







 本文介绍了StyleGAN Encoder中的人脸对齐过程,强调了对齐在神经网络训练中的重要性。通过使用dlib人脸识别模型获取68点landmarks,对人脸进行对齐,包括计算裁剪区域、处理坐标超出图片范围的问题以及使用高斯滤波进行图片锐化。详细代码及注释见align_images.py、landmarks_detector.py和face_alignment.py。
本文介绍了StyleGAN Encoder中的人脸对齐过程,强调了对齐在神经网络训练中的重要性。通过使用dlib人脸识别模型获取68点landmarks,对人脸进行对齐,包括计算裁剪区域、处理坐标超出图片范围的问题以及使用高斯滤波进行图片锐化。详细代码及注释见align_images.py、landmarks_detector.py和face_alignment.py。
在StyleGAN Encoder中,人脸对齐(face_alignment)是一个不可缺少的操作。对没有进行人脸对齐的真实人脸图片,直接运行encode_images.py会大概率遇到不能收敛的情况(即:找不到对应真实人脸的dlatents向量),或者生成的图片只有人脸轮廓,五官相貌一片模糊。
这里的一个启发是,如果打算将StyleGAN这样的神经网络重新训练,用于生成服装样式或者汽车外观设计等领域,对原始图片的标注和对齐(alignment)工作将是十分重要的。一个没有进行对齐预处理的原始数据集,其训练与应用难度和时间消耗将是灾难性的。
那么,StyleGAN Encoder中的人脸对齐是怎样实现的呢?它的大致过程如下:
(1)获取dlib人脸识别模型“shape_predictor_68_face_landmarks.dat.bz2”,并解压缩,在我的Windows 10笔记本上,它放在这个目录下:C:\用户\HP\.keras\temp
(2)在原始图片文件目录(.\raw_images)下遍历,读取每个图片文件,获取图片中的每一个人脸的68点landmarks(.\ffhq_dataset\landmarks_detector.py),并对单个人脸进行人脸对齐操作;
(3)在人脸对齐操作中(.\ffhq_dataset\face_alignment.py),首先计算需要裁剪的人脸区域,这一部分计算看起来很复杂,我画了一个图示意,计算的过程与结果大致如下(Pillow的坐标系原点:图像的左上角为 (0, 0) , X轴是从左到右增长的,而Y轴是从上到下增长,因此对应到程序中的坐标,下面的图需要上下翻转才能对应。):
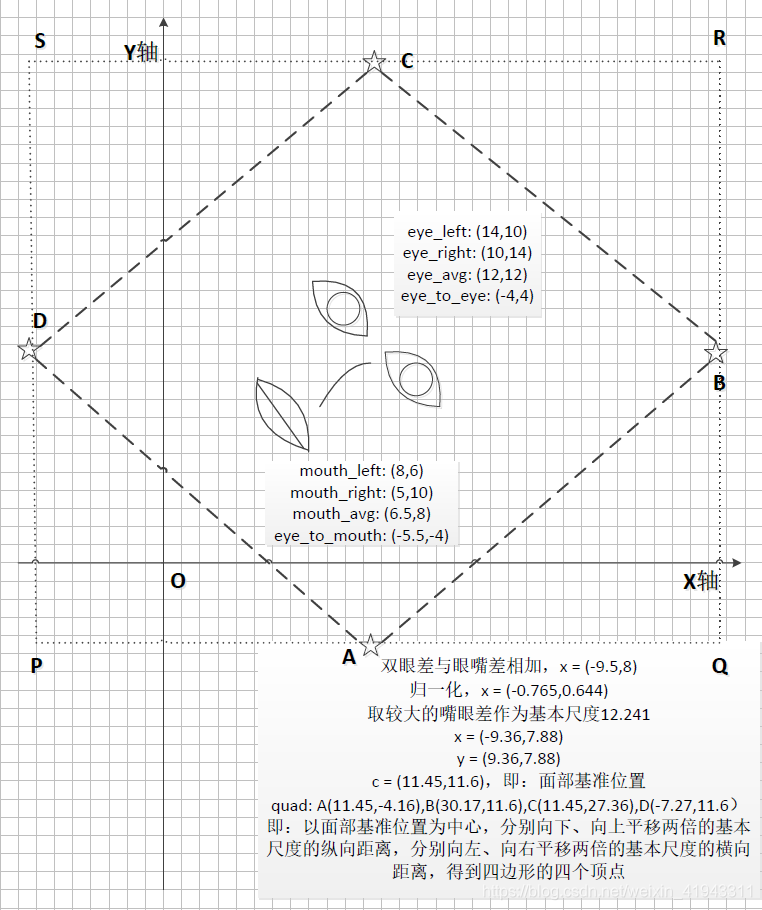
这里,四边形ABCD是下面需要转换到对齐人脸的区域,四边形PQRS是用于裁剪的四边形区域。需要注意,根据计算得到用于裁剪的四边形的顶点,其中P、Q、S三点已经跑到了X轴和Y轴的负值区域(也就是说,跑到了原始图片的像素区域以外);
(4)对于裁剪四边形的顶点落到原始图片像素区域以外的情况,需要对这些外部区域进行数据填充(Pad),然后使用高斯滤波对图片进行锐化;
(5)最后,调用Pillow的transform方法,将四边形ABCD转换成对齐的人脸区域,并保存到文件。
完整的带中文注释的源代码如下:
.\align_images.py
import os
import sys
import bz2
import argparse
from keras.utils import get_file
from ffhq_dataset.face_alignment import image_align
from ffhq_dataset.landmarks_detector import LandmarksDetector
import multiprocessing
LANDMARKS_MODEL_URL = 'http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2'
def unpack_bz2(src_path):
data = bz2.BZ2File(src_path).read()
dst_path = src_path[:-4]
with open(dst_path, 'wb') as fp:
fp.write(data)
return dst_path
if __name__ == "__main__":
"""
Extracts and aligns all faces from images using DLib and a function from original FFHQ dataset preparation step
python align_images.py /raw_images /aligned_images
"""
parser = argparse.ArgumentParser(description='Align faces from input images', formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('raw_dir', help='Directory with raw images for face alignment')
parser.add_argument('aligned_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









