







网课:https://space.bilibili.com/74997410/#/
(1)https://www.bilibili.com/video/av9831889
PPT:http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching_files/intro_RL.pdf
参考:https://blog.csdn.net/songrotek/article/details/50572935

David Silver深度强化学习第1课 intro-RL

Agent(我们创建的算法)
算法就是一个从history映射到action的过程,其中history:
由于history包含了太多冗长的信息,因此我们用state代替history。
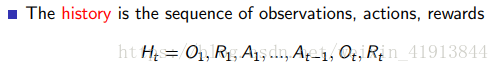
State
state is a function of history
两种形式的state
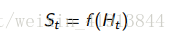
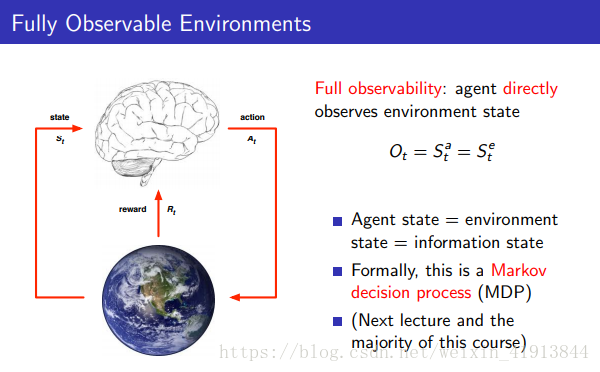
- environment state(环境状态)
是环境信息的展示,通常不可视,即使可见也会包含不相关信息 - agent state
也是数字形式。whatever information the agent uses to pick the
next action
以上两种状态的数学形式是Markov状态。 Markov状态具有Markov性质:将来的状态St+1只与现在的状态St有关,而与过去的状态无关。(状态表示法)。现在的状态St决定了未来所有的观测、状态、奖励、行动。
使用RL时,我们的主要任务即在完全可观测环境下创建agent状态,并以此决定下一步的policy。




















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









