







前言
首先,“特征匹配损失”不是指特征匹配任务的损失函数,而是用与GAN网络中的一种损失函数。特征匹配损失函数能有效的解决GAN中生产器与判别器不能相互对抗(比如说判别器loss很低,但生成器loss一直很高,两者训练无法产生对抗效果)。
我正是在使用GAN结构是出现了上述的问题(早期行为预测,Hardnet网络中的G_rof_loss),发现DCGAN中的二分类交叉熵损失函数并不能使对抗结构有效运行,根据这篇文章提示GAN–提升GAN训练的技巧汇总.,使用特征匹配损失函数.
其他搜索关键词
Feature map Loss,FML,感知损失
原理
原来的二分类生成器只是,只能依靠判别器最后生产的一个数值来计算损失函数,这对于生产器来说参考数据太少了。而特征匹配损失的原来就是在能使用更多的数据来计算loss。特征匹配损失将判别器的中间层数据保存下来,用这些数据来计算loss。
公式
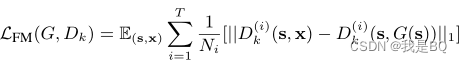
D
k
(
)
D_k()
Dk()就是判别器中间层的输出,T就是中间层的数量(GAN结构一般都是几层作为几个模块,这里的层数准确来说是模块数)。公式对可以看出是使用真图输入判别器的中间层输出与生产图输入判别器的中间层输出求L1范数(也可以求L2),最后将各层的结果求平均。
提示
1、特征匹配损失只是用于生成器的损失函数,判别器还是使用二分类交叉熵损失函数
2、特征匹配损失常出现在一些风格融合GAN网络中(AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation)
部分参考代码(pytorch)
损失计算函数,hard就是真图片,latent就是生成图片
class G_rof_loss(nn.Module):
def __init__(self,device):
super().__init__()
self.device = device
def g_rof_loss(self,D_f_hard_mid, D_f_latent_mid, weight=None, ignore_index=-100,
reduction='mean'):
mid_layer_num = len(D_f_hard_mid)
batch_size = D_f_hard_mid[0].size(0)
loss=torch.zeros(mid_layer_num, dtype=torch.float32).cuda(self.device)
for mid_layer_i in range(mid_layer_num):
if D_f_hard_mid[0].size() != D_f_hard_mid[0].size():
raise ValueError("G_rof_loss(mid_layer_{}):Using a D_f_hard size ({}) that is different to the D_f_latent size ({}) is deprecated. "
"Please ensure they have the same size.".format(mid_layer_i,D_f_hard_mid.size(), D_f_hard_mid.size()))
rof_loss=nn.MSELoss(reduction='mean')(D_f_hard_mid[mid_layer_i], D_f_latent_mid[mid_layer_i])
loss[mid_layer_i]=rof_loss
return torch.mean(loss)
def forward(self, D_f_hard_mid, D_f_latent_mid):
l_G_rof = self.g_rof_loss(D_f_hard_mid, D_f_latent_mid)
return l_G_rof
输入损失函数的数据(rof_mid)生成(从判别器,命名为D_rof)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
class rof_discriminator(nn.Module):
def __init__(self, channels, graph='graph.ntu_rgb_d.Graph', graph_args={'labeling_mode': 'spatial'}, num_person=2,
num_point=25):
super(rof_discriminator, self).__init__()
ndf=128
self.rof_1=nn.Sequential(
# input is (nc) x 25
nn.Conv1d(256, ndf * 2, 3, 2, 4, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 16
)
self.rof_2=nn.Sequential(
# state size. (ndf) x 16
nn.Conv1d(ndf * 2, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm1d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 8
)
self.rof_3 = nn.Sequential(
# state size. (ndf*2) x 8
nn.Conv1d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm1d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 4
)
self.rof_4 = nn.Sequential(
# state size. (ndf*4) x 4
nn.Conv1d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm1d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 2
)
self.rof_end = nn.Sequential(
# state size. (ndf*8) x 2
nn.Conv1d(ndf * 8, 1, 2, 1, 0, bias=False),
nn.Sigmoid()
)
self.rof_1.apply(weights_init)
self.rof_2.apply(weights_init)
self.rof_3.apply(weights_init)
self.rof_4.apply(weights_init)
self.rof_end.apply(weights_init)
def forward(self, input):
N, C, T = input.size()
rof_1=self.rof_1(input)
rof_2=self.rof_2(rof_1)
rof_3 = self.rof_3(rof_2)
rof_4 = self.rof_4(rof_3)
rof_end = self.rof_end(rof_4)
rof_mid=[rof_1,rof_2,rof_3,rof_4]
return rof_end.view(-1),rof_mid

















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









