







Urban Computing: Concepts, Methodologies, and Applications
YU ZHENG, Microsoft Research
LICIA CAPRA, University College London
OURI WOLFSON, University of Illinois at Chicago
HAI YANG, Hong Kong University of Science and Technology
DOI: http://dx.doi.org/10.1145/2629592
城市化的快速发展使许多人的生活现代化,但也产生了一些大问题,如交通拥堵、能源消耗和污染。城市计算的目标是通过使用城市中产生的数据来解决这些问题(例如,交通流量、人员流动和地理数据)。城市计算将城市感知、数据管理、数据分析和服务提供连接到一个反复出现的过程中,以不引人注意地持续改善人们的生活、城市运营系统和环境。城市计算是一个跨学科的领域,计算机科学与传统的城市相关领域,如交通、土木工程、环境、经济、生态学和城市空间的社会学。本文首先介绍了城市计算的概念,从计算机科学的角度讨论了城市计算的总体框架和主要挑战。其次,我们将城市计算的应用分为7类,包括城市规划、交通、环境、能源、社会、经济和公共安全,并在每一类中呈现出代表性的场景。第三,将城市计算所需的典型技术归纳为城市感知、城市数据管理、跨异构数据的知识融合和城市数据可视化等四个方面。最后,我们展望了城市计算的未来,并提出了一些在社区中缺失的研究课题。
1. INTRODUCTION
城市化的快速发展带来了许多大城市,使许多人的生活现代化,但也带来了巨大的挑战,如空气污染、能源消耗增加和交通拥堵。几年前,考虑到城市的复杂和动态环境,应对这些挑战几乎是不可能的。当前,传感技术和大规模计算基础设施产生了城市空间的各种大数据(如人类移动、空气质量、交通模式、地理数据等)。大数据意味着对一个城市的丰富了解,如果使用得当,可以帮助解决这些挑战。例如,我们可以通过分析城市范围内的交通数据来发现城市道路网络的潜在问题。这一发现有助于更好地制定未来的城市规划[Zheng et al. 2011b]。另一个例子是通过研究空气质量与其他数据源,如交通流量和兴趣点(POIs)之间的相关性,挖掘城市空气污染的根本原因[Zheng et al. 2013b]。
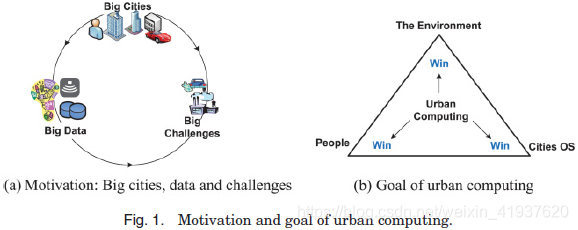
出于建设更多的智能城市的机会,我们想出了一个城市的视觉计算,旨在发挥知识的力量,从大型和异构城市空间和应用这个强大的信息收集的数据来解决我们的城市今天面临重大问题(郑et al . 2012 c, 2013)。总之,我们能够利用大数据来应对大城市的大挑战,如图1(a)所示。
为了解决这些问题,我们正式创造城市计算在这篇文章,并介绍其一般框架,关键的研究问题,方法和应用。本文将帮助社区更好地理解和探索这一新兴领域,从而产生高质量的研究结果和真正的系统,最终导致更绿色、更智慧的城市。此外,城市计算是一个多学科研究领域,其中计算机科学与传统的城市相关领域,如土木工程、交通运输、经济学、能源工程、环境科学、生态学和社会学。本文主要从计算机科学的角度来探讨上述问题。
本文的其余部分组织如下。在第2节中,我们介绍了城市计算的概念,提出了一个一般框架和框架中每一步的关键挑战。对城市计算中常用的数据集也进行了讨论。在第3节中,我们将城市计算的应用分为7组,并在每组中给出一些有代表性的场景。在第4节中,我们将介绍通常在城市计算场景中使用的四种方法。第五部分对全文进行了总结,并指出了未来研究的方向。
2. FRAMEWORK OF URBAN COMPUTING
2.1. Definition
城市计算是一个获取、整合和分析城市空间中不同来源(如传感器、设备、车辆、建筑和人类)产生的大数据和异构数据的过程,以解决城市面临的主要问题(如空气污染、能源消耗增加和交通拥堵)。城市计算将无干扰、无所不在的传感技术、先进的数据管理和分析模型以及新颖的可视化方法相结合,创造出改善城市环境、人类生活质量和城市运营系统的三赢解决方案,如图1(b)所示。城市计算还帮助我们理解城市现象的本质,甚至预测城市的未来。城市计算是在城市空间的背景下,将计算科学与交通、土木工程、经济、生态学、社会学等传统领域相融合的跨学科领域。
2.2. General Framework
图2描述了城市计算的总体框架,它由四个层次组成:城市感知、城市数据管理、数据分析和服务提供。以城市异常检测为例[Pan et al. 2013],我们简要介绍了该框架的运行情况。
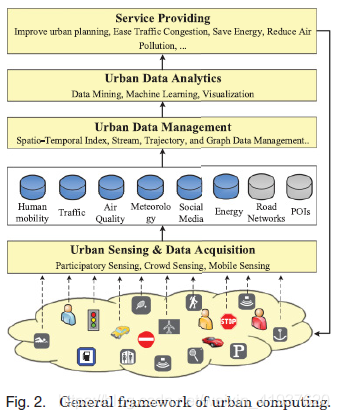
在城市感知步骤中,我们不断地利用GPS传感器或手机信号来探测人们的移动性(如城市道路网络中的路由行为)。我们还不断收集人们在互联网上发布的社交媒体。在数据管理步骤中,人类移动和社交媒体数据通过索引结构很好地组织起来,同时包含时空信息和文本,以支持高效的数据分析。在数据分析步骤中,一旦出现异常,我们就能够识别出人们移动的位置,这些位置与最初的模式有显著不同。同时,我们可以从社交媒体中挖掘出与地点和时间跨度相关的代表性词汇来描述异常。在提供服务的步骤中,异常的位置和描述将被发送给附近的司机,以便他们选择绕道。此外,这些信息将被发送到交通管理局,用于分散交通和诊断异常。该系统继续循环,以即时且不引人注意的方式检测城市异常,帮助改善人们的驾驶体验,减少交通拥堵。
与基于单个(模态)数据/单任务框架(即从网页中检索信息)的其他系统(如网络搜索引擎)相比,城市计算拥有一个多(模态)数据/多任务框架。城市计算的任务包括改善城市规划、缓解交通拥堵、减少能源消耗和减少空再污染。此外,我们通常需要在单个任务中利用多种数据源。例如,上述异常检测使用了人类移动数据、道路网络和社交媒体。通过将不同的数据源与来自框架不同层的不同数据采集、管理和分析技术结合起来,可以完成不同的任务。
2.3. Key Challenges
城市计算的目标和框架导致了三个主要的挑战:
1. 城市遥感和数据采集:第一种是数据采集技术,它可以不引人注目地持续收集城市范围内的数据。监测一个路段上的交通流量很容易,但持续探测全市交通是一个挑战,因为我们并没有在每个路段上安装传感器。建设新的传感基础设施可以实现这一目标,但反过来会加重城市的负担。如何智能地利用城市空间中已有的东西还有待探索。人类作为传感器是一个新概念,可能有助于解决这一挑战。例如,当用户在社交网站上发布社交媒体时,他们实际上是在帮助我们了解他们周围发生的事件。当许多人在道路网络上开车时,他们的GPS轨迹可能会反映出交通模式和异常情况。然而,就像硬币有两面一样,尽管人类传感器具有灵活性和智能,人类作为传感器也带来了三个挑战(我们将在4.1节中讨论更多这方面的问题):
- 能源消耗和隐私:对于参与式感知应用来说,这是一个不容忽视的问题。在参与式感知应用中,用户主动贡献他们的数据(通常使用智能手机),以节省智能手机的能源,并在感知过程中保护他们的隐私。在能源、隐私和共享数据的效用之间存在一种权衡[Xue等人2013]。
- 松散控制和非均匀分布传感器:我们可以把传统的传感器放在任何我们喜欢的地方,并配置这些传感器以特定的频率发送传感读数。然而,我们无法控制那些随时随地发送信息或有时不共享数据的人。在某些地方,我们甚至可能在某些时刻没有人(例如,可能没有传感器数据),这不可避免地导致数据丢失和稀疏性问题。另一方面,用户在某些位置(有很多人)生成的内容可能过多,甚至是多余的,为感知、通信和存储增加了不必要的工作量。另外,我们可以获得的数据总是部分用户的数据样本,因为不是每个人都共享数据。样本数据的分布可能会偏离整个数据集的分布,这取决于人的流动。
- 非结构化、隐式和噪声数据:传统传感器生成的数据结构良好、清晰、清晰、易于理解。然而,用户提供的数据通常是一种自由的格式,如文本和图像,或者不能像使用传统传感器那样明确地引导我们达到最终目标。
有时,来自人类传感器的信息也很嘈杂。我们以Zhang等[2013]的应用为例,说明了这两个挑战。在这个例子中,Zhang等人的目的是利用配备GPS的出租车司机作为传感器,检测在加油站排队的时间(当他们正在给出租车加油时),进而推断在加油站为他们的车辆加油的人数。目标是估算一个加油站的汽油消耗量,最后是给定时间内全市的汽油消耗量。在这个应用中,我们得到的是出租车司机的GPS轨迹,它没有明确地告诉我们结果。另外,我们不能保证每个加油站随时都有出租车司机,这会导致数据丢失的问题。同时,出租车在车站的存在可能与其他车辆的存在有很大的不同(即偏态分布);
例如,在加油站看到更多的出租车并不意味着有更多的其他车辆。此外,出租车司机可能会把出租车停在靠近加油站的地方,只是为了休息或等待红绿灯。这些来自GPS轨迹数据的观测是有噪声的。简而言之,我们通常需要从人类传感器产生的部分、曲解、嘈杂和隐含的数据中了解我们真正需要的东西。
2. 异构数据计算:
- 从异质数据中学习相互强化的知识:解决城市挑战涉及广泛的因素(例如,探索空气污染涉及交通流、气象和土地使用的同时研究)。然而,现有的数据挖掘和机器学习技术通常只处理一种数据;例如,计算机视觉处理图像,自然语言处理基于文本。根据研究[Zheng et al. 2013b, Yuan et al. 2012],同等对待从不同数据源中提取的特征(如简单地将这些特征放入特征向量中并将其放入分类模型中)并不能达到最好的效果。此外,在应用程序中使用多个数据源会导致高维空间,这通常会加剧数据稀疏问题。如果处理不当,更多的数据源甚至会损害模型的性能。这就需要高级数据分析模型,这些模型可以在来自不同来源(包括传感器、人、车辆和建筑物)的多个异构数据之间相互学习增强的知识。参见4.1节了解更多细节。
- 有效和高效的学习能力:许多城市计算场景(例如,检测交通异常和监测空气质量)需要即时回答。除了仅仅增加机器的数量来加快计算速度,我们还需要将数据管理、挖掘和机器学习算法整合到一个计算框架中,以提供有效和高效的知识发现能力。此外,传统的数据管理技术通常是为单个模态数据源设计的。一种可以很好地组织多模式数据(如流数据、地理空间数据和文本数据)的先进管理方法仍然缺失。因此,多异构数据的计算是数据和算法的融合。参见第4.3节以获得更多讨论。
- 可视化:海量数据带来了海量的信息,需要更好的表达。对原始数据进行良好的可视化可以启发解决问题的新思路,而计算结果的可视化可以直观地揭示知识,帮助决策。数据的可视化也可以表明不同因素之间的相关性或因果关系。城市计算场景中的多模态数据导致高维视图,如空间、时间和社会,以实现可视化。如何在不同的视图中关联不同类型的数据并检测模式和趋势是一个挑战。此外,当面对多种类型和海量数据时,探索可视化[Andrienko et al. 2003]如何为人们提供一种交互方式来生成新的假设变得更加困难。这就要求将即时数据挖掘技术集成到可视化框架中,这在城市计算中仍然缺失。
3.混合物理和虚拟世界的混合系统:与搜索引擎或数字游戏不同的是,数据是在数字世界中产生和消费的,城市计算通常会将两个世界的数据整合在一起(例如,将流量和社交媒体结合起来)。另外,数据(如车辆的GPS轨迹)是在物理世界中生成的,然后发送回数字世界,如云系统。将数据与云中的其他数据源进行处理后,从数据中学习到的知识将通过移动客户端为物理世界的用户提供服务(如驾驶方向建议、出租车拼车、空气质量监测等)。这样一个系统的设计比传统的系统更具有挑战性,因为系统需要与许多设备和用户同时通信,并以不同的格式和频率发送和接收数据。
2.4. Urban Data
在本节中,我们将介绍城市计算中经常使用的数据源,并简要介绍在使用这些数据源时通常面临的问题。
2.4.1. Geographical Data. 道路网络数据可能是城市计算场景中使用最频繁的地理数据,如交通监控与预测[Pan and Zheng et al. 2013]、城市规划[Zheng et al. 2011b]、路由[Yuan and Zheng et al. 2010a, 2011b, 2013b]、能源消耗分析[Zhang et al. 2013]。它通常由一组边(表示道路段)和一组节点(表示道路交叉点)组成的图来表示。每个节点具有独特的地理空间坐标;每条边由两个节点(有时也称为终端)和一系列中间地理空间点来描述。其他属性,如长度、速度约束、道路类型和车道数量,都与边缘相关联。
POI(例如餐馆或购物中心)通常由名称、地址、类别和一组地理空间坐标来描述。
虽然城市中存在大量的POIs,但POIs的信息可能会随着时间而变化(例如,餐馆可能会更改名称,被移到新的位置,甚至被关闭)。因此,收集POI数据不是一项容易的任务。通常,产生POI数据有两种方法。一个是通过现有的黄页数据获得的。实体的地理空间坐标通过使用地理编码算法从其文本地址自动转换。另一种方法是在现实世界中手动收集POI信息,例如,携带GPS记录器来记录POI的地理空间坐标。后一种方法主要由一些地图数据提供商来实现,比如Navinfo和高德。最近,一些基于位置的社交网络服务,如Foursquare,允许终端用户在系统中创建一个新的POI,如果POI没有被包括进来的话。为了使POI的覆盖面更大,广泛使用的在线地图服务,如Bing和谷歌maps,通常结合上述两种方法来收集POI数据。结果,产生了相当多的问题。例如,我们如何验证一个POI的信息是否正确?有时,POI的地理空间坐标可能不准确,将人们引向错误的地方。或者,我们如何合并来自不同来源或方法的POI数据[Zheng 2010c]?
土地利用数据描述了一个区域的功能,如住宅区、郊区和森林,最初由城市规划者规划,在实践中通过卫星图像粗略测量。例如,美国地质调查局(U.S. Geological Survey)将美国每30m × 30m平方米的土地分为21种地被类型(USA ground cover),如草地、水和商业地被。在许多发展中国家,城市随着时间的推移而变化,许多新的基础设施被建造,旧建筑被拆除,城市的现实可能与最初的规划不同。由于卫星图像无法区分细粒度的土地利用类别,如教育、商业、住宅等,获取大城市现有的土地利用数据并不容易[Yuan and Zheng et . 2012a]。
2.4.2. Traffic Data. 收集交通数据的方法有很多,比如使用环路传感器、监控摄像头和浮动汽车。环路传感器通常成对嵌入主要道路(如高速公路)。这种传感器不是记录绝对时间,而是检测车辆穿过两个连续(即一对)探测器的时间间隔。已知一对环路探测器之间的距离,我们就可以根据时间间隔计算出道路上的行驶速度。通过计算一个时间段内穿过一对环路检测器的车辆数量,我们就可以知道道路上的交通量。由于环路传感器的部署和维护在资金和人力资源方面非常昂贵,这种交通监测技术通常用于主要道路,而不是低层街道。因此,回路传感器的覆盖范围相当有限。此外,回路传感器的数据并不能告诉我们车辆是如何在一条道路上以及两条道路之间行驶的。因此,车辆在十字路口的行驶时间(如等待交通灯和转向)无法从这种传感器数据中识别出来。
监控摄像头广泛部署在城市地区,产生大量反映交通模式的图像和视频。该数据为人们提供了一个直观的交通状况的地面真相。然而,将图像和视频自动转换为特定的交通流量和行驶速度仍然是一项具有挑战性的任务。由于道路的不同结构和不同的相机设置,如高度(对地面)、角度和焦距,很难将针对一个地点训练的机器学习模型应用到其他地点。因此,通过这种方法监测全市交通状况主要是基于人的努力。
浮动车辆数据是由在城市中行驶的带有GPS传感器的车辆生成的。这些车辆的轨迹将被发送到一个中央系统,并与道路网络匹配,得出道路段的速度。由于许多城市已经为不同目的在出租车、公交车和物流卡车上安装了GPS传感器,浮动汽车数据已经广泛可用。与环形传感器和基于监控摄像头的方法相比,基于浮动汽车的交通监控方法具有更高的灵活性和更低的部署成本。然而,浮动汽车数据的覆盖范围取决于探测车辆的分布,而探测车辆的分布可能会随着时间的推移而变化,并且在城市的时间跨度内是倾斜的。换句话说,数据稀疏问题仍然存在,需要先进的知识发现技术,能够在有限的数据基础上恢复全市的交通状况。Castro等人[2013]提出了一项关于将出租车的GPS轨迹转化为社会和社区动态的调查。
2.4.3. Mobile Phone Signals. 通话详细记录(CDR)是电话交换机生成的数据记录,它包含特定于电话呼叫的单个实例的属性,例如主叫方和接收方的电话号码、开始时间和通话持续时间。有了这样的数据,我们可以研究一个人的行为,或者在不同的用户之间建立一个网络。用户之间的相似度也可以推断出来。另一类移动电话信号更关注用户的位置,而不是手机之间的通信。使用三角定位算法,手机的位置可以通过三个或三个以上的基站粗略计算出来。这类数据代表了整个城市的人的流动性,可以用来检测城市的异常,也可以用来研究城市的功能区域和城市规划。有时这两种移动电话数据是集成的(例如,有电话之间的交易记录和每个电话的位置)。
2.4.4. Commuting Data. 在城市中旅行的人们会产生大量的通勤数据,比如地铁系统或公交线路的刷卡数据,以及停车场的购票数据。刷卡数据在城市的公共交通系统中广泛存在,人们在进入地铁站或乘坐公共汽车时都会刷射频识别卡。有些系统还要求人们在离开车站或下车时再次刷卡。每条交易记录包括进出车站的时间戳、车站的ID以及这次旅行的票价。这是另一种代表全市人口流动性的数据。
沿街停车通常是通过停车计价器支付的。车位的支付信息可以包括开罚单的时间和停车费用。数据可以反映一个地方周围车辆的交通状况,不仅可以用来改善城市的停车基础设施,还可以用来分析人们的出行模式。后者可以支持地理广告和地理位置选择业务。
2.4.5. Environmental Monitoring Data. 气象数据包括湿度、温度、气压、风速和天气状况,可以从公共网站爬取。空气质量数据,如PM2.5, NO2, SO2的浓度,可以从空气质量监测站获得。一些气体,如二氧化碳和一氧化碳,甚至可以通过便携式传感器检测到。在与人交流时,空气质量是用空气质量指数(AQI)和一个类别来表示的,例如:良好、适度和不健康。受交通流和土地利用等多种复杂因素的影响,城市空气质量因地点而异,并随时间发生巨大变化。因此,有限数量的监测站无法揭示整个城市的细颗粒物空气质量。
噪声数据是另一种直接影响人们身心健康的环境数据。噪声污染的测量既取决于噪声的强度,也取决于人们对噪声的容忍度[Zheng et al. 2014a]; 后者随时间而变化。在纽约市,有一个311平台,人们可以通过打电话投诉不完美的(但不是紧急的)事情。每个投诉都与一个时间戳、一个位置和一个类别相关联。噪声是数据中的第三大类。这些数据可用于城市噪声污染的诊断。
卫星遥感用不同长度的射线扫描地球表面,生成代表广大地区生态和气象的图像。
2.4.6. Social Network Data. 社交网络数据由两部分组成。一种是社会结构,用图表表示,表示用户之间的关系、相互依赖或互动。另一种是用户生成的社交媒体,如文本、照片和视频,这些媒体包含关于用户行为/兴趣的丰富信息。当把一个位置添加到社交媒体上时[Zheng等人2011a](例如Foursquare的签到数据和地理标记的推文),我们可以模拟人们在城市地区的移动,这有助于我们检测和理解城市异常[Lee et al. 2010; Pan and Zheng et al. 2013]。
2.4.7. Economy. 有各种各样的数据代表一个城市的经济动态(例如,信用卡交易记录、股票价格、房价和人们的收入)。当综合使用时,这些数据集可以捕捉一个城市的经济节奏,从而预测未来的经济。
2.4.8. Energy. 汽车在路面和加油站的汽油消耗量反映了一个城市的能源消耗。这些数据可以直接从传感器获得(例如,一些保险公司已经从一辆汽车上收集了不同类型的传感器数据),也可以从其他隐含的数据源推断(例如,从一辆汽车的GPS轨迹)。这些数据可以用来评估一个城市的能源基础设施(如加油站的分布),计算道路表面车辆的污染排放,或找到最省油的驾驶路线。
此外,公寓或建筑的电力消耗可以用来优化住宅能源使用,将高峰负荷转移到低需求时期。
2.4.9. Health Care. 医院和诊所已经产生了大量的保健和疾病数据。此外,可穿戴计算设备的进步使人们能够监测自己的健康状况,如心率、脉搏和睡眠时间。这些数据甚至可以被发送到云端,用于诊断疾病和进行远程医疗检查。除了研究个人的健康状况,在城市计算中,我们还可以综合使用这些数据集来研究环境变化对人们健康的影响。例如,空气污染与香港的哮喘病有何关系?城市噪音如何影响纽约人的心理健康?
3. APPLICATIONS IN URBAN COMPUTING
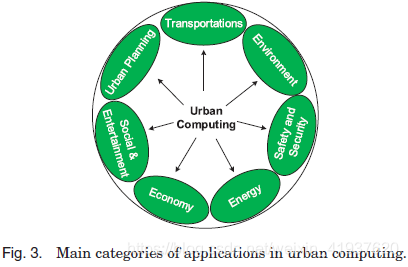
在介绍城市计算中经常使用的技术之前,我们首先列出了城市规划、交通、环境、能源、社会、经济和公共安全的7类城市计算场景,如图3所示。
我们在每个类别中选择了一些有代表性的应用,主要关注其目标、动机、结果和使用的数据。这里简要介绍了每个应用程序的方法,但将在第5节中进行更多讨论。
3.1. Urban Computing for Urban Planning
有效规划对建设智慧城市具有重要意义。制定城市规划需要评估一系列广泛的因素,如交通流量、人的流动性、兴趣点和道路网络结构。这些复杂和快速演变的因素使城市规划成为一项非常具有挑战性的任务。传统上,城市规划者依靠劳动密集型调查来为他们的决策提供信息。例如,为了了解城市通勤模式,人们根据旅游调查数据进行了一系列的研究[Hanson and Hanson 1980; Gandia 2012;Jiang et al. 2012]。通过调查获得的资料可能不够充分和及时。最近,在城市空间中产生的广泛可用的人口流动数据实际上反映了城市的潜在问题,为城市规划者提供了更好地制定未来规划的机会。
3.1.1. Gleaning Underlying Problems in Transportation Networks. Zheng等[2011b]通过分析3.3万辆出租车3年的GPS轨迹,收集了北京交通网络的潜在问题。
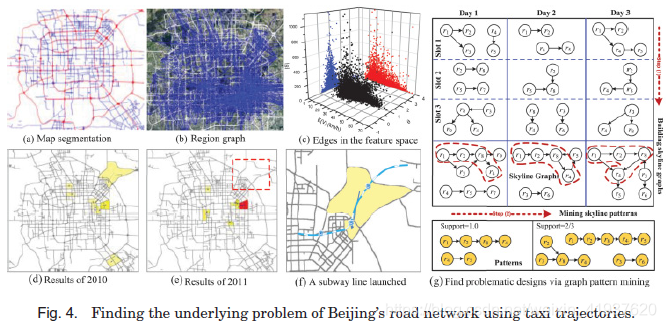
他们首先利用高速公路和主干道等主要道路将北京城区划分为不连贯的区域[Yuan et al. 2012b],如图4(a)所示。从每个出租车轨迹中提取乘客的上客点和落客点,以制定这些区域之间的起始目的地(origin–destination, OD)转换。然后根据OD转换建立区域图,其中一个节点为区域,一条边表示两个区域之间转换的聚合,如图4(b)所示。使用数据驱动的方法,将一天分成几个时间段,分别对应早高峰、晚高峰和其他时间。对于每个时间跨度,根据出租车轨迹落在该时间跨度内建立区域图。如图4(c)所示,基于相关的滑行轨迹,提取了每条边的三个特征,即滑行量(|S|)、滑行平均速度E(V)和绕行比θ。在三维特征空间中,用一个点来表示边,具有大|S|、小E(V)和大θ的点可能是潜在的问题。即两个区域之间的连接不够有效,无法支持在两个区域之间行驶的交通,造成了体积大、速度慢、绕道率大的问题。
使用skyline algorithm,可以从每个时隙的数据中检测出一组点(称为天skyline edges)。如图4(g)所示,将同一天内不同时间段的skyline edges在空间上被某些节点重叠,在时间上相邻,进行连接,形成skyline graphs。最后,通过多日的天际线图挖掘,可以得到一些子图模式; 例如,r1→r2→r8→r4在所有3天发生。这样的图形模式代表了道路网络的潜在问题,显示了各个区域之间的相关性,避免了一些交通事故可能造成的错误警报。通过对比连续2年的检测结果,甚至可以评价新建交通设施是否运行良好。如图4(d)、4(e)、4(f)所示,2010年发现的潜在问题在2011年因新开通的地铁线路而消失。总之,地铁线路很好地解决了这个问题。
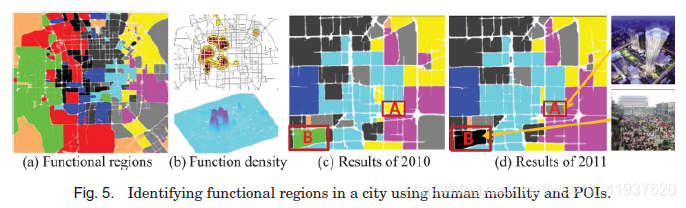
3.1.2. Discover Functional Regions 发现功能区域. 城市的发展逐步培育出不同的功能区,如教育区和商业区,这些功能区支持着人们不同的城市生活需求,是一种有价值的组织技术,可以构建一个大都市的详细知识。这些区域可能是城市规划者人为设计的,也可能是根据人们的实际生活方式自然形成的,并随着城市的发展而改变其功能和疆域。对城市功能区域的理解可以校准城市规划,并促进其他应用,如选择商业地点。
Yuan等人[2012a]提出了一个名为DRoF的框架,利用区域间的人员流动和区域内的POIs发现城市中具有不同功能的区域。例如,图5(a)中显示的红色区域表示北京的教育和科学领域。然而,一个区域的函数是复合的而不是单一的,用跨多个函数的分布来表示。相同颜色的区域实际上有着相似的功能分布。另一方面,即使一个区域被认定为教育区域,也并不意味着该区域的每个部分都具有教育功能。例如,一所大学周围可能有一些购物中心。因此,对于一个函数,Yuan等人进一步确定了其核密度分布[Wand and Jones 1995]。图5(b)为北京市商业区域密度分布图;区域越暗,越有可能是商业区域。在他们的方法中,根据主要道路,如高速公路和城市高速公路,将一个城市划分为不连贯的区域。他们推断出每个区域的功能使用一个基于主题的推理模型,文档作为一个地区、一个函数作为一个话题,POIs的类别(例如,餐馆和购物中心)作为元数据(作者、从属关系和关键字),和人类移动模式(当人们到达/离开这一地区,人们从哪里来和离开)的话。因此,一个区域由函数的分布来表示,每一个函数又由移动模式的分布来表示。在这里,人类的流动性可以区分属于同一类别的POIs的流行。它也表明了一个区域的功能; 例如,人们早上离开居民区,晚上返回。具体来说,人类移动数据是从2010年和2012年3个月期间3.3万辆出租车生成的GPS轨迹中提取出来的。最后,根据聚类结果和人类标记,识别出9种功能区域。
还有其他方法可以解决这个问题。例如,Toole等人[2012]利用电话细节记录,即在任何时候拨打电话或发送短信时提供手机位置信息,来测量电话活动的时空变化。通过使用分类算法,他们根据该地区的手机动态活动模式推断出该地区的土地使用情况。波士顿地区约60万用户三周的通话记录被用来推断四种土地用途。
与Yuan的方法是一种无监督学习算法不同,Toole等人使用监督学习算法来解决这个问题。在另一个例子中,Sheng等人[2010]使用数据库方法搜索与给定地区POIs分布相似的一些地区。由于POI数据在确定区域功能方面非常重要,确保其质量(如不同来源的POI的匹配和合并)也是一个实际问题[Zheng等。2010c]。
3.1.3. Detecting a City’s Boundary. 政府划定的区域边界可能不尊重人们跨越空间的自然互动方式。通过人与人之间的互动发现区域的真实边界,可以为决策者提供决策支持工具,为城市的最优行政边界提供建议。这一发现也有助于政府了解城市领土的演变。这类研究的总体想法是先建立一个网络位置之间基于人机交互(例如,GPS轨道或电话记录),然后使用一些分区网络社区发现方法,找到位置集群与集群中密集的位置之间的相互作用之间的集群。
Ratti等人[2010]通过分析从英国一个大型电信数据库推断出的人类网络,提出了一种细粒度的区域划分方法。给定一个地理区域和居民之间的联系强度,他们将该区域划分为更小的、不重叠的区域,同时最大限度地减少对每个人联系的干扰。该算法产生了地理上具有凝聚力的区域,与行政区域相对应,同时揭示了之前仅在文献中假设的意想不到的空间结构。
Rinzivillo等人[2012]讨论了在较低的城市或县的空间分辨率下寻找人类流动边界的问题。他们将车辆的GPS轨迹映射到各个区域,在比萨建立一个复杂的网络。然后使用社区发现算法,即Infomap,将网络划分为不重叠的子图。
3.2. Urban Computing for Transportation Systems
3.2.1. Improving Driving Experiences. 寻找快速行驶路线既节省了司机的时间,也节省了能源消耗,因为交通拥堵会浪费大量的汽油[Hunter et al. 2009;Kanoulas等[2006]。人们对历史交通模式进行了深入研究[Bejan等人,2010;Herrera等人2010年],根据浮动车数据估计实时交通流量[Herring等人2010年],并预测个别路段未来的交通状况[Castro-Neto等人2009年],如车辆的GPS轨迹、WiFi和GSM信号。然而,对全市交通模式进行建模的工作仍然很少。
VTrack [Thiagarajan et al. 2009]是一个基于wifi信号的旅行时间估计系统,测量和定位时间延迟。该系统使用基于隐马尔可夫模型(HMM)的地图匹配方案,通过插值稀疏数据来识别最可能由用户驱动的路段。在此基础上,提出了一种出行时间估计方法。实验表明,VTrack在这些位置估计中能够容忍显著的噪声和中断,并且仍然成功地识别出容易延迟的片段。
T-Drive [Yuan and Zheng et al. 2010a, 2011b, 2013b]是一个根据天气、交通条件和个人驾驶习惯提供个性化驾驶方向的系统。该系统的第一版[Yuan and Zheng et al. 2010a]仅根据出租车的历史轨迹给出了实际最快的路径。关键的见解由两部分构成:(1)gps出租车可以被视为移动传感器不断探索路面上的交通模式,和(2)出租车司机有经验的司机可以找到一个真正快速路线基于他们的知识,它不仅包含了路线的距离也交通条件和交通事故的概率。所以,出租车的轨迹暗示了交通模式和人类智能。处理数据稀疏(例如,许多道路段就没有出租车穿越),全市交通模式是建模为具有里程碑意义的图形,如图6所示(一个),红色节点在哪里top-k路段(名为地标)经常乘出租车旅行,和每一个蓝色的边表示两个地标之间的聚合的出租车上下班。基于出租车数据,采用方差熵聚类算法估计各地标边缘的行驶时间。T-Drive使用了一种两阶段路由算法,它首先在地标图中搜索一个粗略的路线(由一系列地标表示),然后用一个详细的路线连接这些地标。
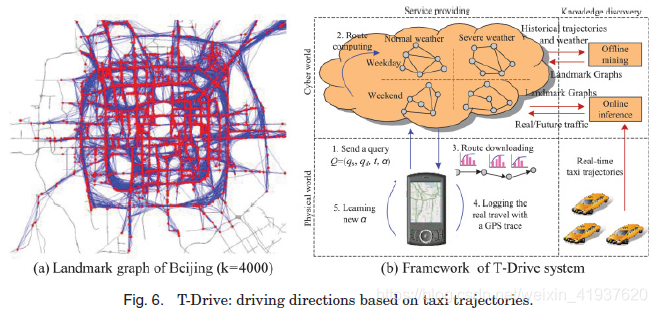
第二版T-Drive [Yuan and Zheng et al. 2011b]通过挖掘出租车历史轨迹和天气状况记录,构建了4个地标图,分别对应不同的天气和天数,如图6(b)所示。该系统还根据最近收到的出租车轨迹计算实时交通流量,并根据实时交通流量和相应的地标图预测未来的交通状况。用户从具有gps功能的手机上提交一个查询,包括一个源qs、一个目的地qd、一个出发时间t和一个自定义因子α。这里,α是一个向量,表示用户在不同的地标边缘上的典型驾驶速度。α是在一开始设置的默认值,并根据用户实际驱动的轨迹逐渐更新。T-Drive为每个用户提供了更准确的评估,并会在用户的驾驶习惯随时间改变时调整其建议。因此,该系统每30分钟可以节省5分钟的行驶时间。
Wang等[2014]提出了全市和实时模型估算任何路径的旅行时间(表示为一系列的连接道路段)目前在一个城市,根据接收到的GPS车辆轨迹在当前时段和在一段时间内的历史以及地图数据源。这个问题有三个挑战。首先是数据稀疏性问题;也就是说,在当前时间段内,许多路段可能不会有任何装有GPS的车辆行驶。在大多数情况下,我们也无法找到精确遍历查询路径的轨迹。第二,对于带有轨迹的路径片段,有多种使用(或组合)轨迹来估计相应的旅行时间的方法。找到最优组合是一个具有挑战性的问题,需要在路径长度和轨迹数(即支撑)之间进行权衡。第三,我们需要立即回答用户的查询,这可能发生在一个城市的任何地方。这就需要一种高效、可扩展、有效的解决方案,能够实现全市范围内的实时出行时间估算。
为了解决这些挑战,Wang等人利用三维张量模拟了不同时段不同路段不同司机的出行时间。结合从轨迹和地图数据中学到的地理空间、时间和历史上下文,他们通过上下文感知张量分解方法填补了张量的缺失值。然后,他们设计并证明了一个目标函数来模拟上述的权衡,我们找到最优的轨迹连接通过动态规划解决估计。此外,他们还建议使用频繁轨迹模式(从历史轨迹中挖掘)来缩小拼接候选轨迹的规模,并使用基于后缀树的索引来管理当前时间段内接收的轨迹。在2个月的时间里,超过3.2万辆出租车生成了GPS轨迹,在大量实验的基础上评估了提出的解决方案。结果表明,该方法的有效性、效率和可扩展性超过了基准方法,如每个道路段的旅行时间的简单累加。
3.2.2. Improving Taxi Services. 出租车是公共交通和私人交通之间的一种重要的通勤方式,几乎提供上门的旅行服务。在像纽约、北京这样的大城市,人们通常要等上一段相当长的时间才会搭上一辆空车,而出租车司机则急于招人。有效地将乘客与空车连接起来,对于节省人们的等候时间,增加出租车司机的利润,减少不必要的交通和能源消耗具有重要意义。为了解决这一问题,我们进行了三类研究:
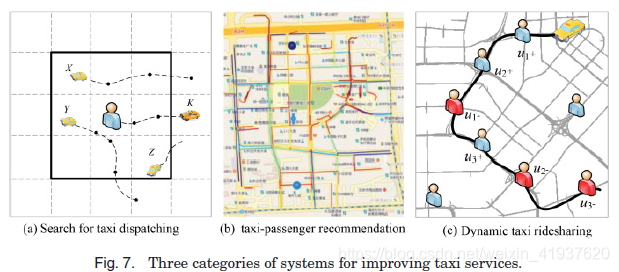
(1)出租车调度系统:这类系统[Lee et al. 2004]接受用户的预订请求,分配出租车来接用户。大多数系统要求人们提前预定出租车,因此降低了出租车服务的灵活性。一些实时调度系统根据距离和时间的最近邻原则,在用户周围搜索合适的出租车。系统面临的主要挑战是搜索出租车时出租车运动的不确定性[Phithakkitnukoon et al. 2010; Yamamoto et al. 2010]。如图7(a)所示,如果我们知道出租车K正在向用户移动,而其他出租车则在空间范围之外,那么出租车K可能比(X, Y, Z)更适合搭载用户。此外,还应考虑路线上的交通状况来估计接机时间。
(2)出租车推荐系统:这类系统从推荐的角度来解决这个问题。Ge等人[2010]开发了移动推荐系统,该系统能够为出租车司机推荐一系列的取车点或一系列潜在的停车位置。该系统的目标是最大限度地提高企业成功的可能性和减少能源消耗。
T-Finder [Yuan and Zheng et al. 2011a, 2014]为出租车司机提供了一些地点和到达这些地点的路线,他们更有可能快速地(在这条路线中或在这些地点)接住乘客,并使下一次出行的利润最大化。T-Finder还向人们推荐一些可以很容易找到空车的地点(步行范围内)。如图7(b)所示,我们用不同的颜色来可视化不同路段找到一辆空闲出租车的概率,红色表示非常困难,蓝色表示非常可能。出租车的停车位置也可以通过GPS轨迹探测到,从而估计出在接下来半小时内到达的出租车数量。这类系统的主要挑战是处理数据稀疏问题。例如,如何计算在没有足够数据的路段找到一辆空载的士的概率?
(3)出租车拼车服务:出租车拼车在满足人们通勤需求的同时,对节约能源消耗、缓解交通拥堵具有重要意义。T-Share [Ma and Zheng et al. 2013]是一个大规模的动态出租车共享系统,它接受乘客从智能手机发送的实时乘车请求,并根据时间、容量和资金的限制,安排出租车通过拼车来搭载乘客。如图7(c)所示,出租车按顺序取u1和u2,落u1,取u3,落u2和u3,其中+表示取车,-23表示落车。T-Share维护一个时空指数,存储每个出租车的状态,包括当前的位置,乘客数量,和计划的路线,以交付这些乘客。当收到一个乘坐请求时,T-Share首先搜索一组可能满足用户查询的候选出租车的索引,基于一些时间限制。然后提出了一种调度算法,将查询的行程插入到每个候选出租车的现有行程中,找到满足查询且行程增量最小的出租车。该系统创造了三赢的局面,产生了重大的社会和环境效益。根据仿真基于出租车轨迹由超过30000北京的出租车,与传统nonridesharing相比,该技术能够节省每年1.2亿升的汽油在北京,可以支持100万辆汽车1.5个月,节省1.5亿美元,并减少2.46亿公斤的二氧化碳排放量。此外,乘客节省7%的出租车费用,获得服务的机会增加300%,而出租车司机的收入增加了10% [Ma and Zheng et al. 2013]。
实现这样一个出租车共享系统的困难在于两个方面。一是对出租车出行的时间、运力和资金约束进行建模。二是由于乘客和出租车的动态性和大规模带来的计算量大,需要高效的搜索和调度算法。出租车用户通常在出发前最后一分钟提交他们的查询,而不是提前安排。出租车可以在任何时间、任何地点发出搭车请求,而出租车却在城市中不停地行驶。当然,要把这项技术推向现实,还有其他非技术问题需要解决(例如乘客和出租车司机的信誉以及一些安全问题)。
3.2.3. Improving Public Transportation Systems. 到2050年,预计70%的世界人口将居住在城市。城市规划者将面临一个日益城市化和污染的世界,世界各地的城市都承受着过度紧张的道路交通网络。因此,建立更有效的公共交通系统以替代私人车辆,已成为一项紧迫的优先任务,既可提供良好的生活质量和更清洁的环境,又可在经济上保持对潜在投资者和雇员的吸引力。公共公共交通系统,加上综合收费管理和先进的旅客信息系统,被认为是更好地管理交通的关键因素。在下面的章节中,我们回顾了城市计算在三种公共交通模式上的一些最新应用:公共汽车、地铁和共享自行车计划。
1) Bus services: 为了吸引更多的乘客,公共汽车服务不仅需要更频繁,而且需要更可靠。Watkins et al. [2011]的影响进行了研究提供实时公交到达信息直接在乘客的手机,发现它不仅减少等待时间的那些已经在公交车站也经历的实际等待时间的客户计划使用这些信息他们的旅程。换句话说,移动实时信息能够在公交乘客到达车站之前提供信息,从而改善他们的体验。如果没有在公交车上安装GPS接收器,人们就会探索其他的解决方案来收集同样的信息,但采用的是一种更便宜、侵入性更小的方式。Zimmerman等人[2011]是第一个开发、部署和评估名为提拉米苏的系统的人,在该系统中,通勤者可以共享从他们手机上的GPS接收器收集到的GPS轨迹。Tiramisu然后处理传入的跟踪信息,并为公共汽车生成实时到达时间预测。GPS轨迹可能是一个混合的不同的运输模式(例如,先坐公共汽车然后走),Zheng et al. [2008a, 2008b, 2010b]提出了一个方法来推断用户年代交通模式(包括开车,走路,骑自行车,坐公共汽车)在每一段的轨迹。一旦将轨迹按交通方式分类,就可以更准确地预测公交出行时间或驾驶时间。
随着城市化进程不断改变我们的城市,公交服务必须不断调整路线,以满足市民的出行需求。然而,公交线路更新的速度远低于市民需要改变的速度。Bastani等人[2011]提出了一种以数据为中心的方法来解决这个问题:他们开发了一种名为flexi的新型小型穿梭运输系统,其路线通过分析大量出租车轨迹中的乘客出行数据灵活地从实际需求中得出。与此类似,Berlingerio等人[2013]分析了来自科特迪瓦阿比让的匿名和汇总的话单,目的是为使用移动电话的公共交通网络规划提供信息。在这种情况下,在西方盛行的资源密集型交通规划过程是负担不起的;
使用移动电话数据进行交通分析和优化代表了发展中国家交通规划的一个新前沿,在这些国家,移动电话已经深入渗透,因此可以很容易地挖掘它们的匿名流量数据。
2) Subway services: 自动收费系统(如伦敦的牡蛎卡London’s Oyster
Card、西雅图的虎鲸卡Seattle’s Orca、北京的一加通Beijing’s Yikatong、香港的八达通Hong Kong’s Octopus等)已被引进,并已在世界各地的大都市广泛采用。除了简化城市地铁网络的列车服务,这些智能卡每次出行都会创建一个数字记录,可以连接到每个旅客身上。挖掘旅客进出车站时产生的旅行数据,可以深入了解旅客本身:他们的隐含偏好、旅行时间和通勤习惯。
Lathia等人[2010]挖掘AFC数据的目的是建立更精确的旅行路线规划者。他们使用了伦敦地铁系统收集的数据,该系统采用基于rfid的非接触式智能卡(牡蛎卡)进行电子售票。与某些AFC系统不同,牡蛎卡必须在进出车站时使用。对伦敦地铁使用情况的两个大型数据集的深入分析表明,乘客之间存在着实质性的差异。
基于这些发现,他们自动从AFC数据中提取了一些特征,这些特征隐含地捕捉了用户对旅行的熟悉程度、用户与其他旅行者的相似度以及用户的旅行背景等信息。最后,他们利用这些特性来开发个性化的旅行工具的目标可以作为预测形式化的问题:(1)个性化的旅行时间预测任何来源和目的地之间对为用户提供准确的估计的运输时间和(2)预测和排名的利息个人旅行者将会在接收警报通知特定站点基于他们过去的历史。在后续的研究中,Ceapa等人[2012]对相同的历史牡蛎卡轨迹进行了时空分析,发现拥挤现象在工作日是一种高度规律的现象,峰值出现的时间间隔相当短。他们继续构建拥挤程度的预测器,然后将其整合到先进的旅行者信息系统中,为旅行者提供更个性化和高质量的计划服务。
Lathia和Capra [2011a]也分析了AFC数据,以估计未来的旅游习惯,再次以伦敦为例。通过分析历史上的旅行痕迹,他们已经能够提取出个人旅行的时间、地点和频率等特征,然后可以高度准确地预测。他们利用这些发现来构建工具,根据旅行者的预期旅行习惯,向他们推荐最适合购买的机票。通过这样做,他们证明了他们每年可以节省几十万英镑,因为人们对自己旅行行为的误解往往导致购买错误的票价[Lathia and Capra 2011 1b]。
3) Bike-sharing systems:随着世界人口的增长和城市人口比例的不断增加,设计、维护和推广可持续的城市交通模式显得尤为重要。共享自行车计划[Shaheen et al. 2010]就是这样一个例子:它们在世界大都市的普及清楚地反映了这样一种信念,即提供便捷的健康(和快捷)的交通方式将使城市摆脱目前面临的拥堵和污染问题。详细记录通常是关于共享可用自行车运动(从/当一辆自行车被带到一辆自行车返回时),从而允许研究人员分析这些数字痕迹来帮助的用户,谁可能会受益于理解和预测将如何使用该系统在规划自己的行程;交通运营商可以从更精确的自行车流量模型中受益,从而在一天中适当地平衡车站的负荷;以及城市规划者,他们可以在设计社会空间和政策干预时利用流量数据。
Froehlich等人[2009]是首批对共享自行车系统采取以数据为中心的方法的人之一,他们应用大量数据挖掘技术来揭示城市数据的时空趋势。他们对西班牙巴塞罗那的Bicing系统进行了为期13周的深入分析,清楚地展示了一天中的时间、地理位置(特别是城市地理区域内的站点群)和使用之间的关系。Kaltenbrunner等人[2010]在巴塞罗那进行了类似的Bicing研究,Borgnat等人[2009]在法国里昂进行了一项研究。在这些研究中,作者着重于自行车站数据的时间属性,以训练和测试分类器来预测每个站点的状态(自行车的可用性)。Nair等人[2013]分析了来自巴黎(法国)Ve lib的数据,有关使用与火车站的邻近:他们揭示了自行车使用与多模式旅行之间的关系,从而为车站安置政策提供关键见解。最后,Lathia等人[2012]分析了伦敦自行车租赁计划在两个不同的3个月期间,并得出了关于访问政策改变如何影响整个城市自行车使用的定量证据。

3.3. Urban Computing for the Environment
没有有效的适应性规划,城市化的快速发展将成为对城市环境的潜在威胁。最近,我们目睹了越来越多的污染在环境的不同方面,如空气质量,噪音,垃圾,在世界各地。在实现人们生活现代化的同时,保护环境是城市计算的重中之重。
3.3.1. Air Quality. 城市空气质量信息(如PM2.5浓度)对保护人类健康和控制空气污染具有重要意义。许多城市通过建立地面空气质量检测站来监测pm2.5。然而,由于建造和维护空气质量监测站的费用昂贵,一个城市的空气质量监测站数量有限(如图8(a)所示)。不幸的是,空气质量随地点的变化呈非线性变化,并取决于多种因素,如气象、交通量和土地用途。因此,如果没有测量站,我们就无法真正了解一个地点的空气质量。
移动通信和传感技术的进步促进了基于众包的应用程序的发展,这种应用程序将复杂的问题分解为小任务,并将这些小任务分配给用户网络。个人用户的回报将形成能够解决复杂问题的集体知识。“哥本哈根车轮”是一个在自行车车轮上安装环境传感器的项目,它可以感知一个城市的精细环境数据,包括温度、湿度和二氧化碳浓度。骑自行车的人力劳动被转化为电力,以支持自行车传感器的操作。
此外,车轮还可以与用户的手机进行通信,通过手机将收集到的信息发送到后端系统。同样,Devarakonda等人[2013]提出了一种基于车辆的实时测量细颗粒物空气质量的方法。他们设计了一种由GPS接收器、CO传感器和蜂窝调制解调器组成的移动设备。在多辆车辆上安装这样的装置,他们就能监测整个城市的CO浓度。尽管通过众包的方式监测环境有巨大的潜力,但只对少数气体有效,比如二氧化碳和一氧化碳。用于测量PM2.5和PM10等气溶胶的设备,对于个人来说并不容易携带。此外,这些设备需要较长的传感时间(例如2小时)才能产生准确的测量结果。
另一个研究分支(如[Guehnemann et al. 2004])是首先根据浮动汽车的数据估计道路表面的交通流,然后根据环保主义者制定的一些经验公式计算车辆的排放量。
这是一种很有前途的方法来估计道路附近的空气污染,但不能揭示整个城市的空气质量,因为车辆的排放只是空气污染的一部分。
不同于现有的解决方案,郑et al。(2013 b, 2014)的实时和细粒度在城市空气质量信息(如图8所示(b))基于历史和实时空气质量数据报告现有监视站和各种数据源中观察到,如气象、交通流、人类的机动性,公路网络结构和POIs。而不是使用古典物理模型,明确基于经验公式结合因素假设,他们从大数据的角度解决这个问题,也就是说,使用数据挖掘和机器学习技术的多样性之间建立一个网络数据源和空气质量指数(见4.3节中更多的技术细节)。如图8(c)所示,细粒度的空气质量信息可以帮助人们确定何时何地慢跑,或何时关上窗户或戴上口罩。如图8(d)所示,如果现有监测站还不够,这些信息还可以用来建议我们可能需要建立更多监测站的地点。这也向找出城市空气污染的根本原因迈出了一步,从而为政府的决策提供信息。利用北京、上海、武汉和深圳等10个城市的真实数据来源对该方法进行了评估。一个公共网站是http://urbanair.msra.cn/。
Chen等人[2014]介绍了在中国四个微软园区部署的室内空气质量监测系统。该系统由部署在建筑物不同楼层的传感器、采集并分析传感器数据和公众空气污染信息的云以及向终端用户实时显示展台室内外环境空气质量数据的客户端组成。该系统为用户提供室内空气质量信息,可以为人们在办公区域的决策提供依据,比如什么时候去健身房锻炼或在办公室增设一个空气过滤器。室外和室内环境中PM2.5浓度的差距可以衡量HVAC(供暖、通风和空调)系统在过滤PM2.5方面的有效性。此外,该系统整合了室外空气质量信息和室内测量,以自适应控制暖通空调设置,以优化运行时间w.r.t.能源效率和空气质量保护。利用基于神经网络的方法,系统甚至可以根据室内外PM2.5浓度、气压、湿度等6个因素预测空调系统将室内PM2.5浓度降至健康阈值以下所需的净化时间。考虑到净化时间和人们在建筑中开始工作的时间,可以建议暖通空调系统应该比原计划提前打开多少小时。
使用3个月的数据进行的大量实验证明了我们的方法优于基线方法(例如,线性回归)。该系统在精度下降较小的情况下,可以推断出较短的净化时间,从而节省大量的能源。
3.3.2. Noise Pollution. 城市的复合功能和复杂的环境,包括不同的基础设施和数百万的人口,不可避免地会产生大量的环境噪声。因此,世界各地有大量的人暴露在严重的噪音污染中,这可能导致严重的疾病,从听力障碍到负面影响生产力和社会行为 [Rana et al. 2010]。
作为一项减排战略,美国、英国、德国等一些国家已经开始监测噪音污染。他们通常使用噪音图(一个区域噪音水平的视觉表示)来评估噪音污染水平。噪音地图是根据交通流量数据、道路或铁路类型和车辆类型等输入的模拟计算的。由于收集这些输入数据非常昂贵,这些地图需要很长一段时间才能更新。
Silvia等[2008]利用无线传感器网络评估城市地区的环境噪声污染。然而,部署和维护全市范围的传感器网络,特别是在像纽约这样的大城市,在资金和人力资源方面是非常昂贵的。
另一个解决方案是利用众包,人们通过移动设备(如智能手机)收集和分享周围环境的信息。例如,NoiseTube [Nicolas et al. 2009]提出了一种以人为中心的方法,利用移动电话用户共享的噪音测量数据来绘制城市的噪音地图。基于NoiseTube, D Hondt和Stevens[2011]在安特卫普市1平方公里范围内进行了噪声测绘的公民科学实验。还进行了大量的校准实验,以研究频率依赖性和白噪声行为。本实验的主要目的是研究参与式感知获得的噪声图的质量,并与基于官方模拟的噪声图进行比较。
在Rana等人[2010]中,设计并实现了一种端到端的、上下文感知的噪声映射系统,称为Ear-Phone。与Nicolas等人[2009]和D Hondt和Stevens[2011]中的手机用户主动上传他们的测量数据不同,提出了一种机会主义的传感方法,在不通知智能手机用户的情况下收集噪音级数据。本文解决的一个主要问题是对手机感知上下文进行分类,即口袋(包)或手,这与感知数据的准确性有关。为了从不完整和随机样本中恢复噪声图,Rana等[2013]进一步研究了多种不同的插值和正则化方法,包括线性插值、最近邻插值、高斯过程插值和L-1范数最小化方法。
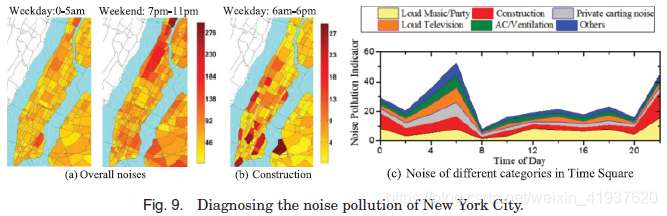
为全市范围内的噪音污染建模实际上远远不止是测量噪音的强度,因为噪音污染的测量也取决于人们对噪音的容忍度,这种容忍度随着时间的推移而变化。例如,在晚上,人们对噪音的容忍度比白天低得多。不过,夜间较小的噪音可能被认为是较严重的噪音污染。因此,即使我们可以在各地部署声音传感器,仅根据传感器数据诊断城市噪声污染是不够的。此外,城市噪音通常是多种声源的混合。了解噪音的构成(例如,在晚高峰时段,一个地方40%的噪音来自酒吧音乐,30%来自车辆交通,10%来自建筑)对帮助解决噪音污染至关重要。
自2001年以来,纽约市开设了一个名为311的平台,人们可以通过使用手机应用程序或打电话来抱怨这座城市的缺陷;在311调查数据中,噪音是第三大投诉类别。由于每个噪音投诉都与一个位置、时间戳和细粒度的噪音类别相关联,如吵闹的音乐或建筑噪音,这些数据实际上是人类作为传感器和人群感知的结果,包含丰富的人类智能,可以帮助诊断城市噪音。Zheng等[2014b]利用311个投诉数据,结合社交媒体、路网数据和POIs,推断出纽约市各区域一天中不同时段的细粒度噪声状况(包括噪声污染指标和噪声成分)。根据整体噪音污染指标,我们可以在不同时间段(如周末早上0 - 5点和晚上7 - 11点)对位置进行排序,如图9(a)所示;区域颜色越深,噪音污染越严重。或者,我们可以根据特定的噪音类别(如建筑噪音)对位置进行排序,如图9(b)所示。我们还可以检查特定位置随时间变化的噪声组成(例如,时间广场),如图9(c)所示。
他们用三维张量模拟了纽约市的噪音状况,三维张量代表区域、噪音类别和时段。通过上下文感知张量分解方法填补张量的缺失项,他们恢复了整个纽约市的噪音情况。噪音信息不仅可以提高个人的生活质量(例如,帮助找到一个安静的地方定居),而且可以为政府官员解决噪音污染的决策提供信息。
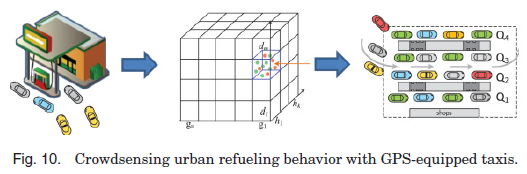
3.4. Urban Computing for Urban Energy Consumption
城市化的快速发展消耗了越来越多的能源,需要能够感知城市规模能源成本、改善能源基础设施、最终降低能源消耗的技术。
3.4.1. Gas Consumption. Zhang等人[2013]提出了一种对加油行为和全市汽油消费进行实时感知的方法。该方法使用人类作为传感器,通过分析和绘制推断的GPS轨迹被动收集的出租车。首先,他们检测加油事件,这是出租车访问加油站,从GPS轨迹,如图10的左边所示。对加油事件的检测包括在加油站等待的时间和为车辆加油的时间。其次,如图10的中间部分所示,他们构建了一个张量,三个维度分别表示加油站、星期几和一天中的时间。每个条目包含在特定日期的特定时间段和特定加油站检测到的加油事件。对于包含足够检测到的加油事件的条目,每个条目中花费的时间都是根据加油事件的分布来估计的。对于那些很少或甚至没有加油事件的情况,他们使用上下文感知的协同过滤方法来解决数据稀疏问题。最后,如图10右侧所示,他们将每个加油站视为一个排队系统,用在加油站的时间来计算司机到达率,这是这段时间内的顾客数量,可以间接地表示油耗。因此,输出是每个时间段内每个加油站花费的时间和燃料使用的全局估计值。参考4.3节中的例子3了解更多的方法论细节。
提供驾驶行为信息的生态反馈技术已被证明是促进节能减排的驾驶变革的有效手段。Tulusan等人[2012]证明,即使在没有货币激励的情况下(即司机不支付燃油费用),智能手机应用程序也可以提高燃油效率。鉴于公司用车的比例很大,研究结果也具有很高的实际意义,并激励未来生态驾驶反馈技术的研究。
最近,一些保险公司利用金钱奖励,鼓励客户分享各种汽车传感器数据记录的驾驶行为,比如踩油门、刹车和转弯。这些数据可以用来估计司机发生事故的概率,从而帮助确定明年的保险价格。这种详细的驾驶行为数据的大量的人将使我们能够了解一个城市的即时能源消耗的能源成本和分析一个特定的路线,因此提出一些节能解决方案(例如,建议路线使用最少的气体)。
Shang等人[2014]利用出租车等车辆样本的GPS轨迹,即时推断出当前时间段内城市路网中行驶车辆的油耗和污染排放,如图11(a)所示。这些知识不仅可以用来建议具有成本效益的驾驶路线,还可以用来识别油耗严重浪费的路段。同时,对车辆污染排放的即时估计可以启动污染警报,从长远来看,有助于诊断空气污染的根本原因。
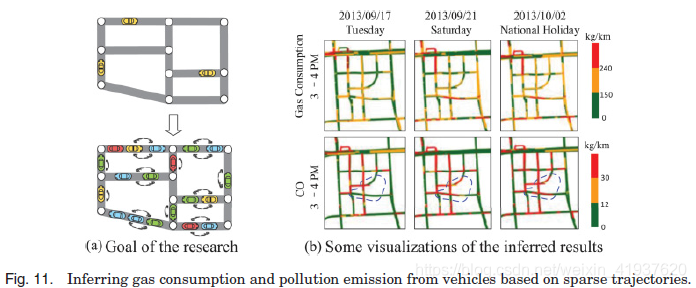
他们首先利用最近收到的GPS轨迹计算出每段道路的行驶速度。由于许多路段没有轨迹(即数据稀疏性),因此提出了一种基于上下文感知的矩阵分解方法的行驶速度估计模型。该模型利用从其他数据源(如地图数据和历史轨迹)学习到的特性来处理数据稀疏性问题。在此基础上,提出了一种交通量推断模型(Traffic Volume Inference model, TVI)来推断每分钟通过路段的车辆数量。TVI是一种无监督的动态贝叶斯网络,它包含了多种因素,如行驶速度、天气条件和道路的地理特征。给定路段的行驶速度和交通量,可以根据现有的环境理论计算油耗和排放量。
图11(b)展示了中关村这一多家公司和娱乐区的地区3天的燃气消耗和NOx排放情况。在下午3点到4点这段时间,也就是傍晚高峰前的时间,由于人们仍然在室内工作,这个地区在工作日的耗油量比周末和假日要少。当时间到了周末和节假日,很多人出于娱乐的目的(比如购物和看电影)去这个地区旅游,导致更多的能源消耗和CO的排放,用红色部分表示。有一个电影院,一个超市,两个购物中心位于以破曲线为标志的区域。
3.4.2. Electricity Consumption. 有效整合可再生能源,满足汽车和供暖电气化带来的需求增长,是实现电力供应可持续性、优化住宅能源使用的关键。需要有智能的需求响应机制来将能源使用转移到低需求时期或可再生能源的高可用性时期。智能算法,在设备级或社区/变压器级实现,使设备满足单个设备和用户的政策,并保持在社区指定的能源使用限制。
在Dusparic等人[2013]中,社区内的每辆电动汽车都由一个强化学习代理控制,并由短期负荷预测算法进一步支持[Marinescu等人2014]。每个代理的本地目标是最小化充电价格(这是动态的,与当前的能源需求成正比)和满足期望的用户效用(例如,在出发前将电动汽车电池充电80%)。每个代理也有一个目标,将社区变压器的水平保持在一个目标限制下(通过最小化,例如,在高峰期间充电的车辆数量)。如果实时监测显示实际需求与预测需求有偏差,则动态地重新预测需求。
galvani - lopez等人[2014]提出了一种替代方法,在该方法中,不是每个车辆代理自行决策,而是使用遗传算法进化出一个全局最优充电计划,并将其传达给电动汽车。在哈里斯et al。[2014],智能设定值控制算法在变压器发出信号控制设备(例如,EVs orwater加热器)表示一个概率他们应该使用以确定他们是否应该收费/在任何特定时刻或每个设备s变量的程度应该打开电源充电器。这使得对设备需求的细粒度控制能够填补无法控制的电力负载和目标变压器负载之间的空白,从而平滑总体能源需求。
Momtazpour等人[2013]提出了一个支持电动汽车充电和存储基础设施设计的框架。提出了一种协调聚类技术与城市环境网络模型协同工作,以帮助电动汽车部署场景下充电站的布置。问题考虑包括(1)预测电动汽车充电需求的基于业主活动,(2)电动汽车充电需求的预测在城市不同地区和可用的电动汽车电池,(3)设计的分布式机制管理电动汽车的运动不同的充电站,和(4)优化电动汽车的充电周期,以满足用户需求,同时汽车电网利润最大化。
3.5. Urban Computing for Social Applications
虽然互联网上已经有很多社交网络服务,但在本节中,我们将重点介绍基于位置的社交网络(LBSNs),其正式定义如下Zheng [2011a, 2012a]:
基于位置的社交网络(LBSN)不仅意味着位置添加到现有的社交网络,这样人们在社会结构可以分享location-embedded信息也由个体组成的新的社会结构的连接物理世界的相互依赖来自它们的位置以及他们location-tagged媒体内容,如照片、视频和文字。在这里,物理位置包括个人在给定时间戳的即时位置和个人在某一特定时期积累的位置历史。此外,相互依赖不仅包括两个人共同出现在同一物理位置或共享相似的位置历史,而且还包括从个人的位置(历史)和位置标记数据推断出的知识(例如,共同的兴趣、行为和活动)。
LBSNs弥合了数字世界和物理世界用户行为之间的鸿沟[Cranshaw 2010],这与城市计算的本质相吻合(见2.3节)。在基于位置的社交网络中,人们不仅可以跟踪和分享个人的位置相关信息,还可以利用从用户生成的和与位置相关的内容(如签到、GPS轨迹和地理标记的照片)中学习到的协作性社会知识[Zheng等人,2011c, 2012b]。LBSNs的例子包括广泛使用的Foursquare和研究原型GeoLife [Zheng等,2008c, 2008d, 2009a, 2010d]。通过LBSNs,我们可以了解用户和地点,并探索它们之间的关系:
1) Estimate user similarity: 一个人在现实世界中的定位历史在一定程度上暗示了他或她的兴趣和行为。因此,拥有相似地理位置经历的人很可能有共同的兴趣和行为。用户之间的相似性从他们所在的位置推断历史可以使朋友的建议(李等人。2008),连接用户有相似兴趣即使他们可能没有认识之前,和社区发现[Hung et al . 2009],识别一群人分享共同利益。为了更好地估计用户之间的相似度,郑等[2010d]考虑了更多的信息,如地点之间的访问序列、地点的地理空间粒度、地点的受欢迎程度等。此外,为了能够计算用户的相似度生活在不同的城市(例如,在用户位置历史)小地理空间重叠,肖et al .(2010、2012)扩展郑年代研究从物理位置的语义空间位置,考虑到类别的兴趣点位置由用户访问。
2) Finding local experts in a region [Zheng et al. 2009c]:有了用户位置,我们就能够确定那些比其他人更了解某个地区(或购物等主题)的本地专家。他们的旅行经历(例如,他们去过的地方)对旅游推荐更负责,也更有价值。例如,当地专家比一些游客更可能知道高质量的餐馆。
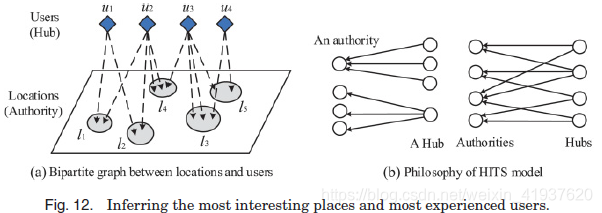
3) Location recommendations: 寻找城市中最有趣的地点是游客到陌生城市旅游时想要完成的一般任务[Zheng et al. 2009c]。然而,一个地方的兴趣水平不仅取决于去过这个地方的人的数量,还取决于这些人的旅游知识。例如,一个城市中最常去的地方可能是火车站或机场,这可能不是一个有趣的推荐地点。相反,一些地方吸引经验丰富的人(比如,有丰富的旅游知识)可能是真正有趣的。接下来的问题是如何确定个人的旅行经历。如图12(a)所示,Zheng等[2009c]建立了用户与地点的二部图,并采用基于HITS (hypertext-induced topic search)的模型来推断一个地点的兴趣水平和用户的旅行知识(如图12(b)所示)。其总体思路是,用户的旅游体验和一个地点的兴趣水平具有相互强化的关系。更具体地说,用户的知识可以用用户访问过的地点的兴趣总和来表示;一个位置的兴趣又由访问过该位置的用户的知识的总和来表示。
在某些场景中,我们可以考虑用户的偏好(例如,意大利食物和看电影)和背景(例如,当前地点和时间)来推荐地点[Ye et al. 2011; Liu et al. 2013]。一个简单的方法是建立一个用户位置矩阵,其中每一行表示一个用户,每一列表示一个位置,每一项表示特定用户在特定位置的访问次数。然后,可以使用一些协同过滤方法来填充没有值的条目。这种方法仅根据表示两个用户位置历史的两行来计算用户之间的相似性,但会遗漏有用的信息,例如前面提到的位置之间的访问序列。考虑到信息丰富,Zheng等[2010e]将他们在论文[Li等2008]中推断的用户相似度引入基于用户的CF模型中,推断出用户位置矩阵中缺失的值。该方法虽然对用户相似度有了更深入的了解,但由于模型需要计算每一对用户之间的相似度,因此存在用户规模不断扩大的问题。针对这一问题,Zheng等[2011d]提出了基于位置的协同过滤。该模型基于访问这些地点的用户的位置历史来计算地点之间的相关性[Zheng et al. 2009b]。然后,在基于项目的CF模型中,相关性被用作位置之间的相似性。考虑到有限的地理空间(即位置的数量有限),这种基于位置的模型更适用于真实的系统。
由于用户只能访问有限的地点,用户的位置矩阵非常稀疏,给传统的基于协同过滤的位置推荐系统带来了很大的挑战。当人们旅行到他们从未去过的新城市时,这个问题就变得更加具有挑战性。为此,Bao et al. [2012]提出了一种基于位置和偏好感知的推荐系统,提供了一个特定用户的场所(如餐馆和购物中心)在地理空间的范围内考虑到用户的个人偏好,它会自动从历史位置,和(2)的社会观点,采自当地专家的位置历史。这个推荐系统不仅可以方便人们在居住区域附近旅行,还可以方便人们前往新城市。
Itinerary planning行程规划:有时,用户需要一个复杂的旅行路线,以用户的旅行时间和出发地点为条件。行程不仅包括单独的地点,还包括连接这些地点的详细路线和适当的时间表,例如,大多数人到达地点的典型时间和游客应该在那里停留的适当时间长度。Yoon等人[2010,2011]根据从许多人的GPS轨迹中学到的集体知识,计划了一次旅行。Wei等人[2012]通过对许多签到数据的学习,了解了两个查询点之间最可能的路线。
Location–activity recommender:该推荐器向用户提供两种类型的推荐:(1)可以在给定位置执行的最受欢迎的活动;(2)进行给定活动(如购物)的最受欢迎的地点。这两类推荐可以从大量的用户轨迹和位置标记的评论中挖掘出来。为了实现这两个目标,Zheng等[2010f]提出了一种情境感知的协同过滤模型,该模型采用矩阵分解方法进行求解(详见4.4.2节)。
此外,Zheng等[2010a, 2012d]将位置活动矩阵扩展为一个张量,将用户视为第三维。通过应用上下文感知张量分解方法,提出了一个个性化的位置活动推荐(章节4.4.3提供细节)。
生活模式和风格的理解:社交媒体数据,尤其是事业部tweet,照片、签到,不仅可以帮助理解一个人的生活模式(你们et al . 2009),但也是一个城市动力学[Cranshaw 2012],主题(阴et al . 2011年)、行为模式(Wakamiya et al . 2012年),或生活方式(元et al . 2013年)使用时合计。我们也可以根据城市中产生的社交媒体来计算两个城市之间的相似度。
关于LBSNs的更多细节可以在Zheng [2011a, 2011e]和Bao等人[2014]关于LBSNs推荐的调查中找到。
3.6. Urban Computing for Economy
一个城市的动态(例如,人口流动和POI类别的变化次数)可能表明城市的经济趋势。例如,从2008年到2012年,北京的电影院数量持续增长,达到260家。这可能意味着住在北京的越来越多的人愿意去电影院看电影。相反,某一类POIs将在城市中消失,这表明该行业的低迷。同样地,人口流动可以表明一些主要城市的失业率,因此有助于预测股票市场的趋势。
人类的流动性与POIs相结合,也有助于一些企业的布局。Karamshuk等人[2013]研究了基于位置的社交网络背景下的最优零售商店放置问题。他们从Foursquare收集了人类移动数据,并对其进行了分析,以了解纽约三家零售连锁店的受欢迎程度在签到次数方面是如何形成的。我们评估了一组不同的数据挖掘特征,对周围地区的地点和用户移动模式的空间和语义信息进行建模。因此,在这些特征中,用户吸引物(如火车站或机场)的存在以及与目标连锁店相同类型的零售店(如咖啡店或餐馆)编码一个地区的本地商业竞争,是最强烈的受欢迎程度指标。
梳理更多的数据来源,我们甚至可以预测房地产的排名。Fu等人[2014]根据目前房地产周边观察到的各种数据来源,如人口流动数据、城市地理等,推断出住宅房地产的潜在价值,预测未来某城市住宅房地产的排名。在这里,价值意味着在上涨的市场中增长更快,在下跌的市场中下降更慢的能力,通过将其先前价格的上升或下降百分比离散化为五个水平(R1 R5), R1代表最好的,R5代表最坏的。
这个排名对于人们在安定下来或分配资本投资时是非常重要的。然而,这个问题很困难,因为排名取决于许多因素,这些因素在地理位置上呈非线性变化,甚至可能随时间而变化。为了解决这个问题,我们首先通过挖掘其周围的地理数据(如道路网络和POIs)和交通数据,为每个房屋识别一组区别特征。然后,我们训练一个成对学习到秩的模型,通过输入一系列的特征排序对到一个人工神经网络。
此外,本文还应用了一种度量学习算法来识别影响排名的前10个最具影响力的特征,含蓄地揭示了决定房地产价值的重要因素。
3.7. Urban Computing for Public Safety and Security
重大事件、疫情、重大事故、环境灾害、恐怖袭击等对社会治安秩序构成额外威胁。各种各样的城市数据的广泛可用,一方面使我们能够从历史中学到如何正确地处理上述威胁,另一方面使我们能够及时发现它们,甚至提前预测它们。
3.7.1. Detecting Traffic Anomalies. 城市地区的交通异常可能由事故、交通管制、抗议、体育、庆祝活动、灾难和其他事件引起。交通异常的检测有助于驱散拥堵,诊断突发事件,方便人们驾驶。根据对异常检测的调查[Chandola 2009;
Hodge 2004[,有四大类的方法:基于分类,基于聚类,基于距离,和基于统计。
在本文中,我们只介绍后两类在城市交通设置。
(1) Distance-based methods: 这类方法通过一组特征(从交通数据中提取)来表示一个空间对象(如区域、道路段或连接两个区域的链接),然后使用这些特征来计算两个空间对象之间的距离。距离其他物体较远的空间物体被认为是离群值。
一些阈值,如三倍的标准偏差,通常被用来识别异常值。
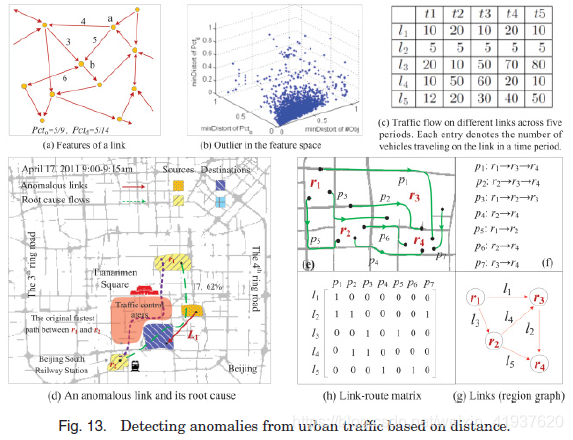
Liu等[2011]将城市划分为有主干道的互不连通区域,并根据两个区域之间行驶的车辆流量收集两个区域之间的异常连接。他们将时间分成时间垃圾箱和确定为每个链接三个特性,包括出行的车辆数量的链接在本(# Obj),这些车辆的比例在所有车辆进入目标区域(Pctd),移动的起源地区(Pcto)。如图13(a)所示,对于链路a→b, #Obj = 5, Pctd = 5/14, Pcto = 5/9。将一个时间箱的三个特征分别与前几天的等效时间箱中的特征进行比较,计算每个特征的最小失真(即mindistortion #Obj, mindistortion Pctd, mindistortion Pcto)。然后,时间库的链接可以在一个三维空间中表示,每个维度表示特征的最小扭曲,如图13(b)所示。为了使不同方向的方差效应标准化,我们使用马氏距离来测量最极端的点,这些点被视为异常值。
在上述研究的基础上,Sanjay等[2012]提出了两步挖掘优化框架,用于检测两个区域之间的交通异常,并通过两个区域的交通流解释异常。如图13(d)所示,在两个区域之间发现一条异常链路L1。然而,问题可能不在这两个地区。2011年4月17日,由于北京马拉松比赛,北京的交通已经从天安门广场改道。因此,将r1区域到r2区域北京南站的正常交通路线(虚线路径)改道,虚线(绿色)路径出现超车现象。总之,绿道上的车流导致了异常。在该方法中,给定如图13(c)所示的链接矩阵,他们首先使用PCA(主成分分析)算法检测一些异常链接,这些异常链接用列向量b表示,1表示在链接上检测到异常。根据车辆轨迹,建立相邻路段路径矩阵a,如图13(d) ~ 13(g)所示。矩阵中的每一项都表示路由是否通过了一个链接;
1意味着是的;0表示没有。例如,p1经过l1和l2。然后,通过求解方程Ax = b,得到异常链路与路由的关系,其中x为列向量,表示哪些路径导致了异常突发,如b所示。利用L1优化技术,可以推断出x。
Pan等人[2013]根据城市道路网络上的司机路由行为识别交通异常。在这里,检测到的异常由道路网络的子图表示,其中司机的路由行为与他们的原始模式显著不同。然后,他们试图通过从异常发生时人们发布的社交媒体上挖掘代表性词汇来描述检测到的异常。检测此类交通异常情况的系统可以让司机和运输部门都受益,例如,它可以通知司机接近异常情况,并建议替代路线,还可以支持交通堵塞的诊断和疏导。
2) Statistical-based methods: 基于统计的离群值检测技术的基本原理是异常是一种被怀疑部分或完全无关的观察结果,因为它不是由所假设的随机模型产生的[Anscombe和Guttman 1960]。它基于一个关键的假设:正常的数据实例发生在随机模型的高概率区域,而异常发生在随机模型的低概率区域。统计技术将一个统计模型(通常用于正常行为)适合于给定的数据,然后应用一个统计推断测试来确定一个看不见的实例是否属于这个模型。应用测试统计数据中概率较低的实例被声明为离群值。
Pang等人[2011,2013]采用了之前主要用于流行病学研究的似然比检验(LRT)来描述交通模式。他们把城市划分成统一的网格,并计算一段时间内在网格中到达的车辆数量。目标是识别连续的单元组和时间间隔,这些单元组与预期行为(即车辆数量)在统计上有最大的显著偏离。对数似然比统计值在χ2分布尾部下降的区域可能是异常的。
3.7.2. Disaster Detection and Evacuation. 日本东部大地震和福岛核事故造成了大规模的人口迁移和疏散。理解和预测这些迁移对于规划有效的人道主义救援、灾害管理和长期社会重建至关重要。Lee和Sumiya[2010]的目标是从地理标记的推特数据中检测诸如环境灾害等事件。Song等人[2013]构建了一个大型的人类移动数据库,该数据库存储了2010年8月1日至2011年7月31日期间日本各地大约160万人使用的移动设备的GPS记录。通过对数据集的挖掘,发现了个体在此次灾难中短期和长期的疏散行为。根据所发现的疏散情况,建立概率模型,并应用于其他城市受灾害影响的人口流动情况。本研究可为未来灾害救援与管理决策提供参考。
4. TYPICAL TECHNOLOGY
在本节中,我们将讨论城市计算中常用的五类技术:(1)城市感知,(2)城市数据管理,(3)异构数据的知识融合,(4)数据稀疏处理,以及(5)城市数据可视化。
4.1. Urban Sensing and Data Acquisition
传感和数据采集技术的进步为我们的城市带来了大量数据,从交通流量到空气质量,从社交媒体到地理数据。在这里,我们将现有的城市计算数据采集技术分为三部分:(1)传统的传感和测量,(2)被动人群感知,(3)参与式感知[Goldman et al. 2009],这将在后面的章节中详细介绍。
第一种技术是通过安装专用于某些应用的传感器来收集数据,例如,在道路上埋设环路传感器,以检测道路表面的交通量。第二种技术利用现有的基础设施被动地收集人群产生的数据。例如,无线蜂窝网络是为个人之间的移动通信而建立的。然而,很多人的手机信号可以用来预测交通状况,改善城市规划。第三,人们主动获取周围的信息,贡献自己的数据,形成能够解决问题的集体知识,简而言之,人类作为传感器。有代表性的例子包括通过收集大量的人的报告来检测交通拥堵,以及使用单个移动电话共享的数据来探测整个城市的温度。后两种技术的主要区别在于,人们知道自己贡献了什么,以及第三类共享的目的是什么(即主动与被动)。由于第一种技术已经得到了广泛的应用,我们在本节重点介绍后两种技术。
4.1.1. Passive Crowd Sensing. 为了使我们的现代生活成为可能,许多先进的基础设施已经在城市中建立起来(例如,公共交通的票务系统和无线蜂窝网络)。
虽然这些基础设施是为其他目的而设计的,但它们也可以用来感知城市动态。
这些基础设施产生的数据也可以用于分析以实现其他目标,如改善城市规划和缓解交通拥堵。
- Sensing City Dynamics with GPS-Equipped Vehicles 通过配备gps的车辆来感知城市动态:近年来,由于不同的原因(安全、管理、调度、保险测量),出租车、公交车、私家车等车辆都安装了GPS传感器。GPS传感器和通信模块使这些车辆能够报告其当前位置以及后端中心在特定时期内的其他信息。事实上,这些装有gps的车辆可以被视为移动传感器,不断探测道路表面的交通流量。在这些基础设施中获得的数据也代表了城市范围内的人类移动模式(例如,如果我们知道每个出租车行程的上客点和落客点)。通过获取出租车行驶轨迹数据,开展了一系列研究,如智能驾驶方向服务[Yuan and Zheng et al. 2010a, 2011b, 2013b],实时感知油耗[Zhang et al. 2013],以及某城市异常检测[Liu et al. 2011;舒拉等人2012年;Pan等人,2013;
庞等。2011,2013[。配备gps的巴士在现代城市也很普遍,主要用于预测巴士到站的时间。这些公交的GPS轨迹也被应用于交通状况分析[Bejan 2010]和公交路线优化[Bastani et al. 2011]。一些私人车辆也被保险公司嵌入了GPS传感器。生成的数据,包括GPS坐标和其他驾驶行为,被用来衡量可能发生在司机身上的车祸风险,从而确定司机的保险套餐。这些数据还可以用于分析不同路线的汽油成本,并教育驾驶员的生态驾驶行为。 - Data Acquisition Through Ticketing Systems of Public Transportation通过公共交通票务系统进行数据采集: 在地铁和公共汽车等公共交通系统中,各种基于rfid的卡被用于对人们的通勤收费。人们通常需要在进入地铁站或上公共汽车时刷卡。有时,他们还需要在出口或下车时刷卡。交易记录包括所付的钱、时间戳和位置信息,这些信息可能是一个车站、一个码头和一个公交站,或者只是一个公交ID。如果处理正确,可以从交易记录推断出每个持卡人的来源和目的地。因此,我们可以模拟城市范围内的人类流动[Lathia和Capra 2011a, 2011b]。
- Data Acquisition Through Wireless Communication Systems通过无线通信系统进行数据采集: 无线通信系统(如蜂窝网络和Wi-Fi)已在城市中广泛部署。记录人们访问这些无线网络的信息实际上是另一种足迹。例如,话单已被广泛应用于交通和人类移动建模[gonzalez alez et . 2008;Candia等[2012]。Jiang等人[2013]对移动电话轨迹的城市计算进行了综述。
- Data Acquisition Through Social Networking Services通过社交网络服务获取数据:在线社交网络服务的进步导致了大量的社交媒体,如推特、照片和视频。有时,社交媒体甚至与地点信息相关联(例如,地点签到或带有地理标签的照片)。用户发布的社交媒体可能会描述他们周围发生的事件,比如自然灾害或车祸。对大量用户生成的社交媒体进行实时分析,有助于发现城市中发生的异常事件。地理标记的社交媒体也可以反映城市空间中的人类移动模式,从而实现一些有用的应用,如旅行建议[Wei et al. 2012;Bao等,2012, 2014; Yoon等人 2010年,2011年]和商业地点选择[Karamshuk等人2012年]。
4.1.2. Participatory Sensing. 由于强大的网络化(即可上网的)手持设备的广泛采用,市民现在在生成城市数据方面扮演着更加积极的角色。这一趋势使得一种新的应用程序浮出水面,参与者收集我们城市的信息,并共同用于为市民提供服务。在参与式感知的主题下,我们确定了两个主要的工作流:人类众包和人类众包。
- Human crowdsensing已被称作人类群体感知:在这个术语中,我们指的是用户自愿提供从嵌入在用户自己设备中的传感器收集到的信息的情况。例如,这可以是来自用户手机的GPS数据,正如提拉米苏项目(Zimmerman et al. 2011)所探索的那样,然后用于估算实时的公交到达。来自用户个人设备的GPS数据也被用于交通和导航应用程序,如Waze。在这两种情况下,用户只需在乘坐公共汽车/汽车时启动应用程序;在没有任何额外负担的情况下,手机上打开的应用程序被动地提供GPS数据,然后根据应用程序特定的目标(例如,为其他用户提供实时的巴士到达,路由计算)聚合和分析这些数据。GPS数据只是一个例子:用户一直愿意贡献噪音数据,通过手机麦克风和GPS位置来创建城市噪音地图[D Hondt et al. 2011;Rana等,2010,2013[。使用像SmartCitizen这样的个人传感套件对环境数据进行传感和绘图也得到了发展势头:这些设备可以感知空气质量、温度、声音、湿度、光线、二氧化碳和NO2。它们的价格低廉到私人所有的程度,从而为在城市地区拥有成百上千个这样的设备铺平了道路,有可能为我们的城市的宜居性提供非常细粒度的时空足迹。由于人类收集的数据与携带设备的人所处的位置有着内在的联系,因此需要进行研究来量化数据中的偏差,以明确收集的数据在多大程度上代表了实际的环境条件[Mashhadi等人2013]。
Human crowdsourcing人类的众包: 在这个术语中,我们指的是用户主动参与生成数据的行为,而不是简单地打开/关闭应用程序或设备。例如,用户生成关于事故、警察陷阱或任何其他道路危险的报告,以提醒该地区的其他用户(Waze为用户提供了在感知到的GPS数据基础上获取丰富信息的能力,Waze已经从用户的移动设备中追踪到这些数据);骑自行车者对自行车友好型路线进行注释,并报告可能影响其他骑行者的坑洼和其他类型的问题[Priedhorsky等人2010];市民变成地图绘图师,为他们的城市绘制公开地图(Haklay和Weber 2008),或测量师报告当地影响的问题,以便议会采取行动。所有这些情况下所需的认知努力都比人类群体感知要高得多,因此导致了用户动机和长期参与方面的开放研究问题,而这些问题刚刚开始被探索[Hristova et al. 2013;Panciera等,2010[。
4.2. Urban Data Management Techniques
城市空间产生的数据通常与空间或时空属性有关。例如,道路网络和POIs是城市空间中常用的空间数据;气象数据、监控视频和用电量都是时间数据(也称为时间序列或流)。其他数据来源,如交通流量和人的流动性,同时具有时空属性。有时,时间数据也可以与一个位置相关联,然后成为一种时空数据(例如,一个地区的温度和建筑的电力消耗)。因此,良好的城市数据管理技术应该能够有效地处理空间和时空数据。
此外,城市计算系统通常需要利用各种异构数据。在许多情况下,这些系统需要快速回答用户的即时查询(例如,预测交通状况和预测空气污染)。如果没有可以组织多个异构数据源的数据管理技术,下面的数据挖掘过程就不可能快速地从这些数据源中学习知识。例如,如果没有一个有效的时空索引结构,能够提前很好地组织POIs、道路网络、交通和人类移动数据,U-Air项目的唯一特征提取过程[Zheng等。2013b]将持续几个小时。这个每小时向人们报告一个城市空气质量的申请将会失败。
本节介绍在城市计算应用中广泛使用的三种常见数据结构(即流数据、轨迹数据和图形数据),以及管理这三种数据结构的技术。我们还提供了一些将不同数据源集成到混合索引中的示例。
4.2.1. Stream and Trajectory Data Management. 流数据,如温度、用电量和监控摄像头的视频,在城市空间中随处可见。流数据的管理和查询在过去的十年中得到了深入的研究[Aggarwal 2007;Lukasz 2010年的数据流管理系统DSMSs)。数据管理系统是管理连续数据流的计算机程序,类似于数据库管理系统(DBMS),不过,后者是为传统数据库中的静态数据而设计的。与DBMS不同,DSMS执行一个连续的查询,只要有新数据到达系统,就会产生新的结果。查询的示例包括计算用电量超过阈值的建筑物的平均温度。对于DSMS来说,最大的挑战之一是使用固定数量的内存处理可能无限的数据流,并且不对数据进行随机访问。有两类方法可以限制一次传递的数据量。一种是试图总结数据的压缩技术;
另一种是窗口技术,它试图将数据分割成(有限的)部分。
空间轨迹的跟踪移动物体所产生的地理空间,通常由一系列的顺序有序点,例如,p1→ p2 →...→pn,每个点由一组地理空间坐标和时间戳等p = (x, y, t)中生成的各种数据就可以形成城市空间轨迹,从GPS车辆用户年代足迹的痕迹(如签到)在基于位置的社交网络,从手机的通话细节记录到信用卡的交易记录。轨迹数据虽然可以看作是流数据的一种特殊情况,但每一项数据的地理位置都有影响,并带来了许多新问题,需要新技术(详见Zheng [2011f]):
1) Data reduction techniques for trajectories: 一般来说,物体的连续运动被近似地记录为定位点的离散样本。定位点的高采样率会产生精确的轨迹,但会产生大量的数据,从而导致数据存储、通信和处理方面的巨大开销。因此,设计数据缩减技术是至关重要的,既要压缩轨迹的大小,又要保持轨迹的实用性。有两种主要类型的数据缩减技术,在数据收集后以批处理模式运行(如Douglas-Peucker算法[Douglas and Peucker 1973]),或在数据收集时以在线模式运行(如滑动窗口算法[Keogh等人2001;Maratnia 2004])。为了评估一种轨迹缩减技术,我们通常考虑以下三个指标:处理时间、压缩率和误差测量(即近似轨迹与原始呈现的偏差)。最近的研究,出版社[Song et al. 2014]给出了道路网络轨迹减少的解决方案。PRESS将轨迹的空间表示与时间表示分离,提出了混合空间压缩算法和有误差时间压缩算法,分别对轨迹的空间信息和时间信息进行压缩。
为了评估一种轨迹缩减技术,我们通常考虑以下三个指标:处理时间、压缩率和误差测量(即近似轨迹与原始呈现的偏差)。最近的研究,出版社[Song et al. 2014]给出了道路网络轨迹减少的解决方案。PRESS将轨迹的空间表示与时间表示分离,提出了混合空间压缩算法和有误差时间压缩算法,分别对轨迹的空间信息和时间信息进行压缩。当浏览用户共享的轨迹(可能是站在一条旅行路线上)时,用户停留的地方、拍照的地点、移动方向的显著改变等等,在呈现轨迹的语义意义上比其他点更重要。因此,在这种轨迹共享系统中,具有重要语义意义的GPS点在为简化轨迹选择代表性点时应赋予更高的权重。
2) Noise filtering techniques for trajectories:由于定位系统的信号较差,产生的轨迹中往往会有偶尔的离群点或一些噪声点。因此,在对空间轨迹进行预处理时,需要对噪声点进行滤波。常用的方法有均值和中值滤波、卡尔曼滤波和粒子滤波。详见[Zheng and Zhou 2011f]一书第一章。
3) Techniques for indexing and query trajectories:在移动对象数据库中,查询移动对象的当前位置已经得到了广泛的研究。常用的技术有3DR-Tree [Theodoridis et al. 1996]和MR-Tree [Xu et al. 1999]。有时候我们需要寻找历史轨迹满足一定的标准,例如,检索游客通过给定地区的轨迹和时间跨度内(例如,一个时空范围查询[王、郑et al . 2008]),出租车轨迹,通过一个十字路口(即,点查询),或类似的轨迹查询轨迹(陈et al . 2010;Tang等[2011](即轨迹查询)。更多技巧见Zheng [2011f]的第二章。
4) Techniques dealing with uncertainty of a trajectory: 定位设备本质上是不精确的,导致一些关于获得的移动对象的位置的不确定性。而且,物体是连续移动的,而它们的位置只能在离散的时间内更新。为了节省能源消耗和通信带宽,两次更新之间的时间间隔可能超过几分钟或几小时,使得两次更新之间移动对象的位置不确定。例如,如图14(a)所示,一辆装有gps的出租车的两个采样点之间的时间间隔可能是几分钟,因此有多个可能的路径经过三个采样点。
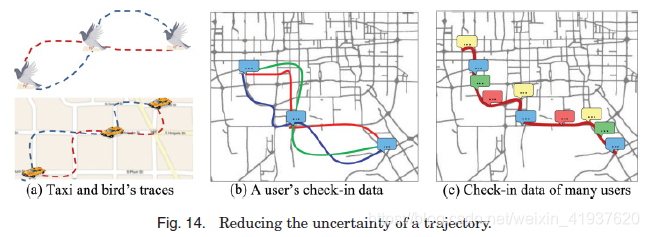
地图匹配是根据采样的轨迹推断出运动物体(如车辆)在路网中走过的路径。处理高采样率轨迹的地图匹配技术已经在个人导航设备中商业化,而那些处理低采样率轨迹的地图匹配技术(Lou et al. 2009)仍然被认为具有挑战性。Yuan等人[2010b]的研究结果表明,给定采样率为每点2分钟左右的轨迹,地图匹配算法的最高精度约为70%。
当连续采样点之间的时间间隔变得更长的时候(例如,用户连续两次签到之间的时间间隔可能是几个小时,而鸟类的跟踪时间间隔可能是1天),现有的地图匹配算法就不能很好地工作了。为了解决这个问题,Wei等人[2012]提出了基于许多不确定轨迹,通过几个采样点来构建最有可能的路径。例如,如图14(c)所示,如果我们将许多用户的签入数据放在一起,如图14(b)所示的不确定路径可能变成确定,即不确定+不确定→确定。
研究的另一个分支是基于部分轨迹预测用户的目的地[Krumm et al. 2006;
Xue等人2013年[。在这种情况下,用户的目的地在一开始是不确定的,当旅程完成后,目的地逐渐变得确定。用户和其他人的历史轨迹以及其他信息,如一个地点的土地使用情况,都可以用于目的地预测模型。
5) Trajectory pattern mining:研究的一个分支是从轨迹中寻找顺序的模式。
这里,顺序模式是指一定数量的移动物体在相似的时间内以相同的顺序在相同的地点移动。此外,旅行序列中的位置不必是连续的。
例如,两条轨迹A和B,![]() 共享一个公共序列l1 l2 l4,因为访问顺序和旅行时间是相似的(尽管l2和l4在轨迹a上不是连续的)。这不同于最长公共子序列问题(LCSS)由于时间维度的原因。Giannotti等人[2007]是第一个针对这一问题的研究。Xiao等[2010,2012]提出了一种基于图的序列匹配算法,用于寻找两个用户轨迹共享的序列模式。然后使用序列模式来估计两个用户之间的相似度。
共享一个公共序列l1 l2 l4,因为访问顺序和旅行时间是相似的(尽管l2和l4在轨迹a上不是连续的)。这不同于最长公共子序列问题(LCSS)由于时间维度的原因。Giannotti等人[2007]是第一个针对这一问题的研究。Xiao等[2010,2012]提出了一种基于图的序列匹配算法,用于寻找两个用户轨迹共享的序列模式。然后使用序列模式来估计两个用户之间的相似度。
研究的另一个分支是发现一群一起移动的对象,在一定时间内,如羊群Gudmundsson et al . 2004年,2006年,车队(Jeung et al . 2008 a, 2008 b),群[李et al . 2010],旅伴(唐et al . 2012年,2013年),和采集(郑et al . 2013 b, 2014)。这些概念,我们称之为组模式,可以根据如何定义组以及它们是否要求时间段连续来区分。具体地说,flock是一组在用户指定大小的磁盘内一起移动的对象,至少有k个连续时间戳。一个主要的缺点是圆形的形状可能不能反映现实中的自然群体,这可能会导致所谓的有损羊群问题[Jeung et al. 2008a]。为了避免对队列模式大小和形状的严格限制,提出利用基于密度的聚类方法捕获任意形状和范围的通用轨迹模式。与使用磁盘不同的是,护航需要在k个连续时间点内将一组物体紧密连接在一起。尽管flock和convoy都对连续的时间段有严格的要求,但是Li等人[2010]提出了一种更一般的轨迹模式swarm,它是一个持续至少k个(可能是非连续的)时间戳的物体群。与flock、convoy和swarm不同的是,群体模式需要在其生命周期内包含同一组个体,而聚集模式允许成员在任何时间进入和离开这个群体,只要一定数量的成员能够停留一段时间。这是比较现实的,因为不同的人可能会经常参加和离开一个活动,在一个实际的团体活动,如商业推广。
4.2.2. Graph Data Management. 图是另一种常用来表示城市数据的数据格式,如道路网络、地铁系统、社交网络和传感器网络。静态图数据管理[Angles and Gutierrez 2008]已经在数据库领域进行了多年的深入研究,有许多成熟的管理系统可用。在城市计算中,图形通常与空间属性相关联,从而产生了许多空间图形。例如,路网的节点有一个空间坐标,道路段的每条边都有一个空间长度。在许多情况下,这些空间图也包含时间信息。例如,道路段的交通量随着时间的变化而变化,两个地标之间的旅行时间也随时间而变化(如图6(a))。这种图表的结构也可能随着时间的推移而改变。例如,一个交通控制可能阻塞两个地点之间的交通流,因此暂时删除两个地点之间的边缘。我们称这种图为时空图(ST graph) [Hong and Zheng et al. 2014]。与时间演进图不同的是,时间演进图通常用来表示一个结构和属性也会随着时间变化的社会网络,ST图中每个节点都有一个空间位置,从而导致图中的两个节点之间存在空间距离。ST图可以通过将动态流量数据投影到空间图上生成(例如,将车辆的GPS轨迹或手机用户的通话细节记录投影到道路网络上)。时空图的其他例子包括传感器网络、基于位置的社交网络和车辆对车辆网络,其中节点的位置(如用户或车辆)可以随时间变化。
而有效地管理时空图是非常重要的支持在城市计算的知识发现过程,相应的数据管理技术在某种程度上失踪,有待探索(例如,一个圣图寻找一些交通总量高于阈值的子图,或不断寻找top-k集群的空间与相对频繁密切节点彼此之间的交流在一个圣图)。对于那些对图形数据和空间数据管理感兴趣的研究人员来说,这可能是一个好消息。现有研究主要集中在时空图上的子图模式挖掘[Zheng等,2011b]和时间相关路由[Yuan等,2010a]。例如,根据人类移动数据收集城市道路网络中存在问题的设计的例子(在第3.1.1节中)被表述为时空图上的子图模式挖掘问题。最近的研究[Hong and Zheng et al. 2014]已经开始从时空图上检测一些黑洞(或火山),它们代表的交通流流入的区域要比流出的区域大得多。Sun等人[2014]旨在回答基于位置的社交网络中的一个时空聚合查询。示例查询包括查找用户周围在过去3个月最受欢迎的k个旅游景点。
4.2.3. Hybrid Indexing Structures. 在城市计算场景中,我们通常需要利用各种数据并将它们集成到数据挖掘模型中(请参阅下一节了解详细信息)。这就需要能够很好地组织不同数据源的混合索引结构。
例如,在许多应用中[Zheng et al. 2013b;Yuan等人,2012a],我们需要同时使用POIs、道路网络、交通和人类移动数据。图15展示了一个混合索引结构,它结合了空间索引、哈希表、排序列表和邻接列表。具体地说,就是利用基于四叉树的空间索引对城市进行网格划分。空间索引的每个叶节点(网格)维护两个列表,存储属于该节点空间范围的POIs和道路段(仅存储ID)。此外,每个道路段ID指向两个排序列表。一种是一份出租车id列表,它是按照到达该路段的时间排序的。
通常,我们只需要存储最近几个小时内穿过道路段的出租车的ID。因此,排序列表在这里很好。当需要存储的时间很长时,可以使用基于b树的时间索引来管理出租车的ID。另一份是按取客时间(tp)和取客时间(td)排序的乘客落客点列表。最近几个小时生成的出租车轨迹点可以保存在存储在内存中的列表中,而历史轨迹点则存储在硬盘上。给定出租车的ID,我们可以通过哈希表检索出租车的轨迹。
道路网络的结构由图15右上方的邻接表表示。我们也可以使用哈希表来检索它所属路网中某个路段的邻居。
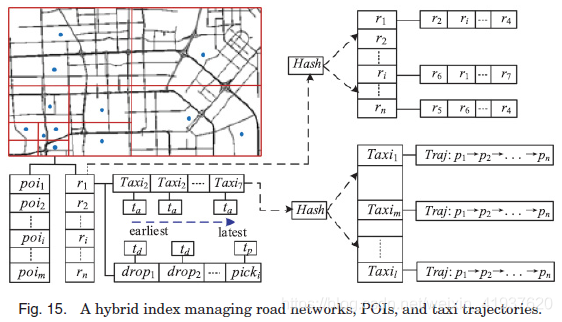
以空气质量研究[Zheng et al. 2013b]为例,我们描述了如何使用混合索引结构。
目标是从属于该区域的不同数据源中提取出给定地理区域的四类特征(POI、道路网络、交通和人类移动特征)。给定一个地理区域,我们首先从基于四叉树的空间索引中检索落在该区域内的叶节点。通过分别查看这些叶子节点上的POI和道路网络列表,我们可以快速提取POI特征和道路网络特征(如POI在不同类别上的分布以及区域内公路总长度的下降)。如果需要计算一个区域内的道路交叉口数量,则通过哈希表访问邻接表。由于一个道路段可以跨越几个区域,最优的解决方案是在检查邻接表之前,将从不同叶节点检索到的道路段id进行合并。将GPS轨迹投影到路网上的地图匹配[Yuan等。2010b]需要同时访问四叉树空间索引和邻接表。地图匹配后,我们可以更新相应路段的的士名单和落客名单。然后,根据出租车穿越该路段的轨迹计算出各路段的行驶速度。与检查道路段相似,我们可以在访问轨迹列表之前合并来自不同叶节点的出租车id。我们也可以计算进入和离开一个区域的人数根据落客/取客名单。这里介绍的索引结构只是一个示例,可能不是最优的。
4.3. Knowledge Fusion across Heterogeneous Data Sources
在城市计算场景中,我们通常需要利用各种数据源,这就需要能够有效融合从多个异构数据源中学习到的知识的技术。实现这一目标的主要方法有三种:(1)在特征层次上融合不同的数据源,即平等对待不同的数据源,将从不同数据源中提取的特征组合成一个特征向量。当然,在将该特征向量导入数据分析模型之前,应该对其应用某种规范化技术。这是我们在处理异构数据源的数据科学中看到的最常见的方法。(2)在不同阶段使用不同的数据。例如,Zheng等人[2011b]首先通过主要道路将城市划分为不连贯的区域,然后利用人的移动数据来收集城市交通网络存在问题的配置。当人们思考数据融合时,这也是一种非常自然的方式。(3)同时向模型的不同部分输入不同的数据集。这是基于对数据源和算法的深入理解。根据研究[Zheng et al. 2013b;Yuan et al. 2012a],第三类数据融合方法通常比第一类数据融合方法性能更好,第二类数据融合方法可以与第一类和第三类数据融合方法同时使用。由于第一类和第二类是很直观的,并且在文献中已经被广泛讨论过,所以在本节中我们仅通过三个具体的例子来介绍最后一类。
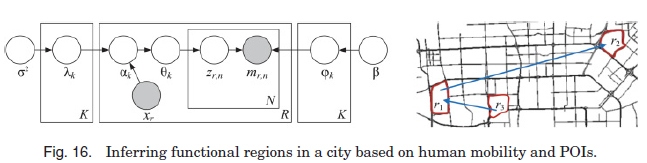
例1. 第一个例子是我们在3.1.2节中简要介绍的,Yuan等人[2012a]利用道路网络数据、兴趣点和从大量出租车出行中了解到的人类流动性,推断出城市的功能区域。如图16所示,提出了一个基于lda变异的推理模型,将区域视为文档,将功能视为主题,将poi类别(例如,餐馆和购物中心)视为元数据(如作者、关联和关键字),将人类移动模式视为词汇。具体来说,如图16右图所示,个体在t点离开区域r,在t点到达区域rz,形成一种交换模式![]() 。同样地,另外三个人分别生成了另一个交换模式
。同样地,另外三个人分别生成了另一个交换模式![]() , t'>。流动模式被定义为不同地区之间的通勤模式——人们离开一个地区时,他们要去哪里;人们到达一个地区时,他们从哪里来。每个通勤模式代表一个描述区域的单词,而通勤模式的频率表示一个单词在文档中出现的次数。在这个例子中,区域r1包含两个单词
, t'>。流动模式被定义为不同地区之间的通勤模式——人们离开一个地区时,他们要去哪里;人们到达一个地区时,他们从哪里来。每个通勤模式代表一个描述区域的单词,而通勤模式的频率表示一个单词在文档中出现的次数。在这个例子中,区域r1包含两个单词![]() 和
和![]() 。这两个词出现的次数分别是1和3。
。这两个词出现的次数分别是1和3。
通过将POIs(表示为xr)和人类移动模式(表示为mr,n)输入该模型的不同部分,一个区域由函数分布表示,每一个函数分布进一步表示为移动模式分布。N为字数(即区域内的迁移模式);R为文件数(区域);K是主题的数量,应该是预定义的。在运行该模型之前,一个城市被划分为脱节的区域使用主要道路,如高速公路和环路。
因此,本例使用了第三类数据融合技术,并结合了第二类。
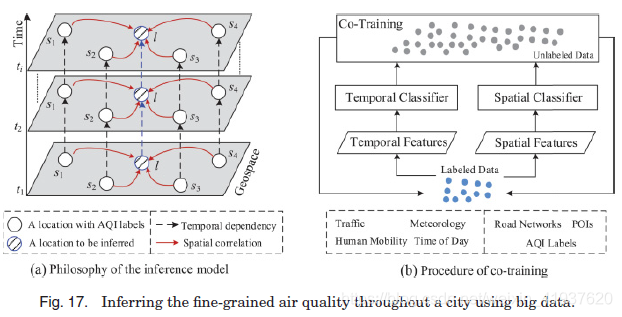
例2. 第二个例子在3.3.2节中介绍,这是关于利用大数据对城市空气质量的推断。
如图17所示(一个),空气质量具有时间依赖性在单个位置(例如,空气质量指数的位置往往是好的如果空气质量指数过去一小时也是好的)和空间相关性在不同的位置(例如,一个地方的空气质量可能不好如果周边地区的空气质量是坏的)。摘要提出了一种半监督学习方法来预测一个没有监测站的地点的空气质量,该方法基于一个由两个分类器组成的协同训练框架。一种是基于人工神经网络(ANN)的空间分类器,它以空间相关特征(如POIs的密度和公路的长度)为输入,来建模不同位置空气质量的空间相关性。另一种是基于线性链条件随机场(CRF)的时间分类器,该分类器涉及时间相关特征(如交通和气象),以模拟一个地点的空气质量的时间依赖性。这两个分类器在协同训练框架下相互加强。结果表明,该算法在线性/高斯插值、经典色散模型、决策树和CRF等知名分类模型以及ann等四类基线之外具有优势。
他们这样融合数据的原因有三个方面:(1)基于协同训练的框架通过利用未标记的数据来处理数据稀疏性。虽然有大量的观测数据,如交通流量,但现有监测站生成的标记数据非常有限(即标记稀疏问题)。(2)恰好有两组特征为一个实例提供了两种不同的视图(即,一个地点的空气质量)。如果简单地将空间相关特征(如路网结构)与时间相关特征(如气象、交通流)的值随时间不断变化放在一起,空间相关特征会被一些机器学习模型忽略。也就是说,无论某个地方的空气质量如何,这些与空间相关的特征都不会随着时间的推移而改变。(3)两个分类器分别对空间相关性和时间依赖性进行了建模,具有可解释性。
例3. 这个例子在第3.4节中作为一个关于能源消耗的应用提到过。具体地说,一辆出租车年代加油事件被检测到的GPS轨迹,使用第一个时空聚类算法确定出租车的地方呆了一段时间,然后分类算法来过滤某些情况下可能不真实加油事件,如等待红绿灯接近一个加油站。如果可以从数据中检测到加油站的排队时间,则可以根据经典排队理论计算出排队车辆的数量。因此,假设每辆车加油所用的汽油量按照一定的分布,就可以粗略估计油耗。然而,在某些时候,许多加油站可能没有出租车在排队等候(但会有其他车辆),从而导致数据丢失的问题。此外,加油站出租车的分布可能会偏离正常车辆的分布。在车站看到更多的出租车(或更少的出租车)并不意味着有更多的普通车辆(或更少的普通车辆)。
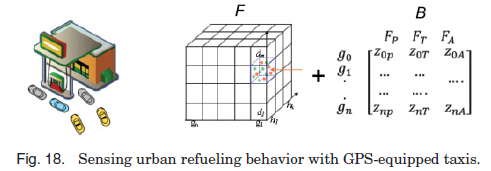
为了解决这个问题,如图18所示,张量F的三个维度分别表示加油站、星期几和一天中的时间。考虑到张量非常稀疏,我们应用了张量分解技术,通过三个低秩矩阵和一个核心张量的乘法来近似张量。为了达到一个更好的近似,一个特征矩阵B也建立了基于三个其他数据源,包括POIs以及交通流在一个车站的地理空间大小车站,每一行代表一个加油站,每一列代表一个功能。一般的想法是,具有相似特征的加油站(如周围的交通模式、POI分布和道路网络结构)可能有类似的加油模式。由于特征矩阵比较密集(不是稀疏),我们可以通过将矩阵纳入张量分解的过程来提高张量中缺失值的估计精度。请注意,出租车的数量并不是用来推断正常车辆的数量的。相反,利用可转移的出租车等待时间来估计排队长度。
这是一个使用异构数据源进行计算的明显例子,这些数据源包括POIs、道路网络、加油站布局和出租车的GPS轨迹,其中前三个数据源被输入到一个特征矩阵,最后一个用于建立一个张量。矩阵和张量混合在基于张量分解的协同过滤模型中(关于分解技术的更多细节请参见4.4.3节)。
4.4. Techniques Dealing with Data Sparsity
导致数据丢失问题的原因有很多。例如,在基于位置的社交网络服务中,用户只会在几个地点签到,而有些地点可能根本没有人访问它们。如果我们将用户位置放入一个矩阵中,每个条目表示用户访问一个地方的次数,这个矩阵是非常稀疏的;也就是说,许多条目没有值。如果我们进一步考虑用户可以在一个位置执行的活动(比如购物、吃饭和运动),就可以得出一个张量。当然,张量更稀疏。类似地,在4.3节中提到的应用程序中,示例3中,许多加油站在某些时刻并没有真正的出租车在排队等候。因此,图18中显示的张量也是稀疏的。在4.3节中介绍的应用程序,例2也存在数据稀疏性问题,因为只有少数空气质量监测站生成训练数据,但在一个城市中有数千个地方可以推断。
数据稀疏性是一个普遍的挑战,已经在许多计算任务中研究了多年。
我们将不再提出新的算法,而是讨论三种(但不限于这三种)可用于解决城市计算中的数据稀疏问题的技术:

4.4.1. Collaborative Filtering. 协同过滤(CF)是一种广泛应用于推荐系统中的知名模型。协同过滤背后的一般思想是相似的用户以相似的方式对相似的物品进行评级[Goldberg等人,1992;中村等[1998]。因此,如果确定了用户和产品之间的相似度,就可以对用户对未来产品的评级做出潜在的预测。根据城市计算的应用,项目可以是poi,如餐馆和加油站;道路段;地理区域;用户可以是司机、乘客或服务的订阅者。一旦形成了一个矩阵,我们可以使用CF模型来填补缺失的值。
基于内存的CF是最广泛使用的算法,它主要由基于用户之前评分的全部项目集合进行评分预测的启发式算法组成。也就是说,用户和物品的未知评级值通常计算为其他一些用户(通常是N个最相似的用户)对同一物品的评级的总和。有两类基于内存的CF模型:基于用户的和基于物品的技术。以图19所示的用户位置矩阵为例,可以根据以下三个方程预测i所在位置的用户p s interest (rpi),这是基于用户的协同过滤的一种常见实现:
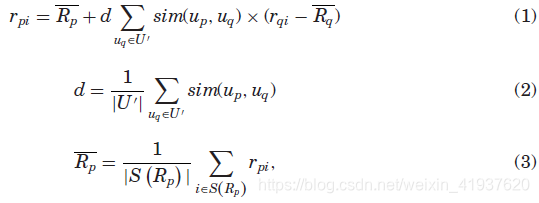

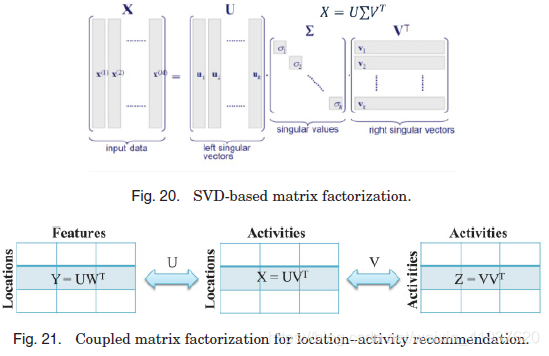
4.4.2. Matrix Factorization. 矩阵分解法把一个矩阵分解成两个或三个矩阵的乘积。矩阵分解有很多种,如LU分解、QR分解、SVD(奇异值分解)等。SVD是协同滤波中最常用的矩阵分解方法之一,将矩阵X分解为左奇异向量(U)、奇异值(∑)、右奇异向量三个矩阵,如图20所示。当矩阵X非常稀疏时,我们通常可以用三个低秩矩阵来近似它。例如,我们可以选择前n个最大的奇异值(∑),其和大于所有奇异值总和的90%。这样,矩阵分解可以作为一种有效的协同过滤方法。
有时我们也可以考虑矩阵分解过程中的环境。例如,如图21所示,给定许多用户的位置历史,Zheng等[2010f]建立了一个位置活动矩阵(X),其中行表示位置(如餐馆、商场等),列表示活动。矩阵中的一个条目表示人们在特定位置执行的活动的频率。如果这个位置活动矩阵完全填满,我们可以通过从与该活动对应的列中检索频率相对较高的top-k位置,为特定活动推荐一组位置。同样,当执行某个位置的活动建议时,可以从与该位置对应的行中检索top-k活动。然而,位置活动矩阵是不完整的,并且非常稀疏,因为一个人通常可以访问很少的位置。因此,传统的CF模型不能很好地生成高质量的推荐。单独分解X也没有多大帮助,因为数据过于稀疏。
为了解决这个问题,另外两个矩阵的信息,分别显示在图21的左右部分,可以合并到矩阵分解中。一个是位置特征矩阵;另一个是活动活动矩阵。这类附加矩阵通常称为上下文,可以从其他数据源了解到。在本例中,可以从POI数据库构建矩阵Y,其中一行表示位置,一列表示位置上的POI类别(比如餐馆和酒店)。矩阵Z对两个不同活动之间的相关性进行了建模,通过将两个活动的标题发送到搜索引擎中,可以从搜索结果中了解到这一点。其主要思想是在集合矩阵分解模型中要求X、Y、Z共享低秩矩阵U和V,从而在X、Y、Z之间传播信息。更具体地说,目标函数为:
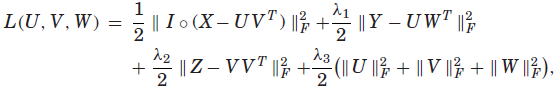
![]()
目标函数的前三项控制矩阵分解时的损失,最后一项控制分解后矩阵的正则化,防止过拟合。一般来说,这个目标函数对所有变量U, V和W都不是联合凸的。
为此,采用梯度下降等数值方法求解局部最优解。
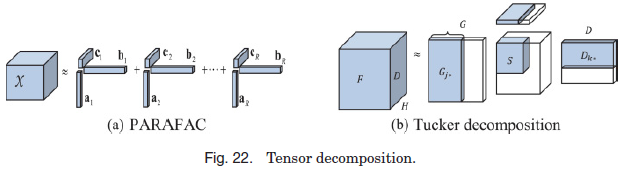
4.4.3. Tensor Decomposition. 张量通常有三个维度,可以根据有值的项分解为矩阵或向量的乘法。指导分解的目标函数是使分解结果的乘积与张量中现有项的值之间的误差最小。在分解之后,我们可以通过将分解的矩阵或向量相乘来填补张量中缺失的值。常用的张量分解方法包括PARAFAC [Rro 1997]和Tucker分解[Kolda and Bader 2009]。如图22(a)所示,PARAFAC将一个张量分解为一系列三个向量相乘的总和,而Tucker分解将一个张量近似为三个矩阵与一个核心张量相乘,如图22(b)所示。有时,给定一定的近似误差,我们只能维持分解矩阵的前几行或前几列(均称为奇异向量),以达到更好的效率(特别是当张量非常稀疏时),形式上记为:![]()

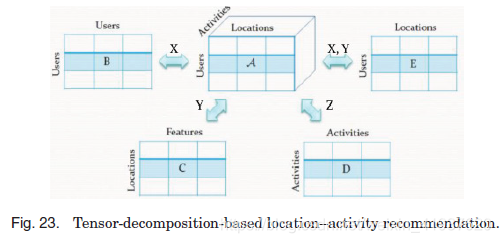
为了提高稀疏张量分解的精度,可以在分解过程中加入上下文信息。这类似于带有上下文的矩阵分解。在图21(章节4.4.2)所示的位置活动推荐示例之后,Zheng等[2010a, 2012d]在推荐系统中进一步考虑了用户维度,因此生成了一个(用户位置活动)张量。本质上,张量是非常稀疏的,因为用户通常访问几个地方。随后,如图23所示,基于其他数据源制定了四个矩阵,作为上下文信息,以提高张量分解的精度。然后提出了一个parafac风格的张量分解框架,将张量与这些上下文矩阵结合起来进行正则化分解。具体来说,目标函数定义如下:
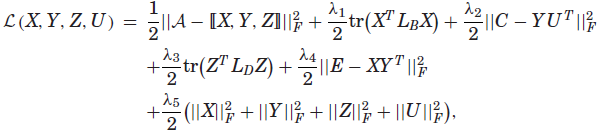

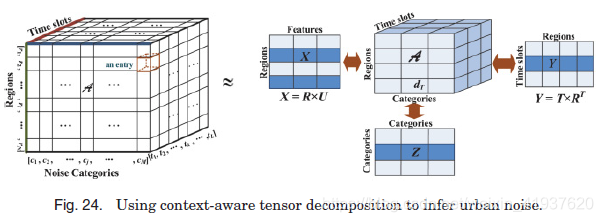
Zheng等[2014b]也采用了类似的张量分解技术来推断城市噪声。如图24左侧所示,每个地理区域的噪声都是用一个张量![]() 来建模的,该张量是一个三维张量,分别表示N个区域,M个噪声类别,L个时隙。补充张量A缺失项的一种常用方法是将A分解成一个核心张量
来建模的,该张量是一个三维张量,分别表示N个区域,M个噪声类别,L个时隙。补充张量A缺失项的一种常用方法是将A分解成一个核心张量![]() 与三个矩阵的乘积。
与三个矩阵的乘积。![]() ,
, ![]() 和
和![]() ,使用Tucker分解模型[Kolda and Bader 2009].控制分解误差的目标函数通常定义为:
,使用Tucker分解模型[Kolda and Bader 2009].控制分解误差的目标函数通常定义为:![]()
然而,在这个问题中,张量是过稀疏的。例如,如果将1小时作为时间段,则a的表项中只有5.18%的表项以周末为单位。仅根据A自身的非零项来分解A是不够精确的。来解决数据稀疏问题,正确的图24的一部分,郑等人提取三个类别的特征,包括地理特征、人类流动特性,和噪声类别相关功能(用矩阵X, Y, Z),分别来自POI/路网数据、用户签到和311数据。在分解过程中将这些特征作为上下文,以减少推理错误,使用目标函数:

更具体地说,A和X共享矩阵R;A和Y共享矩阵R和T;而LZ影响因子矩阵C。X、Y、Z的密集表示有助于生成相对准确的R、C、T,从而依次减小a的分解误差。换句话说,来自地理特征、人类活动特征和噪声类别之间的相关性的知识传播到张量A中。
4.4.4. Semisupervised Learning and Transfer Learning.半监督学习是一类监督学习任务和技术,也利用无标记数据来训练通常是少量的有标记数据与大量的无标记数据。许多机器学习研究人员发现,如果将未标记数据与少量标记数据结合使用,可以显著提高学习准确性。有多种半监督学习方法,如生成模型、基于图的方法和协同训练。关于这一问题的调查可以在Zhu[2008]中找到。具体来说,协同训练是一种半监督学习技术,需要数据的两个视图。它假设每个示例由两个不同的特性集描述,这两个特性集提供了关于一个实例的不同且互补的信息。理想情况下,给定类,每个实例的两个特性集是有条件独立的,并且实例的类可以仅从每个视图准确地预测。协同训练可以产生更好的推理结果,因为其中一个分类器正确地标注了其他分类器之前错误分类的数据[Nigam和Ghani 2000]。在4.3.2节中介绍的例子2是基于协同训练技术的。
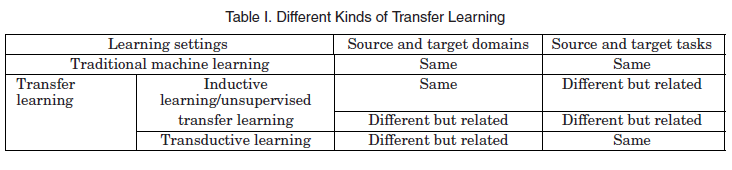
Transfer learning: 许多机器学习和数据挖掘算法的一个主要假设是,训练数据和未来数据必须在相同的特征空间中,并具有相同的分布。然而,在许多实际应用中,这个假设可能不成立。例如,我们有时在一个感兴趣的领域有一个分类任务,但我们在另一个感兴趣的领域只有足够的训练数据,后者的数据可能在不同的特征空间或遵循不同的数据分布。与半监督学习不同的是,半监督学习假设标记数据和未标记数据的分布是相同的,相反,迁移学习允许在训练和测试中使用的领域、任务和分布是不同的。在现实世界中,我们观察到许多迁移学习的例子。例如,学会辨认桌子可能有助于辨认椅子。Pan等[2010]对迁移学习进行了很好的调查,根据源域与目标域、任务之间的不同情况将迁移学习分为三类,如表1所示。
迁移学习算法可以帮助解决城市计算中的数据稀疏问题。例如,克服空气质量推断中的标签稀疏问题的另一种方法[Zheng 2013b]是将从一些空气质量数据充足的城市学到的知识转移到数据不足的城市。这属于转导学习,如表1所示。

4.5. Visualizing Big Urban Data
当谈到数据可视化时,很多人只会想到(1)原始数据的可视化和(2)数据挖掘过程产生的结果的呈现[Martinoc 2007]。前者可以揭示不同因素之间的相关性,从而为机器学习模型提供特征。例如,图25(一个)显示空气质量指数之间的相关矩阵PM10和气象数据,包括温度、湿度、气压压力,风速,用收集到的数据从2012年8月至12月,在北京,每个行/列表示一种气象数据和阴谋手段机能标签的位置。显然,高风速会分散PM10的浓度,而高湿度通常会导致高浓度。因此,它们可以成为机器学习模型中推断某个地点空气质量的重要特征。
另一方面,图25(b)可视化了我们在4.3节例3中引入的数据挖掘模型推导出的结果(即一个城市中所有司机访问加油站的次数)。展示结果可以帮助能源基础设施主管部门更好地做出在何处增建加油站的决定。如前所述,时空数据在城市计算中得到了广泛的应用。为了全面分析这些数据,需要从两个互补的角度来考虑:(1)作为随时间变化的空间分布(即时间上的空间),(2)作为局部时间变化在空间上分布的剖面(即时间上的空间)[Andrienko 2010]。
然而,数据可视化不仅仅是显示原始数据和显示结果。探索性可视化在城市计算、探测和描述数据中的模式、趋势和关系方面变得更加重要,这些数据是由特定的调查目的驱动的。当在数据中发现一些相关的东西时,新的问题就会出现,从而使特定的部分被更详细地查看。因此,探索性可视化以一种互动的方式结合了人类和电子数据处理的优势,涉及假设生成而不仅仅是假设检验[Andrienko 2003]。
4.6. Other Techniques
除了上述技术,城市计算作为一个多学科的领域,还需要其他技术的支持,如优化技术和信息安全。尽管本文试图尽可能多地涉及其他领域的知识,但主要是从计算机科学的角度撰写的。
4.6.1. Optimization Techniques. 首先,许多数据挖掘任务可以通过优化方法解决,如矩阵分解和张量分解。例子包括地点活动建议[Zheng et al. 2010a, 2010f, 2012d]和加油行为推理研究[Zhang et al. 2013],我们在第4.3节中介绍。第二,许多机器学习模型的学习过程实际上是基于优化和近似算法,例如,最大似然,梯度下降,和EM(估计和最大化)。第三,运筹学的研究成果与数据库算法等其他技术相结合,可以应用于求解城市计算任务。例如,拼车问题在运筹学中已经研究了很多年。如果我们想要使期望拼车的一群人的总旅行距离最小,这已经被证明是一个np困难问题。因此,很难将现有的解决方案应用于大量用户,特别是在在线应用程序中。在动态出租车拼车系统T-Share中,Ma等[2013]将时空数据库技术与优化算法相结合,显著减少了需要检查的出租车数量。最后,这项服务可以在线提供,以回答数百万用户的即时查询。第3.7.1节介绍了另一个示例。Chawla等人[2012]将基于pca的异常检测算法与L1最小化技术相结合,诊断导致流量异常的流量。城市计算应用的时空性质和动态性也给当前运筹学研究带来了新的挑战。
4.6.2. Information Security. 信息安全对于城市计算系统来说也很重要,因为城市计算系统可能会从不同来源收集数据,并与数百万设备和用户进行通信。
在城市计算系统中会出现的常见问题包括数据安全(例如,保证接收到的数据是集成的、新鲜的和不可否认的)、不同源和客户机之间的身份验证,以及混合系统中的入侵检测(连接数字和物理世界)。
4.7. Future Directions
虽然近年来城市计算的研究项目很多,但仍有不少技术缺失或研究不够深入。
- Balanced crowdsensing: 通过crowdsensing方法生成的数据在地理和时间空间上是非均匀分布的。在一些地方,我们可能拥有比我们真正需要的更多的数据。降采样方法(例如压缩感知)对于减少系统的通信负载是有用的。相反,在我们可能没有足够数据甚至根本没有数据的地方,应该考虑一些激励用户贡献数据的措施。在有限的预算下,如何为不同地点和时间段配置激励措施,以最大限度地提高接收到的数据的质量(例如,覆盖范围或准确性),以满足特定的应用还有待探索。
- Skewed data distribution:在许多情况下,我们可以获得的是城市数据的样本,其分布可能偏离完整的数据集。在城市计算系统中,拥有整个数据集可能总是不可行的。有些信息可以从部分数据转移到整个数据集。例如,出租车在道路上的行驶速度可以转移到在同一路段行驶的其他车辆。同样,出租车在加油站的等待时间可以用来推断其他车辆的排队时间。然而,其他信息不能直接传递。例如,道路上的士的交通量可能与私家车有所不同。因此,在一个路段上看到更多的出租车并不一定意味着其他车辆也会更多。
- Managing and indexing multimode data sources: 不同类型的索引结构已经被提出来单独管理不同类型的数据,而能够同时管理多种类型数据(如空间、时间和社交媒体)的混合索引还有待研究。混合索引(如图15所示的示例)是实现高效、有效地学习多个异构数据源的基础。
- Knowledge fusion: 处理单一数据源的数据挖掘和机器学习模型已经得到了很好的探讨。然而,能够从多个数据源中学习相互加强的知识的方法仍然缺乏。知识融合并不意味着简单地将从不同来源提取的特征集合放在一起,而是需要深入理解每个数据源,并在计算框架的不同部分有效地使用不同数据源。研究,如三个例子[Zheng et al. 2013b;章节4.3中的Zhang et al. 2013]被认为是罕见的。
- Exploratory and interactive visualization for multiple data sources:城市计算系统通常有大量的数据和知识要可视化。目前,通过对空间和时空空间的探索性可视化来研究多个数据源之间的隐式关系并非易事。例如,有多种因素(如交通、工厂排放、气象和土地使用)可能影响一个地点的空气质量。不幸的是,以下问题仍然很难回答:在特定地点或特定时期,哪一个因素对空气质量的影响更突出?北京冬季PM2.5的主要根源是什么?
- Algorithm integration: 为了提供端到端的城市计算场景,我们需要将不同领域的算法集成到计算框架中。例如,我们需要将数据管理技术与机器学习算法相结合,以提供既高效又有效的知识发现能力。同样,通过将时空数据管理算法与优化方法相结合,我们可以解决大规模动态拼车问题。可视化技术应该涉及到知识发现过程,与机器学习和数据挖掘算法一起工作。因此,城市计算既需要数据的融合,也需要算法的整合。从长远来看,我们所面临的前所未有的数据将模糊传统计算机科学不同领域(如数据库和机器学习)之间的界限,甚至将架起不同学科理论之间的桥梁,如土木工程和生态学。
- Intervention-based analysis and prediction:在城市计算中,预测城市环境变化的影响是至关重要的。例如,如果一个地区新建了一条道路,该地区的交通会发生怎样的变化?如果我们把工厂从城市里搬走,空气污染会减少到什么程度?如果一条新的地铁线路开通了,人们的出行方式会受到什么影响?能够用自动化的、不引人注意的技术来回答这类问题,将对政府官员和城市规划者的决策非常有帮助。不幸的是,基于干预的分析和预测技术还没有得到很好的研究,这种技术可以通过在计算框架中插入和剔除一些因素来提前估计变化的影响。
4.8. Miscellaneous
Conferences and workshops: The research into urban computing published in the computer sciences domain can be majorly found in leading conferences, such asKDD, ICDE, and UbiComp, and a few workshops, like the ACM International Workshop on Urban Computing (UrbComp) [Zheng and Wolfson 2012c; Zheng et al. 2013a]. Journals and magazines: We can also easily find related articles from many journals, such as IEEE Transaction on Knowledge Discovery and Data Engineering (IEEE TKDE), ACM Transaction on Intelligent Systems and Technology (ACM TIST), and Personal and Ubiquitous Computing (Springer PUC), and magazines, such as IEEE Pervasive Computing.
Data sources: Quite a few major cities have their own open data portal; for example, New York City has published many useful data sources on their portal: https://nycopendata.socrata.com/. There are also a few public datasets on some researchers’ homepages, for example, Dr. Zheng’s homepage http://research.microsoft.com/en-us/people/yuzheng/.
5. CONCLUSION
城市空间中产生的大量数据和计算技术的进步为我们提供了前所未有的机会来应对城市面临的巨大挑战。城市计算是一个交叉学科领域,计算机科学与传统的城市相关学科,如土木工程、生态学、社会学、经济学和能源。在城市的背景下,城市计算获取、集成和分析大数据来改善城市系统和生活质量的愿景,将带来对数十亿人至关重要的智慧和绿色城市。大数据还会模糊传统计算机科学(如数据库、机器学习和可视化)不同领域之间的界限,甚至会弥合不同学科(如计算机科学和土木工程)之间的鸿沟。而城市计算带来了革新城市科学和进步,相当多的技术,如混合索引结构多模数据,跨异构数据源的知识融合,探索城市数据,可视化算法的集成不同的领域,和intervention-based分析,还可以研究。本文讨论了城市计算的概念、框架和挑战;介绍了城市计算的代表性应用和技术;并提出了一些需要社区努力的研究方向。

















 2577
2577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









