





 本文介绍了Surprise推荐系统中预测算法的使用,包括内置算法的来源和预测方法。讨论了基线估计配置,如SGD和ALS,并详细说明了相关参数。此外,还提到了相似度度量的配置选项,如Pearson基线。
本文介绍了Surprise推荐系统中预测算法的使用,包括内置算法的来源和预测方法。讨论了基线估计配置,如SGD和ALS,并详细说明了相关参数。此外,还提到了相似度度量的配置选项,如Pearson基线。
预测算法的使用
Surprise提供很多内置算法。所有算法都来源于AlgoBase这个基础类,这其中包括一些关键方法(例如predict,fit和test)可供使用的预测算法的种类与细节可以在prediction_algorithms文档中查阅。
每个算法都是Surprise全局命名空间的一部分,因此您只需要从Surprise包中导入它们的名称,例如:
from surprise import KNNBasic
algo = KNNBasic()
一些算法可能使用baseline estimates,一些算法可能使用similarity measure。我们在这里回顾 baseline与 similarities的计算方式。
Baselines estimates configuration:
注意:
本节仅适用于那些最小化以下正则化平方误差的算法(或similarity measures):
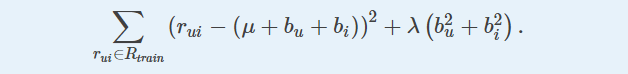
对于其他使用baseline目标函数的算法(例如SVD算法),配置是完全不同的,请查阅它们自己的文档进行了解。
首先,如果你不想了解baseline是如何计算的,默认的参数完全可以供您直接使用。如果您想深入了解,那请继续阅读。
你可能想阅读2.1节的Kor10来对baseline estimates有更深的了解。
我们可以通过两种不同的方式计算baseline:
1. Stochastic Gradient Descent (SGD)。
2. Alternating Least Squares (ALS)。
您可以使用在创建算法时使用参数bsl_options来设置baseline的计算方式,此参数由一个字典表示,其键method确定要使用的方法,可允许接受的值为als(默认)和sgd。根据你所选择的值,可以进一步设置其他参数。
对于ALS:
reg_i:物品的正则化参数,对应Kor10中的参数λ2 ,默认值为10。
reg_u:用户的正则化参数,对应Kor10中的参数λ3,默认值为15 。
n_epochs:ALS程序迭代的次数,默认值为10,注意Kor10所描述的是单次ALS的过程。
对于SGD:
reg:代价函数的正则化项,对应Kor10中的λ1与 λ5,默认值为0.02。
learning_rate:SGD的学习率,对应Kor10中的γ ,默认值0.005。
n_epochs:SGD的迭代次数,默认值为20。
注意:对于ALD与SGD,用户和物品的偏置(bu和bi)初始化为都为0。
ALS:
print('Using ALS')
bsl_options = {'method': 'als',
'n_epochs': 5,
'reg_u': 12,
'reg_i': 5
}
algo = BaselineOnly(bsl_options=bsl_options)
SGD:
print('Using SGD')
bsl_options = {'method': 'sgd',
'learning_rate': .00005,
}
algo = BaselineOnly(bsl_options=bsl_options)
Similarity measure configuration:
许多算法使用相似度来估计评分的算法,配置方法和baseline rating类似,在调用算法时,只需传递sim_options参数进行配置,这个参数的形式必须是字典,介绍关键的参数如下:
name:相似度度量方法名称, 这些方法定义在similarities中,默认是MSD。
user_based: 用户或者物品间相似度的度量。默认为True(基于用户)。
min_support:(没搞懂,待补充)
shrinkage:此参数仅在使用pearson_baseline相似度时设置,默认100。
举例:
sim_options = {'name': 'cosine',
'user_based': False # compute similarities between items
}
algo = KNNBasic(sim_options=sim_options)
sim_options = {'name': 'pearson_baseline',
'shrinkage': 0 # no shrinkage
}
algo = KNNBasic(sim_options=sim_options)
详情请参考similarities模型。

















 3346
3346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









