










原文:https://blog.csdn.net/weixin_41923961/article/details/80382409#commentsedit
损失函数
损失函数(Loss function)是用来估量你模型的预测值 f ( x ) f(x) f(x)与真实值 y y y 的不一致程度,它是一个非负实值函数,通常用 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))来表示。损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。模型的风险结构包括了风险项和正则项,通常如下所示:
θ ∗ = a r g m i n ∑ i = 1 N L ( y i , f ( x i ; θ ) ) + λ Φ ( θ ) θ^∗=argmin∑_{i=1}^NL(y_i,f(x_i;θ))+λ Φ(θ) θ∗=argmini=1∑NL(yi,f(xi;θ))+λΦ(θ)
其中,前面的均值函数表示的是经验风险函数, L L L代表的是损失函数,后面的 Φ Φ Φ 是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是 L 1 L_1 L1,也可以是 L 2 L_2 L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的 θ θ θ值。
常用损失函数
常见的损失误差有五种:
- 铰链损失(Hinge Loss):主要用于支持向量机(SVM) 中;
- 互熵损失 (Cross Entropy Loss,Softmax Loss ):用于Logistic 回归与Softmax 分类中;
- 平方损失(Square Loss):主要是最小二乘法(OLS)中;
- 指数损失(Exponential Loss) :主要用于Adaboost 集成学习算法中;
- 其他损失(如0-1损失,绝对值损失)
1.Hinge loss
Hinge的叫法来源于其损失函数的图形,为一个折线,通用函数方式为:
L
(
m
i
)
=
m
a
x
(
0
,
1
−
m
i
(
w
)
)
L(m_i) = max(0,1-m_i(w))
L(mi)=max(0,1−mi(w))
Hinge可以解 间距最大化 问题,带有代表性的就是svm,最初的svm优化函数如下:
a
r
g
m
i
n
w
,
ζ
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
ζ
i
s
t
.
∀
y
i
w
T
x
i
≥
1
−
ζ
i
ζ
i
≥
0
\underset{w,\zeta}{argmin} \frac{1}{2}||w||^2+ C\sum_i \zeta_i \\ st.\quad \forall y_iw^Tx_i \geq 1- \zeta_i \\ \zeta_i \geq 0
w,ζargmin21∣∣w∣∣2+Ci∑ζist.∀yiwTxi≥1−ζiζi≥0
将约束项进行变形则为:
ζ
i
≥
1
−
y
i
w
T
x
i
\zeta_i \geq 1-y_iw^Tx_i
ζi≥1−yiwTxi
则可以将损失函数进一步写为:
J
(
w
)
=
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
m
a
x
(
0
,
1
−
y
i
w
T
x
i
)
J(w)=\frac{1}{2}||w||^2 + C\sum_i max(0,1-y_iw^Tx_i)
J(w)=21∣∣w∣∣2+Ci∑max(0,1−yiwTxi)
=
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
m
a
x
(
0
,
1
−
m
i
(
w
)
)
= \frac{1}{2}||w||^2 + C\sum_i max(0,1-m_i(w))
=21∣∣w∣∣2+Ci∑max(0,1−mi(w))
=
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
L
L
i
n
g
e
(
m
i
)
= \frac{1}{2}||w||^2 + C\sum_i L_{Linge}(m_i)
=21∣∣w∣∣2+Ci∑LLinge(mi)
因此svm的损失函数可以看成L2-Norm和Hinge损失误差之和.
2.Softmax Loss
有些人可能觉得逻辑回归的损失函数就是平方损失,其实并不是。平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到,而逻辑回归得到的并不是平方损失。在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数(即 m a x F ( y , f ( x ) ) → m i n − F ( y , f ( x ) ) ) maxF(y,f(x))→min−F(y,f(x))) maxF(y,f(x))→min−F(y,f(x)))。从损失函数的视角来看,它就成了Softmax 损失函数了。
l o g log log损失函数的标准形式:
L ( Y , P ( Y ∣ X ) ) = − l o g P ( Y ∣ X ) L(Y,P(Y|X))=−logP(Y|X) L(Y,P(Y∣X))=−logP(Y∣X)
刚刚说到,取对数是为了方便计算极大似然估计,因为在MLE中,直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数
L
(
Y
,
P
(
Y
∣
X
)
)
L(Y,P(Y|X))
L(Y,P(Y∣X))表达的是样本X在分类Y的情况下,使概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为
l
o
g
log
log函数是单调递增的,所以
l
o
g
P
(
Y
∣
X
)
logP(Y|X)
logP(Y∣X)也会达到最大值,因此在前面加上负号之后,最大化
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)就等价于最小化LL 了。
逻辑回归的
P
(
Y
=
y
∣
x
)
P(Y=y|x)
P(Y=y∣x)表达式如下(为了将类别标签
y
统
一
为
1
和
0
y统一为1和0
y统一为1和0,下面将表达式分开表示):
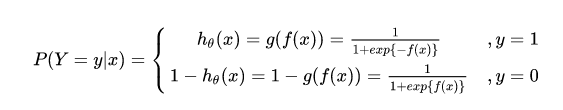
将它带入到上式,通过推导可以得到
l
o
g
i
s
t
i
c
logistic
logistic的损失函数表达式,如下:
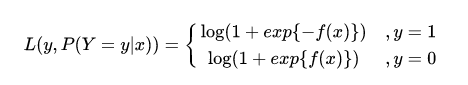
逻辑回归最后得到的目标式子如下:
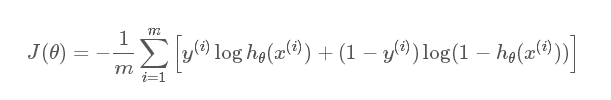
上面是针对二分类而言的。这里需要解释一下:之所以有人认为逻辑回归是平方损失,是因为在使用梯度下降来求最优解的时候,它的迭代式子与平方损失求导后的式子非常相似,从而给人一种直观上的错觉。
3 Squared Loss
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(中心极限定理),最后通过极大似然估计(MLE)可以推导出最小二乘式子。最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。
平方损失(Square loss)的标准形式如下:
L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 L(Y,f(X))=(Y−f(X))^2 L(Y,f(X))=(Y−f(X))2
当样本个数为n时,此时的损失函数为:
L
(
Y
,
f
(
X
)
)
=
∑
i
=
1
n
(
Y
−
f
(
X
)
)
2
L(Y,f(X))=∑_{i=1}^n(Y−f(X))^2
L(Y,f(X))=i=1∑n(Y−f(X))2
Y
−
f
(
X
)
Y−f(X)
Y−f(X)表示残差,整个式子表示的是残差平方和 ,我们的目标就是最小化这个目标函数值,即最小化残差的平方和。
在实际应用中,我们使用均方差(MSE)作为一项衡量指标,公式如下:
M S E = 1 n ∑ i = 1 n ( Y i ~ − Y i ) 2 MSE=\frac{1}{n}∑_{i=1}^n(\tilde{Y_i}−Y_i)^2 MSE=n1i=1∑n(Yi~−Yi)2
4.Exponentially Loss
损失函数的标准形式是:
L
(
y
,
f
(
x
)
)
=
e
x
p
[
−
y
f
(
x
]
L(y,f(x))=exp[−yf(x]
L(y,f(x))=exp[−yf(x]

关于Adaboost的详细推导介绍,可以参考Wikipedia:AdaBoost或者李航《统计学习方法》P145。
5 其他损失
0-1 损失函数
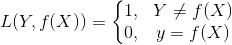
绝对值损失函数

上述几种损失函数比较的可视化图像如下:

总结
机器学习作为一种优化方法,学习目标就是找到优化的目标函数——损失函数和正则项的组合;有了目标函数的“正确的打开方式”,才能通过合适的机器学习算法求解优化。
参考资料:
[1] https://blog.csdn.net/google19890102/article/details/50522945
[2] https://www.cnblogs.com/hejunlin1992/p/8158933.html
[3] https://blog.csdn.net/u014755493/article/details/71402991
[4] https://webcache.googleusercontent.com/search?q=cache:http://kubicode.me/2016/04/11/Machine%20Learning/Say-About-Loss-Function/&gws_rd=cr















 5310
5310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









