






公众号:程序员黑黑 领资料、面试题、学AI、入交流群,欢迎关注哈。
在我们平时开发的时候,有时候会碰到需要修改host的情况,但是host文件并不是特别好找,找起来都比较费劲,并且这个文件还很重要,万一改错了、误删了很麻烦。
SwitchHosts 简介
这个时候我们可以尝试下 switchhost 这个开源软件,它是一个开源的 host 切换工具。支持 Windows、macOS 和 Linux 等。它目前有 20.6k 的star,还是非常棒的。
安装
我们向下滑,找到它的下载项,点击 这里 ,跳转到它的下载界面。然后我们点击这个 Assets 在展开的列表里选择自己系统对应的安装包进行安装就可以了。
简单使用
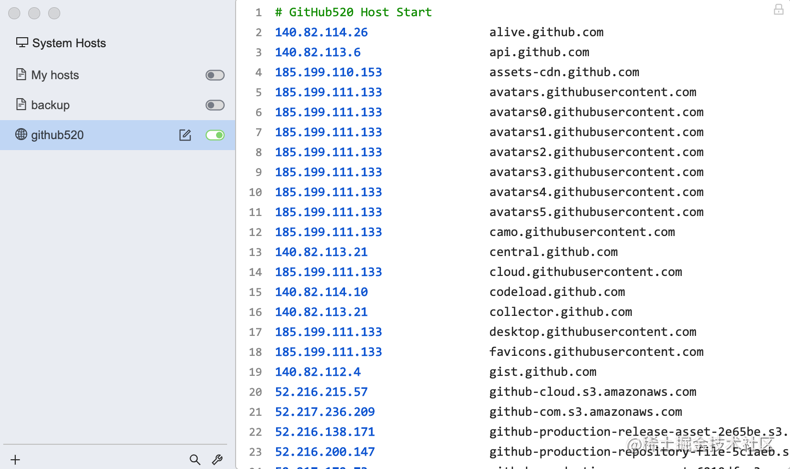
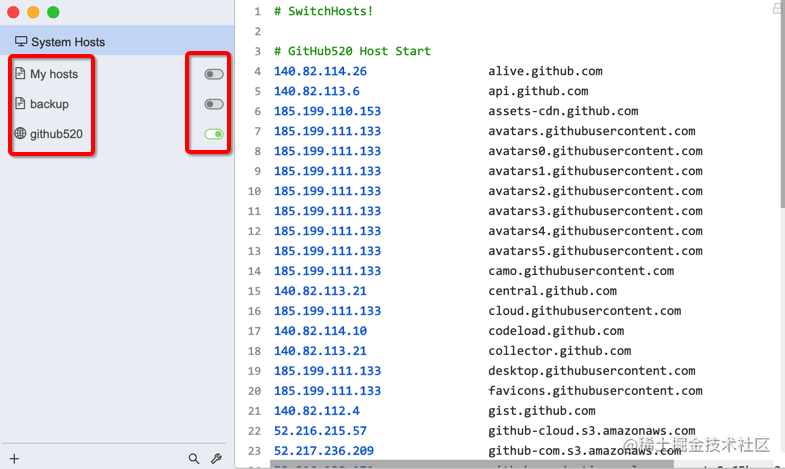
打开软件后,可以看到我这里已经有了一些 host 项,我们可以根据自己的需求新建很多的 host 配置项,控制相应 host右侧的这个开关来启用和关闭对应的 host 的配置项。
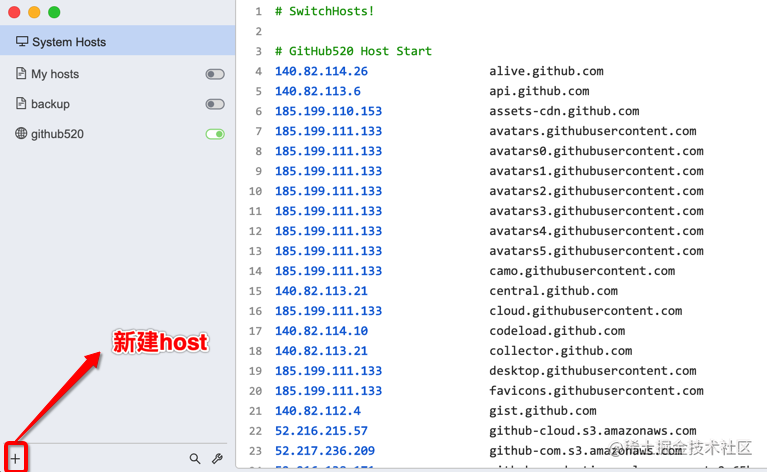
点击左下角的添加按钮,可以新建一个 host 项,标题这里可以写上当前配置的 host 是为了干啥的,比如它是针对哪个项目的host。
类型这我们常用的一般就本地和远程两个,本地需要你手动配置你需要的host;远程用来从其他服务器自动拉取已存在的 host 内容。
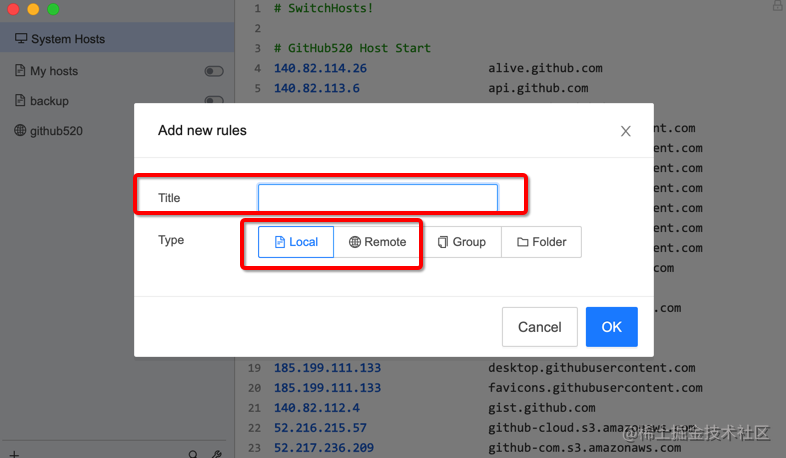
这里还可以配置刷新时间。
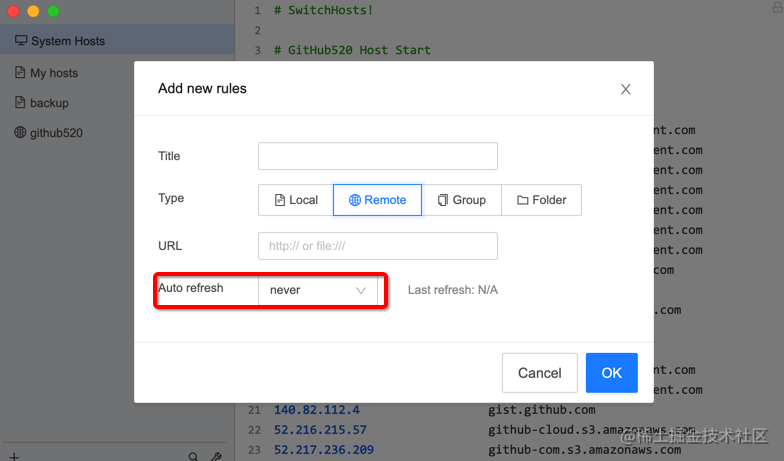
有兴趣的小伙伴可以研究下。
感谢阅读
- 如果本文对您有帮助,欢迎点赞\评论\收藏哈,您的「点赞\评论\收藏」是我创作的加油站,感恩🤗。
- 公众号:程序员黑黑 领资料、面试题、学AI、入交流群,欢迎关注哈。















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









