








1、逻辑回归的前向传播步骤:
如果你有m个训练样本,为了完成前向传播步骤,需要对于每一个样本都进行预测,即对m个样本都计算出预测值,过程为:
- 对 第一个样本进行预测:
=
+ b;
= σ(
);
- 对第二个样本进行预测:
=
+ b;
= σ(
);
- 对第三个样本进行预测:
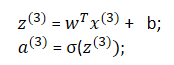
依次类推,一直要将m个样本的预测值都计算出来;
2、不使用明确的for循环的向量化的处理步骤:
定义一个训练输入矩阵X,X∈,即是一个
行 m 列的矩阵,改写成 Python.numpy 的形式(
,m);
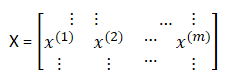
对于z来说,需要计算 ,
, .….., 一直到
,因此构建一个 1*m 的矩阵 Z = [
.…..
],而
=
+ b;因此可以写成[
.…..
] = [
+ b,
+ b…...
+ b];而对于numpy的命令是 Z = np.dot(w.T, x) + b,这里在Python中有一个巧妙的地方,这里b是一个实数,或者你可以说是一个1×1矩阵,只是一个普通的实数。但是当你将这个向量加上这个实数时,Python自动把这个实数b扩展成一个1xm的行向量。它在Python中被称作广播(brosdcasting).
对于同时计算 [.…..
] 的方法。可以堆积小写变量 a 间形成一个新的变量,可以将它定义为大写A,即: A = [
.…..
] = σ(z), 通过恰当地运用σ 一次性计算所有a。















 1401
1401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









