







目录
Keras FCN-8 实现
FCN简介
- Fully Convolution Network For Semantic Segmentation(全卷积网络 for 语义分割)
- arXiv:1411.4038 第一次发表
- arXiv:1605.06211 正式发表
- 全卷积
- 多层Feature跳接结构(Skip Architeture)
使用的网络结构基础是VGG网络 VGG网络中含有5个池化操作 每一次池化操作把原图像在像素级上缩小了2倍
总共加起来就是缩小了32倍(2^5),也就是说VGG网络把原输入图片在像素上下采样了32倍。
那么我们就可以通过32倍的上采样操作把VGG网络的输出还原到与原图等大的像素级分类结果
这个结果可以作为语义分割的结果。
那么我们采用什么样的方式来把网络的输出还原到与原图等大的像素级分类结果呢?
FCN-转置卷积(transposed conv)
输出尺寸>输入尺寸
- 不代表是卷积的逆运算
- 这里指的是可以把网络的形状进行进行还原,但不代表在数值上也进行了还原
- 因为我们在网络进行前向传播的过程中使用了下采样操作(5次)这是有损操作
(H,W)output =((H,W)input-1) *Stride+(H,W)kernel-padding*2
转置卷积的输出尺寸 = (输入特征尺寸-1)*滑动幅度+卷积核的尺寸-填充方式*2
padding = valid 值为0
padding = same 值为1
回顾VGG网络 (仅画出了关键的网络层次结构)

这里的池化层stride=2经过池化层之后FeatureMap会变为原来的一般
fc6之前的卷积操作都是使用stride = 1,padding = same ,经过这样的卷积图片的尺寸不会发生改变
在fc6之间的特征尺寸是 7*7 我们使用一个尺寸为7*7的卷积核来对这进行一次卷积(padding = valid)得到1*1*4096的特征
这样的操作我们是用卷积来代替全连接,因为卷积相对全链接有着更多的优点,比如参数共享,不会限制(一定程度内)输入特征的尺寸。
到此是VGG网络结构自身的知识。那么在FCN中是怎么使用VGG网络来用于语义分割的呢?
FCN中的VGG变化
上图为VGG网络结构,在FCN 中我们在从pool5 到 fc6 的过程中使用padding为same的方式进行卷积,
是图片特征的尺寸不改变大小
则fc6:7*7*4096 fc7:7*7*4096 fc8(分类器):7*7*1000
我们通过是用改变过的VGG网络得到的输出是7*7*1000
这里的1000可以理解为1000个分类(ImageNet上1000分类)
而2维7*7代表着一个分类的结果
可以理解为7*7大小像素级的分类情况
这个输出结果的一个像素点映射到原图代表这32倍的像素点。
我们称这个像素分类结果为Heat map(粗略的像素级分类结果)
还原大小
我们把这个粗略的像素级分类结果放大32倍就得到了与原图等大的语义的分类结果吗? 是的FCN里面就是这样做的
在FCN中还原的方式使用的转置卷积
这里的转置卷积操作有一点特殊的处理:使用双线性插值类初始化转置卷积的卷积核
在FCN论文中作者指出这个双线性差值的卷积核如果是固定的,那么网络的学习效果会比较好,
所以我们在训练工程中把双线性插值的卷积核的学习率设置为0.。
这步:我们是把输出结果还原到与输入尺寸相同的大小,但是因为这种方式是 之直接进行上采样32倍,所以效果不是很好
也就是还原之后的图片模糊边界不清晰之类的。
现在的Heat map 看起来就是一样有不同颜色模糊的形状的区域,根本看不出来是什么。
FCN-CRF
我们有一种情况可以优化这个还原之后的结果
我们优化之后,如果原图是一辆车的话,我们能看到一个有一种颜色的有轮廓的车的形状,相对于之前好太多了。
我们这里优化使用的是FCN—CRF(conditional random fields)条件随机场
概率论中的知识点,不会全部知识点,只说一下大概。
这里主要是通过其中的一个能量函数E来实现的优化
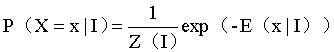
![]()
这个能量函数有两部分组成 第一部分代表双线性插值之后的结果 第二部分是运算每2个像素是否属于同一分布的关系
到此我们网络使用的是把下采样32倍的输出特征再还原到原输入图片的大小的像素级分类结果
这样我们称其为FCN-32
FCN-16
除了FCN-32,还有FCN-16,FCN-8 网络结构。
FCN-16其实就是使用了 32倍下采样语义分类器+16倍下采样语义分类器 来并行训练进行语义分类。
我们把网络结构中32倍的输出结果 先上采样到16倍 也就是放大2倍。
然后把16倍下采样的输出结果和其拼接在一起,然后再上采样16倍 到原图大小。
论文中的一点技巧
理解的不好有点说不明白
FCN 论文中 作者使用的输入图片是比元VGG网络大的,在我们网络最后输出的时候是比原图大一些的,
然后进行裁剪,这样可以保留一些余地
对比8层,16层,32层
在卷积网络中有一种说法就是,在浅的网络层次,包含的更多的细节的信息,而包含的语义上的信息是比较少的,
随着网络的加深,网络层次学到了更多的语义上面的信息,但是却会丢掉一些细节上面的信息。
在这里也是一样
在细节上:8 > 16 > 32
在语义上:8 < 16 < 32
而在像素级上的语义分割主要是根据图片中的细节信息。
所以语义分割的效果:8 > 16 > 32
我们可以去除池化层吗?
VGG网络中使用池化的操作来改变输入特征的形状,但是池化这中操作是有损操作会造成一定程度的数据丢失,。
但是在正常情况的FCN中我们是不能直接去掉池化层的
因为在FCN中使用的是在ImageNet预训练的VGG网络 我们去掉池化层 原本图片会缩小,变成不会缩小,
会与元网络层次的参数不一致。
Atrous conv/Dilated conv
多孔卷积/膨胀卷积
可以解决这一问题
多孔卷积/膨胀卷积 是一种特殊的卷积核。
原来3*3的卷积核

多孔卷积卷积核,膨胀卷积卷积核

膨胀卷积在进行卷积操作时会跳过一些是数据,
它主要有两个特点:1如图所示他能够扩张感受野 2 在进行的卷积之后他能够缩小特征图
其实通过把padding 改为 same 一系列处理也可以使膨胀卷积之后不改变特征图大小。
在原VGG网络中如果我们直接去掉池化层 那么原本的卷积层的卷积核的感受也是不够 去提取未缩小的尺寸的特征图。
我们使用膨胀卷积可以解决这问题,同时使用膨胀卷积还能够是特征图缩小。
也就是说在去掉池化层之后,在池化之后的卷积层上使用膨胀卷积 就不会有之前的问题。也就是ImageNet 上预训练的权重仍然能够使用。
在FCN中使用膨胀卷积的好处:1我们避免了使用池化操作造成了丢失细节信息的不好的效果
2我们可以控制 最后网络输出的下采样程度,我们使用
自己的思考?可能不对
问题:
我们使用池化操作 是原特征图尺寸缩小了一半 我们称为下采样 ,那么我们使用 膨胀卷积 之后特征图也 缩小了 这一过程叫下采样吗 ?有点不明白
我们FCN在原VGG网络结构中,使用了5次池化操作,最后我们输出heat map (score map)是原图的32倍
这里的5次有损下采样?这五次池化中我们都不可避免的丢失了细节。
我查了一下资料,说的是在图像上该表了图像的大小就叫采样,缩小了就可以叫做下采样。
假如我们使用一次膨胀卷积操作来替代一次池化操作,
那么我们进行了4次有损(4次池化 )下采样操作+ 膨胀卷积所带来的特征图缩小(下采样)假设这个操作也缩小了一半特征图。
膨胀卷积带来的细节丢失程度和池化是比不了的~。
我们最后输出的score map 就是相当于原VGG网络在16下采样处的语义分割分类器
我们可以通过替换池化的层数 来调正 原来下采样32 输出的 下采样程度 。
替换一层 下采样程度就是变成 下采样16 以此类推。
Deep Lab V2
多孔空间金字塔池化结构

我们有一输入特征图Input Feature Map
我们采用分支结构 类似于inception网络结构
使用孔间距不同的多孔卷积
不同的孔间距代表不同的感受野
之后使用相加的方式把不同的结果进行融合,这点类似于resnet
GCN
Large Kernel Matters:大内核思想
感受野与输入特征图等大的时候可以对整体图片进行特征提取和分类输出。
大内核:与输入特征等大的卷积核

在这个网络中我们没有使用VGG网络作为基础,我们使用的是res-net网络。
我们先输入了一个特征图,经过卷积,再经过resnet 输出不同尺寸的特征图,
接着再用不同的大内核来对其进行特征提取并接上一步BR操作。
之后我们通过使用转置卷积Deconv来把这些分支输出融合在一起最后得到了一个Score map
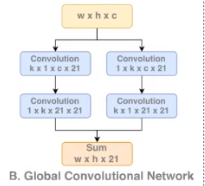
关于使用大内核进行特征提取的GCN内部操作中,我们没有使用k*k的操作而是使用非对称卷积,k*k 运行慢计算量大,
使用k*1 和1*k的非对称卷积也能够 达到k*k 一样的效果,运算量降低了。
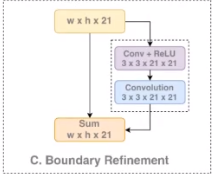
Boundary Refinement
其实就一个residual操作(跳接)
主要是为了解决边界信息丢失的问题,而一般边界信息丢失的信息就是一些底层的细节信息。
而这种跳接操作可以把这些细节信息传到网络的深层中去。
GCN算法 特点是速度比较慢 以为使用了大核 但是效果还不错~
Deep Lab V3

arXiv1703.05587
这是一边非常值得读我们去拜读的论文
这边论文是对我们之前语义分割网络中各中网络结构中探究,
在深度学习领域中我们知道这块理论上的支撑是比较少的,这样探究型论文就更加显得意义非凡,
我之后一定会去看这边论文的。
论文中作者是对我们之前语义分割网络中各中网络结构中探究,调整不同的网络结构来分析对网络学习和预测效果的影响。
并以百分比的方式显示出探究结果。
Deep Lab V3+
arXiv:1802.02611
这篇论文是建立在Deep Lab V3 基础上,在上次论文中挑选出效果较好的几种结构构成了这篇论文,
- 论文是以Xinception为基础的:大量使用深度可分离卷积的网络结构,效率较高
- 融合了多空卷积结构和ASPP(多孔空间金字塔池化)
- 使用Encoder和Decoder结构

Encoder使用了多种效果较好的结构的组成而成的网络,但是由于使用了多孔空间金字塔池化等操作。
网络中的边界信息丢失较为严重。
Incoder 是用来修复尖锐边界信息的。
总的来说这个网络结构效果非常好有这较高的准确度,语义分割的边界也清晰。
Keras FCN-8 实现
FCN-8其实就是使用了 32倍下采样语义分类器+16倍下采样语义分类器+8倍下采样语义分类器 来并行训练进行语义分类。

图中为FCN-8网络结构
可以看到我们网络的输入是形状为 320 320 3 的 feature map。
block3_pool 的输出形状是 40 40 256 与输入相比是8被的下采用率(理解上可以只考虑长宽,不考虑通道数是多少)。
之后把 40 40 256 输入 score_pool3 输出 40 40 15 。已知15是我们的分类的总数 15 对应这我们这里的通道 。
每一个通道对应一个类别的分类的概率,其中40*40 对应该类别像素图片级的语义分割结果。
block4_pool对应这16倍下采样率 block5_pool对应这32倍下采样率
之后我们把32被下采样率的结果 即10 10 15 使用转置卷积 还原到 20 20 15 大小 并 与 block4_pool 输出的 16 倍结合到一起。
之后在把这个结合后的 下采样率结果 使用转置卷积还原到8 被下采样结果。并与score_pool3 结合 。
最后把这个结合到一起的下采样分类结果(40 40 15) 还原到 原图的大小(320 320 15)
这里对应原图的像素级的语义分解结果。15个通道对应每个类别分类结果。
之后使用softmax 得到分类结果。
def FCN_8S(nClasses, input_height=320, input_width=320, nChannels=3):
inputs = Input((input_height, input_width, nChannels))
conv1 = Conv2D(filters=32, input_shape=(input_height, input_width, nChannels),
kernel_size=(3, 3), padding='same', activation='relu',
name='block1_conv1')(inputs)
conv1 = Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu',
name='block1_conv2')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2), name='block1_pool')(conv1)
conv2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu',
name='block2_conv1')(pool1)
conv2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu',
name='block2_conv2')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2), name='block2_pool')(conv2)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv1')(pool2)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv2')(conv3)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv3')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2), name='block3_pool')(conv3)
#8倍下采样结果
score_pool3 = Conv2D(filters=3, kernel_size=(3, 3),padding='same',
activation='relu', name='score_pool3')(pool3)
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv1')(pool3)
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv2')(conv4)
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv3')(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2), name='block4_pool')(conv4)
#16倍下采样结果
score_pool4 = Conv2D(filters=3, kernel_size=(3, 3),padding='same',
activation='relu', name='score_pool4')(pool4)
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv1')(pool4)
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv2')(conv5)
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv3')(conv5)
pool5 = MaxPooling2D(pool_size=(2, 2), name='block5_pool')(conv5)
fc6 = Conv2D(filters=1024, kernel_size=(1, 1), padding='same', activation='relu',
name='fc6')(pool5)
fc6 = Dropout(0.3, name='dropout_1')(fc6)
fc7 = Conv2D(filters=1024, kernel_size=(1, 1), padding='same', activation='relu',
name='fc7')(fc6)
fc7 = Dropout(0.3, name='dropour_2')(fc7)
#32倍下采样结果
score_fr = Conv2D(filters=nClasses, kernel_size=(1, 1), padding='same',
activation='relu',name='score_fr')(fc7)
#Conv2DTranspose转置卷积
score2 = Conv2DTranspose(filters=nClasses, kernel_size=(2, 2), strides=(2, 2),
padding="valid", activation=None,
name="score2")(score_fr)
#32倍下采样结果和16倍下采样结果相加
add1 = add(inputs=[score2,score_pool4], name="add_1")
score4 = Conv2DTranspose(filters=nClasses, kernel_size=(2, 2), strides=(2, 2),
padding="valid", activation=None,
name="score4")(add1)
#32倍下采样结果和16倍下采样结果相加后与8倍下采样率
add2 = add(inputs=[score4,score_pool3], name="add_2")
#使用转置卷积还原到原图大小的语义分割结果
UpSample = Conv2DTranspose(filters=nClasses, kernel_size=(8, 8), strides=(8, 8),
padding="valid", activation=None,
name="UpSample")(add2)
outputs = core.Activation('softmax')(UpSample)
model = Model(inputs=inputs, outputs=outputs)
adam = optimizers.Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None,
decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=adam,
metrics=['accuracy'])
model.summary()
return model















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









