









正文
pandas 是一个 “开放源代码,使用 BSD 许可证的库,它为 Python 编程语言提供高性能、易用的数据结构和数据分析工具”(摘自 pandas 网站)。总的来说,它提供了叫做 DataFrame 和 Series 的数据抽象(已不推荐使用 Panel),它管理索引以实现数据的快速存取,它执行分析和转换运算,它甚至能(使用 matplotlib 后端)画图。
一、所需数据
我们选择的数据集是(来自 Kaggle)的玩具数据集 “1985 到 2016 年国家自杀率”。这个数据集虽然简单,但对于你上手 pandas 已经足够了。
在深入研究代码之前,如果你想重现结果,还需要执行这个简短的数据预处理过程,以确保你拥有正确的列名和列类型。
import pandas as pd
import numpy as np
import os
# to download https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016
data_path = 'path/to/folder/'
df = (pd.read_csv(filepath_or_buffer=os.path.join(data_path, 'master.csv'))
.rename(columns={'suicides/100k pop' : 'suicides_per_100k',
' gdp_for_year ($) ' : 'gdp_year',
'gdp_per_capita ($)' : 'gdp_capita',
'country-year' : 'country_year'})
.assign(gdp_year=lambda _df: _df['gdp_year'].str.replace(',','').astype(np.int64))
)
原始数据

处理后的数据

df.columns
>Index(['country', 'year', 'sex', 'age', 'suicides_no', 'population',
'suicides_per_100k', 'country_year', 'HDI for year', 'gdp_year',
'gdp_capita', 'generation'],
dtype='object')
这里有 101 个国家,年份从 1985 到 2016,有两种性别,六个世代以及六个年龄段。使用一些简单而有用的方法,我们就可以获得这些信息。
- unique() 和 nunique() 用来获取去除了重复值的列(或去重列中的元素数目)
df['generation'].unique()
>array(['Generation X', 'Silent', 'G.I. Generation', 'Boomers',
'Millenials', 'Generation Z'], dtype=object)
df['country'].nunique()
>101
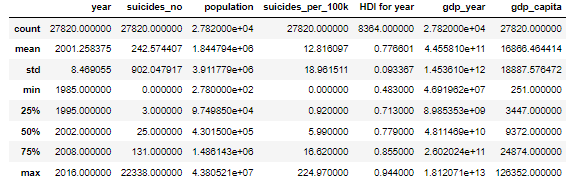
- describe() 为每一个数值列输出不同的统计数字(例如:最小值,最大值,均值,个数),如果设置参数 ‘include=all’ 则还会显示每个对象列去重后的元素个数以及顶部元素(即频率最高的元素)的个数。
- head() 和 tail() 用来显示数据框的一小部分
二、索引
pandas 虽然强大,但也要付出一些代价。当你加载一个 DataFrame 时,pandas 会创建索引并在 numpy 数组内部存储数据。所以这意味着什么呢?意味着一旦加载了数据,只要索引管理得当,你就可以快速存取它们。
存取数据的方式主要有两种:索引(index)和查询(query),不同情况下你对这两种方式的选择也会不一样。但在大多数情况中,索引(和多索引)都是最佳选择。我们来看下面的例子:
>>> %%time
>>> df.query('country == "Albania" and year == 1987 and sex == "male" and age == "25-34 years"')
CPU times: user 7.27 ms, sys: 751 µs, total: 8.02 ms
# ==================
>>> %%time
>>> mi_df.loc['Albania', 1987, 'male', '25-34 years']
CPU times: user 459 µs, sys: 1 µs, total: 460 µs
你可能马上会问自己,创建多索引需要花费多长时间?
%%time
mi_df = df.set_index(['country', 'year', 'sex', 'age'])
CPU times: user 10.8 ms, sys: 2.2 ms, total: 13 ms
采用查询花费的时间是这里的 1.5 倍。如果你只需要检索一次数据(这种情况很少见),query 是合适的方法。否则,坚持使用索引吧,你的 CPU 会感谢你的。
.set_index(drop=False) 保证不会删除作为新索引的列
当你想要查看数据框时,采用 .loc[] / .iloc[] 方法的效果非常好,但当你要修改数据框时,采用它们的效果就没那么好了。如果你需要手动(例如:使用循环)构建数据框,请考虑其他数据结构(例如:字典,列表)并在你准备好了所有数据时创建你的 DataFrame. 否则,对 DataFrame 中的每一个新行,pandas 都会更新索引,而这种更新并不是一次简单的哈希映射。
创建DateFrame
pd.DataFrame({'a':range(2), 'b': range(2)}, index=['a', 'a']).loc['a']
正因如此,一个未排序的索引会降低运行效率。为了检查索引是否排序和对索引进行排序,主要采用如下两个方法。
%%time
>>> mi_df.sort_index()
CPU times: user 34.8 ms, sys: 1.63 ms, total: 36.5 ms
>>> mi_df.index.is_monotonic
True
三、方法链
DataFrame 中的方法链是一种链接多种方法并返回一个数据框的行为,这些方法来自于 DataFrame 类。pandas 现在的版本中,使用方法链的原因是这样不用存储中间变量,且能避免下述情形的发生:
import numpy as np
import pandas as pd
df = pd.DataFrame({'a_column': [1, -999, -999],
'powerless_column': [2, 3, 4],
'int_column': [1, 1, -1]})
df['a_column'] = df['a_column'].replace(-999, np.nan)
df['power_column'] = df['powerless_column'] ** 2
df['real_column'] = df['int_column'].astype(np.float64)
df = df.apply(lambda _df: _df.replace(4, np.nan))
df = df.dropna(how='all')
我们使用下面的方法链替代上述代码。
df = (pd.DataFrame({'a_column': [1, -999, -999],
'powerless_column': [2, 3, 4],
'int_column': [1, 1, -1]})
.assign(a_column=lambda _df: _df['a_column'].replace(-999, np.nan),
power_column=lambda _df: _df['powerless_column'] ** 2,
real_column=lambda _df: _df['int_column'].astype(np.float64))
.apply(lambda _df: _df.replace(4, np.nan))
.dropna(how='all')
)
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
方法链的工具箱中包含许多将 DataFrame 或者 Series (或者 DataFrameGroupBy) 对象作为输出的方法(例如:apply, assign, loc, query, pipe, groupby, agg)。
理解这些方法最好的方式就是实践,让我们从一些简单的例子开始。
获得每个年龄段世代的简单方法链
(df
.groupby('age')
.agg({'generation':'unique'})
.rename(columns={'generation':'unique_generation'})
# Recommended from v0.25
# .agg(unique_generation=('generation', 'unique'))
)

产生数据框,age 列为索引
从上表我们知道 “世代 X” 覆盖三个年龄段(译者注:作者笔误,实为 4 个),此外让我们来分解一下这条方法链。第一步按年龄段分组,这一方法返回一个 DataFrameGroupBy 对象,在这个对象中,每一组将汇总该组对应的世代标签。
尽管在这个案例中,汇总方法采用 unique,但实际上任何(匿名)函数都是可以的。
在最新的发行版本(v0.25)中,pandas 引入了一种新的使用 agg 的方式。
(df
.groupby(['country', 'year'])
.agg({'suicides_per_100k': 'sum'})
.rename(columns={'suicides_per_100k':'suicides_sum'})
# Recommended from v0.25
# .agg(suicides_sum=('suicides_per_100k', 'sum'))
.sort_values('suicides_sum', ascending=False)
.head(10)
)

使用 sort_values 和 head 获得自杀率较高的国家和年份
(df
.groupby(['country', 'year'])
.agg({'suicides_per_100k': 'sum'})
.rename(columns={'suicides_per_100k':'suicides_sum'})
# Recommended from v0.25
# .agg(suicides_sum=('suicides_per_100k', 'sum'))
.nlargest(10, columns='suicides_sum')
)

使用 nlargest 获得自杀率较高的国家和年份
这两段程序的输出是相同的:拥有二水平(two level)索引的一个 DataFrame 和包含最大 10 个值的一个新列 suicides_sum,但是nlargest(10) 比 sort_values(ascending=False).head(10) 更有效率。
下一个方法 pipe 是用途最广泛的方法之一,就像 shell 脚本一样,pipe 方法执行管道运算,它让方法链可以执行更丰富的运算。pipe 的一个简单却强大的用法是用来记录不同信息。
def log_head(df, head_count=10):
print(df.head(head_count))
return df
def log_columns(df):
print(df.columns)
return df
def log_shape(df):
print(f'shape = {df.shape}')
return df
使用管道的不同记录函数
(df
.pipe(log_shape)
.query('sex == "female"')
.groupby(['year', 'country'])
.agg({'suicides_per_100k':'sum'})
.pipe(log_shape)
.rename(columns={'suicides_per_100k':'sum_suicides_per_100k_female'})
# Recommended from v0.25
# .agg(sum_suicides_per_100k_female=('suicides_per_100k', 'sum'))
.nlargest(n=10, columns=['sum_suicides_per_100k_female'])
)
在女性中,自杀率较高的国家和年份

除了向命令行解释器输出记录,我们还可以使用 pipe 直接将函数作用到数据框列上。
from sklearn.preprocessing import MinMaxScaler
def norm_df(df, columns):
return df.assign(**{col: MinMaxScaler().fit_transform(df[[col]].values.astype(float))
for col in columns})
for sex in ['male', 'female']:
print(sex)
print(
df
.query(f'sex == "{sex}"')
.groupby(['country'])
.agg({'suicides_per_100k': 'sum', 'gdp_year': 'mean'})
.rename(columns={'suicides_per_100k':'suicides_per_100k_sum',
'gdp_year': 'gdp_year_mean'})
# Recommended in v0.25
# .agg(suicides_per_100k=('suicides_per_100k_sum', 'sum'),
# gdp_year=('gdp_year_mean', 'mean'))
.pipe(norm_df, columns=['suicides_per_100k_sum', 'gdp_year_mean'])
.corr(method='spearman')
)
print('\n')
自杀数的增长与 GDP 的降低有关吗?自杀数与性别相关吗?
在命令行解释器中,上面的代码打印出如下结果:
male
suicides_per_100k_sum gdp_year_mean
suicides_per_100k_sum 1.000000 0.421218
gdp_year_mean 0.421218 1.000000
female
suicides_per_100k_sum gdp_year_mean
suicides_per_100k_sum 1.000000 0.452343
gdp_year_mean 0.452343 1.000000
让我们深入研究一下代码。norm_df() 将 DataFrame 和数据框列索引构成的列表作为输入,然后使用 MinMaxScaling 对数据作标准化处理。通过使用字典生成式,norm_df() 创建了一个字典 {column_name:method, …},字典随后被解压为 assign() 的参数 (column_name=method, …)。
在这个特别的例子中,最小最大标准化并不会改变相关系数的输出结果,它的引入只是为了论证 pipe 可以将函数直接作用到数据框列上 😃
四、最后的建议
- itertuples() 比通过数据框行迭代要更有效率
>>> %%time
>>> for row in df.iterrows(): continue
CPU times: user 1.97 s, sys: 17.3 ms, total: 1.99 s
>>> for tup in df.itertuples(): continue
CPU times: user 55.9 ms, sys: 2.85 ms, total: 58.8 ms
















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











