






GAN(一)先验知识
GAN(三)变种介绍
损失函数(LossFunction)
前一节我们简单介绍了损失函数以及KL散度,JS散度等先验知识。下面直接放上来GAN的损失函数,是不是看起来一头雾水,别怕,等我们细细拆解。
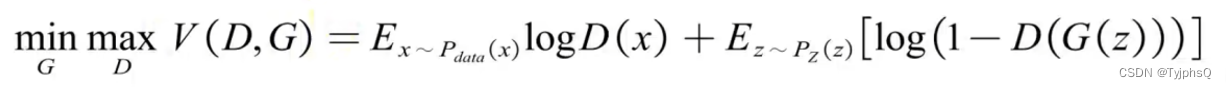
这里损失函数V(D,G), 其中D 是判别器(Discriminator) ,G 是生成器(Generator)。
其中 max 代表,固定G,调整D,使得损失函数最大化,就是提高判别器的能力,在判别器眼里,这应该是两种不同的分布,优化目标就是去最大化两个分布的区别
其中 min 代表,固定D。调整G,使得损失函数最小化,就是提高生成器的能力,在生成器眼里,这应该是两种相同的分布,优化目标就是去最小化两个分布的差距
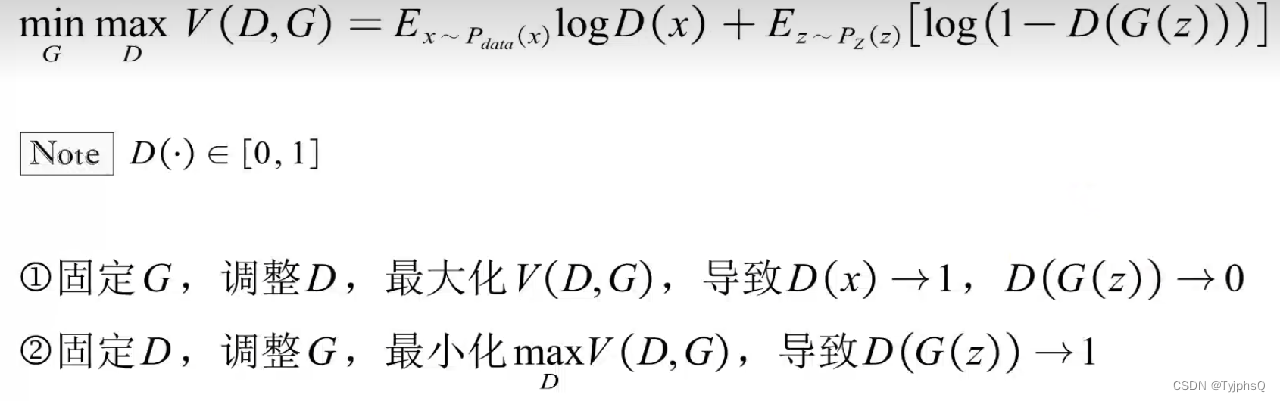
X 是真实数据,G(z)是生成的数据,所以有D(x) -> 1, D(G(z))-> 0.
生成器目标是尽可能欺骗判别器,也就是 D(G(z))-> 1.
推导过程

上式中,我们目标是max V(D,G),即固定G,调整D,那么G不受影响,G(z)是近似X的分布,这里我们换元,后半部分,就变成了对x的积分,噪音的分布也写成,目标函数就统一成了对x的积分,有利于下一步的求最值。
要求调整D,求最值,于是对D进行求导,找驻点嘛。(注意,只是对D求导,并不对x进行求导)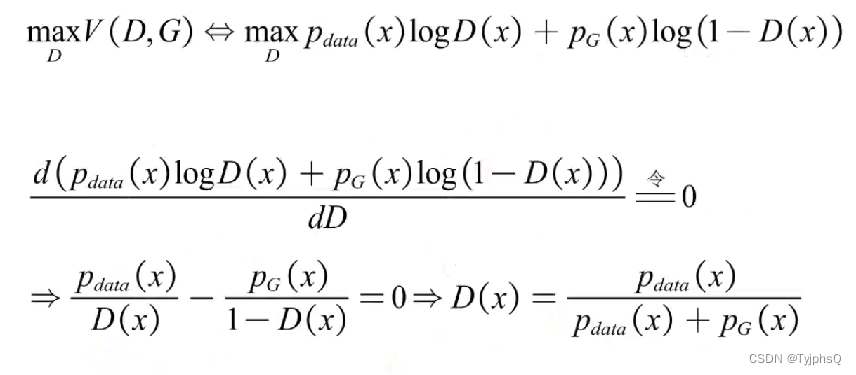
求导结果如上,,
相当于一个常数,于是可以反解出D(x)
再将D(x)代入,固定D,调整G。
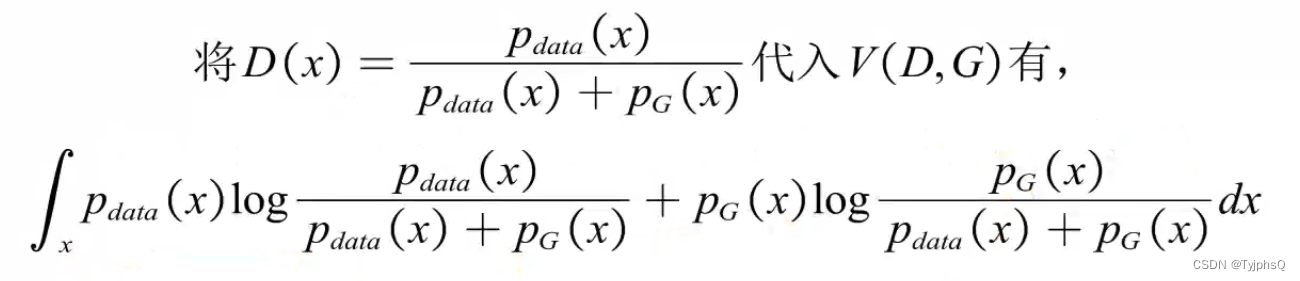
这个形式不就是两个KL散度嘛,于是乎,对上式进行变化
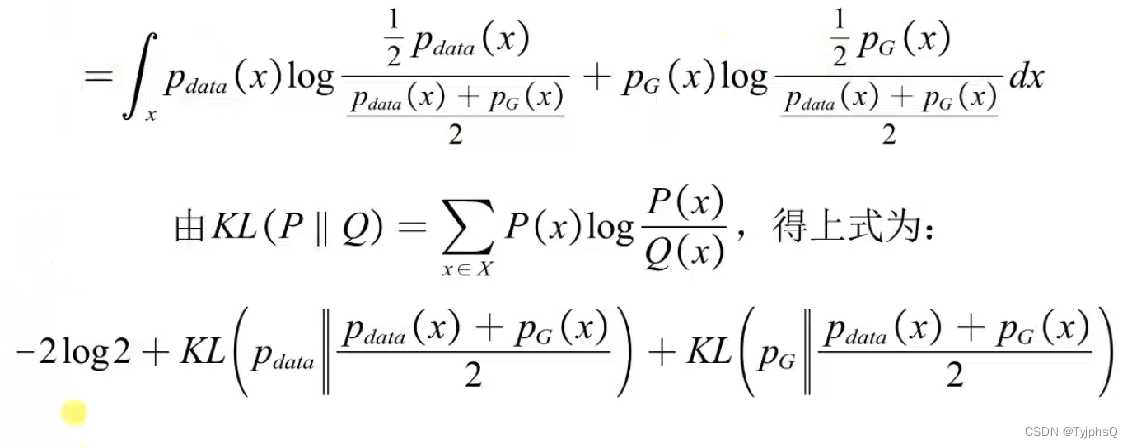
上式分子分母同时除2,是为了构造JS散度,于是优化目标如下。
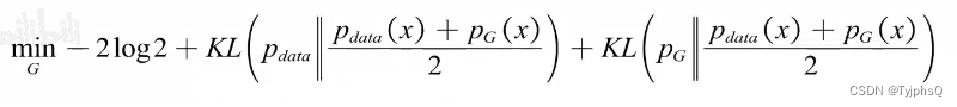
前面是常数,后面一部分写成JS散度
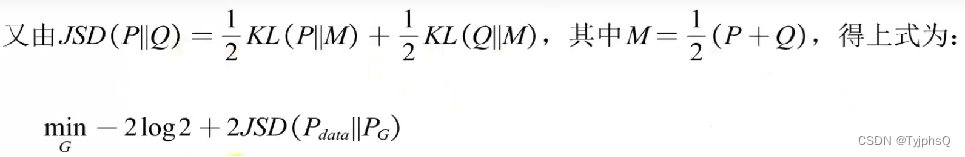
![]()
至此,损失函数的推导过程完毕,相信你也明白了为什么最初的损失函数是这样的
参考链接:https://www.cnblogs.com/qiynet/p/12304004.html
GAN原理-听不懂不要钱,哦对,本来我也不要钱_哔哩哔哩_bilibili
GAN原论文网盘:https://pan.baidu.com/s/1xsSk3KSSkqx5xwnVRq6JnA
提取码:78w7
GAN汇报PPT:https://pan.baidu.com/s/1PUFK8pKVjTzhneA6Ugq2jQ
提取码:a7ob















 2134
2134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









