进行修改。比如直播场景下,首先要保证实时分割,其次在实时的前提下提升整体的精度和图像清晰度;而在一些场景,如自动驾驶、医学领域、人像美化,可能会更加注重人物的边缘轮廓细节,而去提高模型的精细度。
2. 行人跟踪简要介绍
跟踪区别于目标检测,跟踪是指在视频中将目标检测出来,并且区分出上下帧中相同的目标,获取其位置信息和运动轨迹。对于研究一个人的行为来讲,行为动作往往是有时序的,所以目标跟踪在研究人的领域里也是一个比较火热的场景。
行人跟踪的具体步骤:
- 运动模型/检测模型:如何产生候选目标,首先跟踪的前提是已有一个跟踪目标,然后需要在下一帧内找到候选目标进行对比。
- 特征提取:提取跟踪目标和候选目标的对比特征,可以是位置信息、人像特征、手工特征、深度特征(reid)……
- 观测模型:利用提取的特征在众多候选样本中进行评分。
- 模型更新:主要是更新观察模型,即更新跟踪目标的特征信息,由于环境的变化,同个目标特征信息变化也会比较大,此时如何适应目标表观特征的变化,防止跟踪过程中发送偏移。(ID-switch)需要制定合适的更新规则。
- 集成方法:由于跟踪可以通过不同特征,不同策略进行判断。因此要通过多个决策方案得到一个更优的决策结果。
下图是根据yoloV5进行行人检测,加上deepsort进行行人跟踪的实战视频截图。(源自:https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch)通过跟踪,我们可以捕获到当前场景的人流量,以及每个人的运动轨迹。(当然源码的跟踪也存在ID-switch现象,由于遮挡、小目标等检测的不稳定也会导致跟踪目标的丢失。)

3. 行人属性识别简要介绍
(1)人体姿态估计
人体姿态估计的任务就是在视频/图像上获取人体部位,并建立人体表征,如人体骨骼。这里主要介绍人体骨架识别。外貌、衣着、姿态、身体部位每个人都会有所差异,这就是不同人有着各自不同的属性。
人体骨架在近些年来广泛得到关注,是因为如果你要对一个人的行为进行分析、要对运动员进行运动分析、要进行人机交互、人体建模等,你首先都得知道人体的每个部位,而只要识别到骨架就可以明确的定位到人体的每个部位。(下图源自:https://arxiv.org/pdf/2012.13392.pdf)

目前人体姿态估计——关键点估计的主流算法主要分两种,一种为自下而上的方式,即先检测所有关键点,再连接成骨架,代表算法有openpose,通过预测整张图上的所有关键点以及关键点之间的亲和度,最后做匹配连接;还有一种为自上而下的方式,即先检测到人的位置,再对检测框内单人提取骨架,代表算法有Alphapose/RMPE。(下图为openpose的过程图,源自官方论文:https://arxiv.org/pdf/1812.08008.pdf)

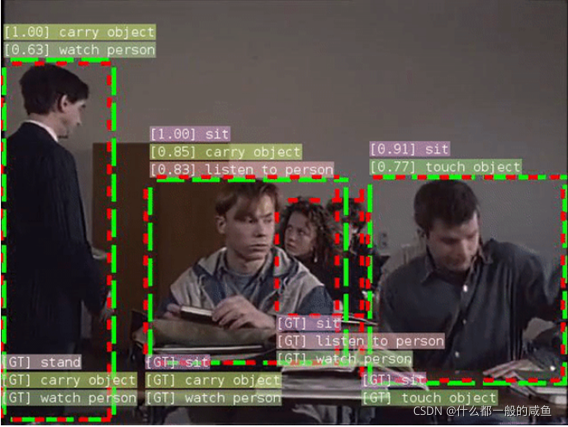
(2)行人属性识别 - 行为属性&基础属性
行为属性:
通过前面的知识,我们了解并以及知道目前能够对图像/视频中的人进行定位、跟踪、姿态估计,利用这些信息,我们就可以研究一个人的行为信息。行为在图像上表现为静态动作,例如,站着、躺着、举手…在视频上表现为动态动作,例如,打架、摔倒、跑…
对于静态动作,我们用分类模型就可以把大部分行为判断出来,而主要难点在于动态动作,因此,在行为识别的研究领域里,一直是对时域上的行为进行研究和分析,也就是对视频的动作理解。这个方向的主要目的就是获取某个人一段时间内的行为动作信息。
这里面最具挑战的一个方向应该属细粒度动作识别了,细粒度的目标就是从一个大类里面去将众多子类区分开来。比如在我们这里的人体行为识别里面,人是一个大类,其在图像上表现的特征非常相似,各种行为/动作就是它的子类,子类之间也有很多共性。同种子类之间会有差异性,比如每个人跑步的姿态可能大同小异;不同子类,动作、姿态和步态也可能有很大的相似性,例如跑步和走路、跳起和蹲下、摔倒和躺下……
目前解决行为识别的主流方案主要分为,基于视频理解的3D Conv(如下图,源自pytorchVideo仓库的演示视频:https://github.com/facebookresearch/pytorchvideo);还有基于人体关键点的行为识别,例如ST-GCN对序列关键点进行图卷积进行动作识别。
基础属性:
首先要明确什么是人的属性。这里其实归根结底就是研究人在视觉上展现的所有东西。
-
人的体貌特征:身高、体重、性别……(体重这个实际上在图像上展现不出来,但可以描述为胖子、瘦子。);
-
人的穿着:上衣、裤子(这里又可以细分多个类型、款式、颜色等特征)、其他物品(背包、手持物品…);
-
人脸特征:年龄、性别、人种、眼睛、发色、表情……
-
动作行为:跑、跳、走、骨骼形状(残疾人、手势、手脚特征)……

属性识别可以理解为将行人的各个属性进行结构化,至于每个点的范围多广、粒度多细,很多团队也在对不同点做相关的研究尝试。但总体上,目前大部分方法也是基于深度学习的方法进行,例如有通过多任务的方法(DeepSAR、DeepMar),或者利用多个模型集成检测和识别人物属性。各项任务也一直还是在不断的探索研究。
4. 总结
本文章为小编自己总结的一些关于人体相关技术的简要概述,相关技术点的背景、难点、解决方案只是简单的介绍。各个小点将在后续的文章继续深入细化以及相关源码的介绍。

















 2068
2068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









