









0介绍
从这里开始学习:https://surprise.readthedocs.io/en/stable/prediction_algorithms_package.html
surprise,和sklearn类似,不过是surprise主要用于推荐
1预测算法
1.0AlgoBase基类
Surprise提供了一系列内置算法。所有预测算法都源自AlgoBase基类,其中实现(implement)了一些关键方法(e.g. predict, fit and test)。
surprise.prediction_algorithms.algo_base 模块定义了每个预测算法都必须从中继承的基类AlgoBase。
class surprise.prediction_algorithms.algo_base.AlgoBase(**kwargs)
抽象类,其中定义了预测算法的基本行为。
关键参数:
- baseline_options (dict, optional)
- 如果算法需要计算基线估计值(baselines estimates),则baseline_options参数用于配置计算方式。
- 有关使用情况,请参阅1.0.1基线估计配置。
1.0.1Baselines estimates configuration(基线估计值配置)
本节仅适用于尝试最小化以下正则化平方误差(或等效误差)的算法(或相似性度量):
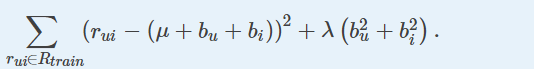
对于在另一个目标函数(例如SVD算法)中使用基线的算法,基线配置是不同的,并且特定于每个算法。请参考他们自己的文档。
Baselines(基线)可以通过两种不同的方式进行估计
您可以使用在创建算法时传递的bsl_options参数配置计算基线的方式。此参数是一个字典,其中键“method”表示要使用的方法。接受的值为“als”(默认值)和“sgd”。根据其值,可以设置其他选项。
ASL:
- “reg_i”:项(items)的正则化参数。对应于[Koren:2010]中的λ2。默认值为10。
- “reg_u”:用户的正则化参数。对应于[Koren:2010]中的λ3。默认值为15。
- ‘n_epochs’:ALS过程的迭代次数。默认值为10。注意,在[Koren:2010]中,描述的是一个单一的迭代过程。
- 在机器学习中,ALS指使用交替最小二乘法求解的一个协同过滤推荐算法
print('Using ALS')
bsl_options = {'method': 'als',
'n_epochs': 5,
'reg_u': 12,
'reg_i': 5
}
algo = BaselineOnly(bsl_options=bsl_options)
SGD:
- “reg”:优化成本函数的正则化参数,对应于[Koren:2010]中的λ1。默认值为0.02。
- “learning_rate”:SGD的学习率,对应于[Koren:2010]中的γ。默认值为0.005。
- ‘n_epochs’:SGD过程的迭代次数。默认值为20。
print('Using SGD')
bsl_options = {'method': 'sgd',
'learning_rate': .00005,
}
algo = BaselineOnly(bsl_options=bsl_options)
注意:对于这两个过程(ALS和SGD),用户和项目偏差(bu和bi)初始化为零。
Note that some similarity measures(相似性度量) may use baselines, such as the pearson_baseline similarity.
具体看here
1.0.2Similarity measure configuration(相似性度量配置)
许多算法使用相似性度量来估计评分。配置它们的方式与baselines ratings(基线评级)的方式类似:您只需在创建算法时传递sim_options参数。此参数是具有以下(所有可选)键的字典:
- “name”:相似性模块中定义的要使用的相似性的名称。默认值为“MSD”。(MSD——Mean Squared Difference)
- “user_based”:将计算用户之间还是项目之间的相似性。这对预测算法的性能有很大的影响。默认值为True(即计算用户之间的相似性)。
- “min_support”:相似度不为零的 最小公共项(items)数(当“user_based”为“True”时)或最小公共用户数(当“user_based”为“False”)。简单地说,如果|Iuv|<min_support ,那么sim(u,v)=0(即这两个用户之间的相似度为0)。这同样适用于物品。
- “shrinkage”:要应用的收缩参数(仅与pearson_baseline相似性相关)。默认值为100。
sim_options = {'name': 'cosine',
'user_based': False # compute similarities between items
}
algo = KNNBasic(sim_options=sim_options)
相似度度量方法有cosine、msd、pearson、pearson_baseline等
1.0.3 algobase的方法
1compute_baselines()
2compute_similarities()
3default_prediction()
4fit(trainset)
在给定的训练集上训练算法。
此方法由每个派生类调用,作为训练算法的第一个基本步骤。它基本上只是初始化一些内部结构并设置self.trainset属性。
- 参数:trainset(trainset)–一个由folds方法返回的训练集。
- 返回:self
5get_neighbors(iid, k)
6predict(uid, iid, r_ui=None, clip=True, verbose=False)
计算给定用户和项目的评级预测。
predict方法将原始ID转换为内部ID(What are raw and inner ids?),然后调用在每个派生类中定义的estimate方法。如果无法进行预测(例如,因为用户 和/或 项目未知),则根据默认值设置预测。
参数:
- uid–用户id(raw)。
- iid–项目的id(raw)。
- r_ui(float)-真实评级。可选,默认为无。
- clip(bool)–是否将估算值剪切到评级量表中。例如,如果rui为5.5,而评级等级为[1,5],则rui设置为5。如果rui<1,情况也是如此。默认值为True。
- verbose (bool)–是否打印预测的详细信息。默认值为False。
return:
一个预测对象,包含:
- 用户id uid(raw)。
- 项目id iid(raw)。
- 真实评级r_ui(rui)。
- 估计评级(rui)。
Raw ID是rating file 或 a pandas DataFrame中定义的ID。它们可以是字符串或数字。但是请注意,如果评级是从标准场景的文件中读取的,则它们表示为字符串。了解您是否正在使用predict()或其他接受Raw ID作为参数的方法非常重要。
在trainset创建时,每个raw id映射到一个称为inner id的唯一整数,该整数更适合surprise操作。raw ID和inner ID之间的转换可以使用trainset的**to_inner_uid()、to_inner_iid()、to_raw_uid()和to_raw_iid()**方法完成。
7test(testset, verbose=False)
1.00The predictions module
The surprise.prediction_algorithms.predictions module defines the Prediction named tuple and the PredictionImpossible exception.
here
1.1Basic Algorithms
1.1.1random_pred.NormalPredictor
基于假设为正态的训练集分布预测随机评分的算法。
class surprise.prediction_algorithms.random_pred.NormalPredictor
Bases: surprise.prediction_algorithms.algo_base.AlgoBase
预测rui由正态分布N(μ^ ,σ^ 2)生成,其中μ^ 和σ^ 通过使用最大似然估计的训练数据进行估计:
1.1.2baseline_on1y.BaselineOnly
为给定用户和项目预测基线估计值的算法。
class surprise.prediction_algorithms.baseline_only.BaselineOnly(bsl_options={}, verbose=True)
Bases: surprise.prediction_algorithms.algo_base.AlgoBase
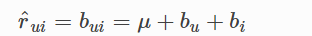
如果用户U是未知的,则bu假设为0,item同理。
1.2 knns
1.2.1knns.KNNBasic
一种基本的协同过滤算法。
class surprise.prediction_algorithms.knns.KNNBasic(k=40, min_k=1, sim_options={}, verbose=True, **kwargs)
Bases: surprise.prediction_algorithms.knns.SymmetricAlgo

参数:
- k(int)–聚合时要考虑的(最大)邻居数。默认值为40。
- min_k(int)–聚合时要考虑的最小邻居数。如果没有足够的邻居,则将预测设置为所有评级的全局平均值。默认值为1。
- sim_options(dict)–相似性度量的选项字典。
verbose(bool)–是否打印偏差估计、相似性等跟踪消息。默认值为True。
注意:
对于这些算法(knns)中的每一种,聚合以计算估计的实际邻居数必然小于或等于k。首先,可能没有足够的邻居,其次,集合Nki(u)和Nku(i)只包含相似性度量为正的邻居。将负相关的用户(或项目)的评分汇总在一起是没有意义的。对于给定的预测,可以在预测的详细信息字典的“actual_k”字段中检索邻居的实际数量。
1.2.2knns.KNNlwithMeans
一种基本的协同过滤算法,考虑到每个用户的平均评分。
class surprise.prediction_algorithms.knns.KNNWithMeans(k=40, min_k=1, sim_options={}, verbose=True, **kwargs)
Bases: surprise.prediction_algorithms.knns.SymmetricAlgo
考虑到每个用户的平均评分,主要是考虑到用户个人的特点,会给所有item打高分等情况。
1.2.3knns.KNNWithZScore
一种基本的协同过滤算法,它考虑了每个用户的z分数标准化。
class surprise.prediction_algorithms.knns.KNNWithZScore(k=40, min_k=1, sim_options={}, verbose=True, **kwargs)
Bases: surprise.prediction_algorithms.knns.SymmetricAlgo
1.2.4knns.KNNBaseline
一种基本的协同过滤算法,考虑了基线评分。
class surprise.prediction_algorithms.knns.KNNBaseline(k=40, min_k=1, sim_options={}, bsl_options={}, verbose=True, **kwargs)
Bases: surprise.prediction_algorithms.knns.SymmetricAlgo
1.3matrix_factorization
1.3.1matrix_factorization.SVD
著名的SVD算法,由Simon Funk在Netflix大奖期间推广。当不使用基线时,这相当于概率矩阵分解。
class surprise.prediction_algorithms.matrix_factorization.SVD
Bases: surprise.prediction_algorithms.algo_base.AlgoBase
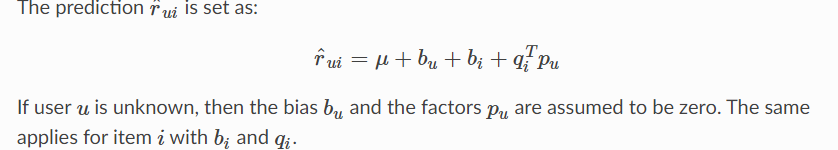
参数:
-
n_factors :因子(factors)的数量。默认值为20。
-
n_epochs :SGD(随机梯度下降)过程的迭代次数。默认值为20。
-
biased (bool) – Whether to use baselines (or biases). Default is True.
-
init_mean:因子向量初始化的正态分布平均值。默认值为0。
-
init_std_dev:因子向量初始化正态分布的标准偏差。默认值为0.1。
-
lr_all:所有参数的学习率。默认值为0.007。
-
reg_all:所有参数的正则化项。默认值为0.02。
-
lr_bu:bu的学习率。如果设置,则优先于lr_all。默认值为“无”。
-
lr_bi:bi的学习率。如果设置,则优先于lr_all。默认值为“无”。
-
lr_pu:pu的学习率。如果设置,则优先于lr_all。默认值为“无”。
-
lr_qi:qi的学习率。如果设置,则优先于lr_all。默认值为“无”。
-
reg_bu:bu的正规化术语。如果设置,则优先于reg_all。默认值为“无”。
-
reg_bi:bi的正则化术语。如果设置,则优先于reg_all。默认值为“无”。
-
reg_pu:pu的正则化术语。如果设置,则优先于reg_all。默认值为“无”。
-
reg_qi:qi的规范化术语。如果设置,则优先于reg_all。默认值为“无”。
-
random_state(int、numpy的RandomState实例或None):确定将用于初始化的RNG。如果为int,则随机_状态将用作新RNG的种子。这对于在多次调用fit()时获得相同的初始化非常有用。如果是RandomState实例,则该实例将用作RNG。如果没有,则使用来自numpy的当前RNG。默认值为“无”。
-
verbose:如果为True,则打印当前历元。默认值为False。
pu
The user factors (only exists if fit() has been called)
Type: numpy array of size (n_users, n_factors)
qi
The item factors (only exists if fit() has been called)
Type: numpy array of size (n_items, n_factors)
bu
The user biases (only exists if fit() has been called)
Type: numpy array of size (n_users)
bi
The item biases(偏差) (only exists if fit() has been called)
Type: numpy array of size (n_items)
1.3.2matrix_factorization.SVDpp
SVD++算法,它是SVD的一个扩展,考虑了隐式评级。
clas ssurprise.prediction_algorithms.matrix_factorization.SVDpp
Bases: surprise.prediction_algorithms.algo_base.AlgoBase
参数(大部分同上):
- lr_yj:yj的学习率。如果设置,则优先于lr_all。默认值为“无”。
-
- reg_yj:yj的正则化术语。如果设置,则优先于reg_all。默认值为“无”。
yj
The (implicit) item factors (only exists if fit() has been called)
Type: numpy array of size (n_items, n_factors)
- reg_yj:yj的正则化术语。如果设置,则优先于reg_all。默认值为“无”。
1.3.3matrix_factorization.NMF
一种基于非负矩阵分解的协同过滤算法。
class surprise.prediction_algorithms.matrix_factorization.NMF
Bases: surprise.prediction_algorithms.algo_base.AlgoBase
1.4slope_one.SlopeOne
一种简单但精确的协同过滤算法。
1.5co_clustering.CoClustering
一种基于协同聚类的协同过滤算法。
2model_selection
2.1交叉验证迭代器Cross validation iterators
Surprise 提供了各种工具来运行交叉验证过程和搜索预测算法的最佳参数。这里介绍的工具都是从优秀的scikit学习库中获得大量灵感的。
该模块还包含将数据集拆分为训练集和测试集的功能:
train_test_split:Split a dataset into trainset and testset.
分割数据集以及训练和测试
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset, testset = train_test_split(data, test_size=.25) #随机抽样选出训练集和测试集,这里选取了25%作为测试集
algo = SVD() #使用SVD算法
algo.fit(trainset) #做训练
predictions = algo.test(testset) #做测试
accuracy.rmse(predictions) #计算RMSE
显然,我们也可以简单地将我们的算法作用于整个数据集,而不是进行交叉验证。这可以通过使用build_full_trainset()方法建立trainset对象来完成 :
from surprise import KNNBasic
from surprise import Dataset
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset = data.build_full_trainset() #纠正/取出训练集
algo = KNNBasic() #建立算法并训练
algo.fit(trainset)
2.1.1 KFold
是一个基本的交叉验证迭代器。
class surprise.model_selection.split.KFold(n_splits=5, random_state=None, shuffle=True)
参数:
- n_splits(int)–折叠的数量。
- random_state(int、numpy的RandomState实例或None)–确定将用于确定folds的RNG。如果为int,则random_state将用作新RNG的种子。这对于通过多次调用split()获得相同的拆分非常有用。如果是RandomState实例,则该实例将用作RNG。如果没有,则使用来自numpy的当前RNG。random_state仅在随机播放为真时使用。默认值为“无”。
- shuffle(bool)–是否洗牌split()方法的数据参数中的评级。洗牌没有到位。默认值为True。
split(data)
用于迭代训练集集和测试集的生成器函数。
参数:数据(Dataset)–包含将被分为训练集和测试集的额定值的数据。
生成:元组(训练集、测试集)
使用
examples/use_cross_validation_iterators.py
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import KFold
# Load the movielens-100k dataset
data = Dataset.load_builtin('ml-100k')
# define a cross-validation iterator
kf = KFold(n_splits=3)
algo = SVD()
for trainset, testset in kf.split(data):
# train and test algorithm.
algo.fit(trainset)
predictions = algo.test(testset)
# Compute and print Root Mean Squared Error
accuracy.rmse(predictions, verbose=True)
Result could be, e.g.:
RMSE: 0.9374
RMSE: 0.9476
RMSE: 0.9478
2.1.2 RepeatedKFold
RepeatedKFold:重复KFold交叉验证程序。
2.1.3ShuffleSplit
ShuffleSplit是一个带有随机训练集和测试集的基本交叉验证迭代器。
2.1.4LeaveOneOut
LeaveOneOut交叉验证迭代器,其中每个用户在测试集中只有一个评级。
2.1.5 PredefinedKFold
PredefinedKFold 一个交叉验证迭代器,用于在使用load_from_方法加载数据集时调用。
3 similarities module
3.1 cosine
计算所有用户对(或项目)之间的余弦相似性。
surprise.similarities.cosine()

3.2 msd
计算所有对用户(或项目)之间的均方差相似度。
surprise.similarities.msd()

3.3pearson
计算所有用户对(或项目)之间的pearson相关系数。
surprise.similarities.pearson()

3.4 pearson_baseline
计算所有用户(或项目)对之间的(收缩的)pearson相关系数,使用基线作为中心,而不是平均值。
surprise.similarities.pearson_baseline()
4accuracy module
accuracy模块提供了计算一组预测的精度指标的工具。
可用的精度指标:

5dataset module
class surprise.dataset.Dataset(reader)
dataset模块定义用于管理数据集的dataset类和其他子类。
用户可以同时使用内置数据集和用户定义数据集。目前,有三个内置数据集可用:
The movielens-100k dataset.
The movielens-1m dataset.
The Jester dataset 2.
可以使用Dataset.load_builtin()方法加载(或下载(如果尚未加载))所有内置数据集。
总结:
5.1 classmethod load_builtin(name=u’ml-100k’, prompt=True)
加载内置数据集。
如果尚未加载数据集,则将下载并保存该数据集。
默认情况下,surprise下载的数据集将保存在“~/.surprise_data”目录中。这也是存储转储文件的地方。您可以通过设置“SURPRISE_DATA_FOLDER”环境变量来更改默认目录(here)
您必须使用split方法(model_selection模块)拆分数据集。
参数:
name(字符串)–要加载的内置数据集的名称。可接受的值为“ml-100k”、“ml-1m”和“jester”。默认值为“ml-100k”。
prompt(bool)–如果数据集不在磁盘上,则在下载前进行提示。默认值为True。
返回:
数据集对象。
如果名称参数不正确,ValueError错误。
5.2 classmethod load_from_df(df, reader)
5.3 classmethod load_from_file(file_path, reader)
5.4 classmethod load_from_folds(folds_files, reader)
5.5
class surprise.dataset.DatasetAutoFolds(ratings_file=None, reader=None, df=None)
6Trainset class
trainset包含构成训练集的所有有用数据。
class surprise.Trainset(ur, ir, n_users, n_items, n_ratings, rating_scale, raw2inner_id_users, raw2inner_id_items)
每个预测算法的fit()方法都使用它。您不应该尝试自己构建这样的对象,而应该使用Dataset.folds() method or the DatasetAutoFolds.build_full_trainset() method
trainset与dataset不同。可以将数据集视为原始数据,将训练集视为定义了有用方法的更高级别的数据。
交叉验证也可以由多个数据集组成。
here是trainset的属性和方法
属性:

方法:




参考
https://blog.csdn.net/yuxeaotao/article/details/79851576
















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











