







1. 概述
Flink 是一种开源的分布式计算框架,专为处理大规模数据流而设计。它能够在低延迟和高吞吐的场景下高效地处理实时和批量数据。Flink 的全称是 Apache Flink,它是 Apache 软件基金会的顶级项目之一。
1.1 Flink 的核心特点
-
统一的流处理和批处理架构:Flink 的核心是一个流处理引擎,所有的数据都被视为数据流。实时流处理:Flink 能够实时处理无限的数据流(如事件日志、传感器数据)。批处理:Flink 将批处理视为有限数据流的特例,因此可以高效地处理批量数据。
-
低延迟和高吞吐:Flink 支持事件驱动的计算模型,能够以毫秒级延迟处理数据,同时保持高吞吐量。
-
事件时间支持:Flink 对事件时间有原生支持,可以根据数据的发生时间(而非到达时间)进行处理。这使得 Flink 能够处理乱序数据和延迟数据。
-
分布式计算和容错机制:Flink 提供了分布式执行环境,能够在多节点集群中运行任务。支持 状态化计算 和 容错机制,通过将状态存储在分布式存储中(如 RocksDB、HDFS),保证在故障发生时可以从最新的状态中恢复。
-
丰富的 API:DataStream API:用于流数据的实时处理。DataSet API:用于批量数据处理(已被
Table API和SQL API所替代)。Table API 和 SQL API:高层次的声明式 API,支持 SQL 查询和表操作,适合处理结构化数据。CEP API:用于复杂事件处理(Complex Event Processing)。 -
跨语言支持:支持多种编程语言,包括 Java、Scala 和 Python,并通过
Flink SQL提供 SQL 查询支持。 -
扩展性强:Flink 可以无缝集成各种数据源和存储系统,如 Kafka、HDFS、ElasticSearch、Cassandra、MySQL 等。支持部署在多种环境中,包括本地、YARN、Kubernetes 和其他资源管理系统。
1.2 Flink 的核心组件
-
JobManager 和 TaskManager:JobManager:负责任务调度和资源分配。TaskManager:实际执行计算任务,并管理本地状态。
-
State 和 Checkpoint:State:用于存储任务的中间状态(如窗口计算的累积结果)。Checkpoint:定期将任务的状态存储到外部存储中,用于故障恢复。
-
Stream Processing(流处理):支持窗口操作(如滑动窗口、滚动窗口)。支持时间语义(事件时间、处理时间、摄取时间)。支持复杂事件处理(CEP)。
-
Batch Processing(批处理):通过将批处理建模为有界流,支持高效的批量数据计算。
1.3 Flink 的应用场景
-
实时数据分析:实时监控网站的用户行为。电商平台的实时推荐系统。网络安全的实时威胁检测。
-
流数据 ETL:将数据从 Kafka 中读取、清洗后写入到数据湖或数据库中。
-
事件驱动应用:基于传感器数据的实时报警。IoT(物联网)数据的实时处理。
-
复杂事件处理(CEP):检测金融交易中的欺诈行为。监控多事件模式(如连续发生的设备故障)。
-
批处理任务:数据预处理。数据聚合和离线分析。
1.4 Flink 与其他框架的对比
| 特点 | Flink | Spark | Storm |
|---|---|---|---|
| 处理模式 | 流为核心,批处理是流的特例 | 批为核心,流处理通过微批实现 | 原生流处理 |
| 事件时间支持 | 原生支持 | 需借助第三方库(Structured Streaming) | 不支持 |
| 状态管理 | 原生支持 | 基本支持(需要扩展) | 依赖外部存储 |
| 延迟 | 毫秒级延迟 | 毫秒至秒级 | 毫秒级 |
| 容错机制 | 支持 Checkpoint 和状态恢复 | 支持 | 需手动实现 |
2. Flink 的发展历史
Flink 的发展历史可以追溯到其最初的设计和实现,并且随着时间的推移,Flink 已经发展成为一个成熟的分布式数据处理平台。以下是 Flink 发展的主要里程碑:
1. 2010年: Flink 最早由 Data Artisans(后来的阿里巴巴 Flink 团队)开发。Flink 的前身是 Stratosphere 项目,这个项目在德国柏林的 Humboldt University(洪堡大学)由 Costin Raiciu 和 Kostas Tzoumas 等人发起。Stratosphere 项目是为了应对大规模数据处理,特别是在流式数据和批量数据的统一处理方面的挑战。目标: Stratosphere 的目标是通过批处理和流处理的统一架构来简化和优化大数据处理,避免在两者之间切换时的性能损失。
2. 2014年:Flink 作为开源项目发布,在 2014年,Stratosphere 项目更名为 Apache Flink,并开始成为 Apache 软件基金会的孵化项目(Incubation)。Apache Flink 的第一个稳定版本(Flink 0.6)发布,标志着它的首次公开发布和开源。当时 Flink 被设计成一个面向流式数据处理的框架,同时也可以支持批处理。在这个版本中,Flink 主要关注实时流处理和批处理的统一,同时也首次引入了 事件时间 和 窗口处理 的概念。
3. 2015年:成为 Apache 顶级项目:在 2015年,Flink 通过 Apache 软件基金会的孵化程序,成功晋升为 Apache 顶级项目(Top-Level Project,TLP)。这一年,Flink 的社区逐渐壮大,贡献者和用户开始增多。Apache Flink 的 0.9 版本发布,标志着 Flink 在性能、稳定性和易用性方面有了显著改进。在这一版本中,Flink 引入了 SQL 支持,这使得用户可以使用 SQL 来处理流数据,进一步降低了使用门槛。
4. 2016年:引入流批一体架构:2016年,Flink 引入了 流批一体 的概念,进一步加强了对批处理的支持。Flink 将批处理视为特殊的流处理,从而使得批处理和流处理可以在同一个引擎中无缝处理。这个版本还扩展了 状态管理 和 容错机制,使得 Flink 在大规模集群上更具可用性和稳定性。
5. 2017年:Flink 1.0 发布:Flink 1.0 在 2017年 发布,标志着 Flink 成为一个成熟且稳定的流处理框架。此版本引入了许多新特性,如 Flink SQL 支持、Flink ML(用于机器学习的库)、增强的 Checkpointing(检查点)和 容错性,使得 Flink 在处理大规模数据流和复杂事件处理(CEP)时具有强大的能力。Flink 在该版本还优化了 API,进一步提升了开发者体验。
6. 2018年:Flink 1.4 和 1.5 发布:Flink 1.4 引入了 Flink State Processor API,允许用户在流处理中更好地处理和管理状态。Flink 1.5 发布后,Flink 引入了更高效的 流批一体处理 和更强大的 容错机制。此版本增强了对多种数据源的支持,并优化了 流式 SQL 和 机器学习(Flink ML)的性能。
7. 2019年:Flink 1.8 和 1.9 发布:在 2019年,Flink 1.8 版本进一步增强了 流式 SQL 和 分布式部署 的能力,同时增加了对 Kubernetes 的原生支持。此版本的目标是提升开发者体验,优化流处理的性能,并增强 Flink 在大数据场景下的适用性。Flink 1.9 版本进一步完善了 Flink SQL 和 Flink CEP(复杂事件处理)的功能。
8. 2020年:Flink 1.10 和 1.11 发布:Flink 1.10 版本引入了 Flink Kubernetes Operator,使得 Flink 可以在 Kubernetes 环境下原生运行。同时,Flink 也增强了对 批处理作业的优化,提高了性能。Flink 1.11 版本带来了 Flink SQL 的重要增强,包括支持 Flink CDC(Change Data Capture),使得 Flink 在捕获数据变更方面具有更强的能力。
9. 2021年:Flink 1.13 和 1.14 发布:Flink 1.13 版本聚焦于 流处理性能 和 更高效的状态管理,并且进一步增强了对 Kubernetes 的支持。Flink 1.14 引入了对 Flink SQL 和 Flink CDC 的更大支持,进一步优化了 数据连接器,并增强了 用户体验。
10. 2022年及之后:Flink 继续以 流处理框架 的领军地位,逐渐扩大社区和生态系统,进一步支持 云原生 部署和更复杂的 流批一体计算。在 2022年,Flink 继续优化了 Kubernetes 支持,同时增强了 流式查询、Flink SQL 和 多版本支持 的功能,提升了在实时大数据处理中的应用能力。
Flink 发展过程中的关键亮点
- 批流一体架构:Flink 在流处理和批处理之间实现了统一,使得它能够高效处理各种类型的数据流,简化了处理流程。
- 状态管理和容错:Flink 强大的状态管理能力,使得它在需要精确状态处理的流应用中表现突出。Flink 的容错机制(如 Checkpoint 和 Savepoints)保证了系统高可用性。
- Flink SQL:Flink 在 SQL 的支持上不断优化,进一步降低了开发复杂度,使得非程序员也能够通过 SQL 进行实时流处理。
- Kubernetes 原生支持:随着云原生架构的流行,Flink 加强了与 Kubernetes 的集成,支持在云环境中灵活部署和管理流处理作业。
3. Flink 初步实践 WordCount
3.1. 有界数据流 WordCount
Maven 项目依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink_version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink_version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink_version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink_version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink_version}</version>
</dependency>WordCount 代码:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 定义文件路径(本地文件路径)
String filePath = "file://xxx"; // 使用 file:// 协议指定本地路径
Path path = new Path(filePath);
// 创建文件源
FileSource<String> fileSource = FileSource
.forRecordStreamFormat(new TextLineInputFormat(),path) // 读取文本文件
.build();
// 使用 FileSource 读取文件内容
DataStream<String> dataStream = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "FileSource");
// 处理数据:切分每一行
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>> () {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
// 聚合统计
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);
// 打印输出
sumDS.print();
// 执行 Flink 程序
env.execute("Flink FileSource Example");
}
}3.2 无界数据流 WordCount
数据源采用socket,可以使用netcat 向固定端口发送消息,mac 上可以使用brew 安装
brew install netcat
安装完成后,向固定端口持续发送消息
nc -lk 9999WordCount 代码:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountUnbounded {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.socketTextStream("localhost", 9999)
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
for (String word : line.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(0)
.sum(1)
.print();
env.execute("WordCountUnbounded");
}
}
程序启动后,在nc 代开的命令端,输入字符串如图:
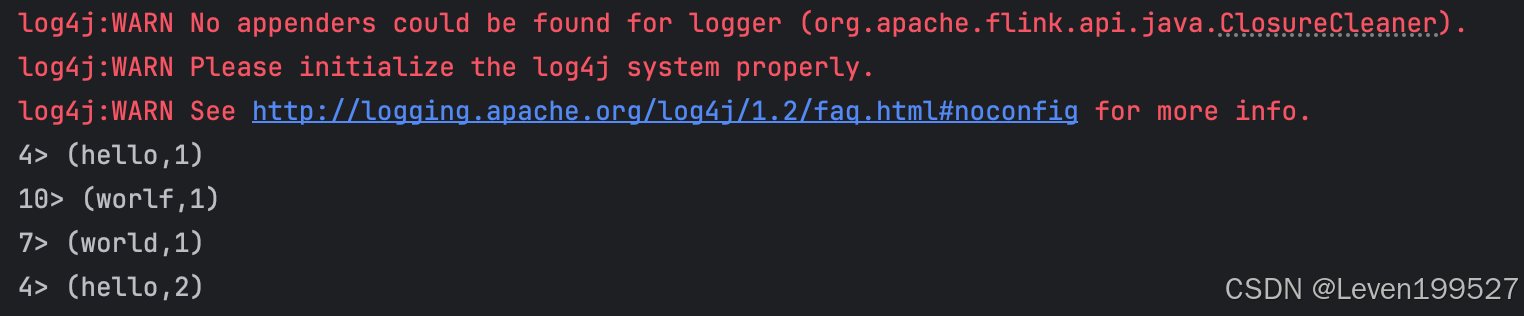
可以观察程序输出,发现实时的统计结果


















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











