







目录
一、索引算法
1.索引介绍
索引相当于一本书的目录,可以优化查询,会影响到加锁的过程
目的是减少IO次数,减少IO量级,减少随机IO
2.索引种类及查找算法
| BTREE | 99.9% | InnoDB |
| RTREE | NO | MongoDB |
| HASH | MEM引擎 | Redis |
| FULLTEXT | TEXT类型 | ES |
3.BTREE查找算法演变
B-TREE 普通B树
B+TREE 叶子节点双向指针
B++TREE 枝节点双向指针
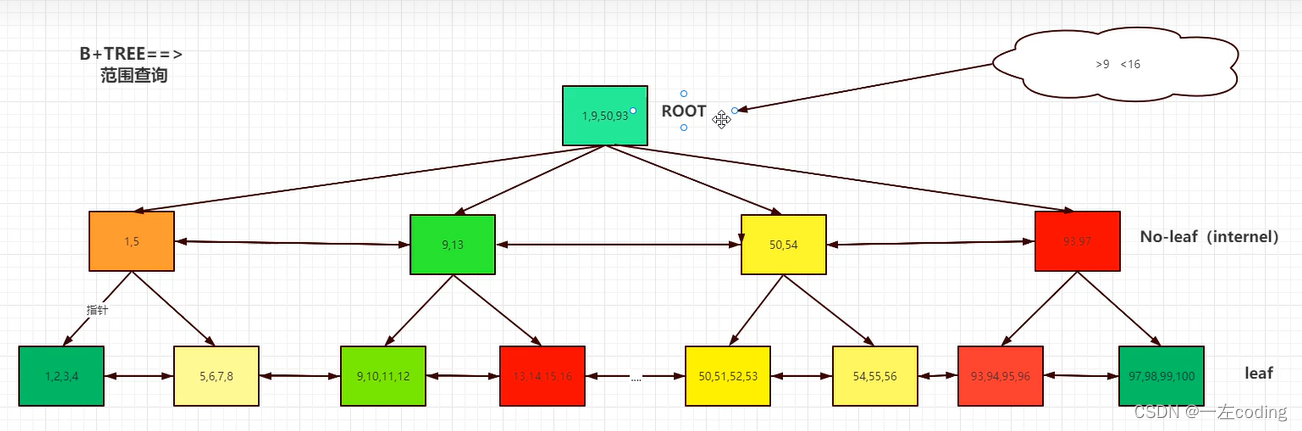
4.BTREE两类结构
1)聚簇索引 Clustered index (每个数据页16K,64个连续的数据页组成1个区,每个区1M)
2)辅助索引 Secondry (普通单列索引、普通联合索引、唯一索引、前缀索引)
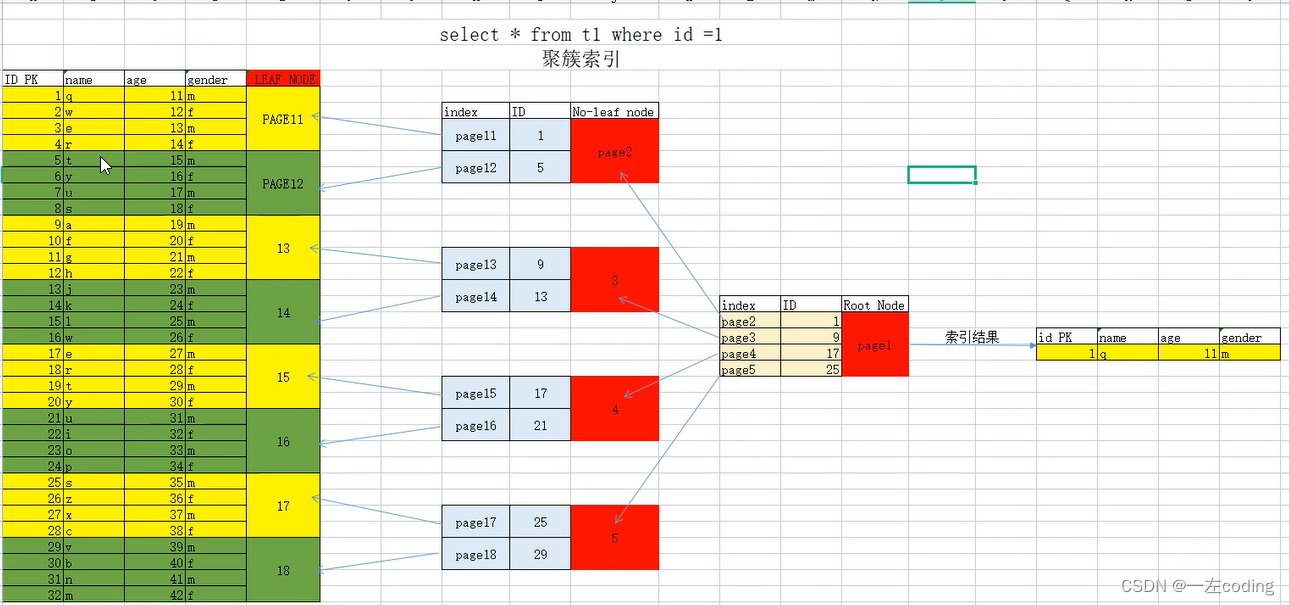
二、聚簇索引
1.适用情况
适用以id作为where条件的语句(order by,group by)
2.如何生成聚簇索引
1)如果表中设置了主键(例如id列),自动根据id列生成聚簇索引
2)如果没有设置主键,自动选择NOT NULL唯一键的列作为聚簇索引
3)自动生成隐藏(6字节的row-id)的聚簇索引
总结:innodb表中一定有聚簇索引
3.聚簇索引功能
1)录入数据时,按照聚簇索引组织存储数据,在磁盘上有序存储数据行
2)加速查询
4.聚簇索引的B树构建
1)数据行在存储时,按照聚簇索引的逻辑顺序和物理顺序有序存储
2)叶子节点,就是数据行所在的数据页,数据即索引
3)枝节点,存储了叶子结点范围+指针
4)根节点,存储了非叶子节点的范围+指针
三、辅助索引——普通单列索引
1.构建过程
alter table t1 add index idx(name)
1)从原表中获取:索引列(name)+ID值
2)叶子节点:按索引列值(name)从小到大排序,生成叶子节点
3)枝节点:叶子节点的name范围+指针
4)根节点:枝节点的name范围+指针
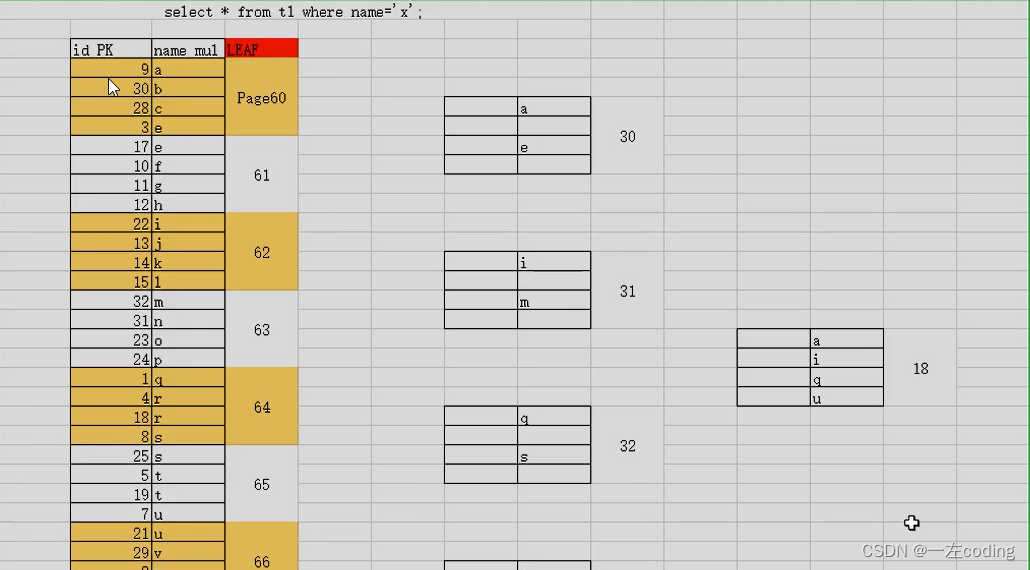
2.辅助索引——普通单列索引,是如何起到优化效果的?
1)根据name列的条件值,在辅助索引扫描,获取到ID
2)拿着ID回表查询,最终获得想要的数据页,再去SQL层处理
四、辅助索引——联合索引
1.构建过程
1)叶子节点:获取id+name+age,按照name和age组合排序(最左优先排原则),将有序的值存储到连续的数据页中,构成叶子节点
2)枝节点:叶子节点的name范围+指针
3)根节点:枝节点的name范围+指针
2.联合索引如何提供查询优化?
例如:where name=xx and age=xx
1)按照name条件值,扫描根节点和枝节点,找到叶子节点
2)根据叶子节点内容再做条件过滤,最终获得ID
3)拿着ID回表查询,最终获得想要的数据页,再去SQL层处理
3.联合索引最左原则
1)建立联合索引时,最左侧选择基数大的列(重复值小的)
判断基数的语句:select count(distinct num)from table;
2)查询条件中必须包含索引中的最左列
五、索引回表的问题
1.什么是回表查询?
从辅助索引扫描完之后,再根据id聚簇索引扫描的过程
2.回表会带来什么影响?
1)IO增多,IOPS--->每秒IO的次数,定值
吞吐量-->多少兆每秒
2)随机IO增多
3.怎么减少回表?
1)索引覆盖
select的值和索引有覆盖
例如 alter table t1 add index idx_1(name,age)
select age from t1 where name=xx;
2)精细化查询条件+合理的联合索引
3)调整优化器算法
六、关于索引树高度
1.高度建议
一般3层B+TREE,可以存储200w左右的数据,建议索引树做到4层以内
2.索引树高度的影响因素
1)数据行数多,数据量大
2)索引长度过长
3)主键值过长(例如自动生成额row_id,后期会很长)
3.索引树高度的解决方案
1)分库分表,数据归档
2)数据类型选择合适简短的,使用前缀索引
3)规划简单的主键,方便建立索引查询
七、索引的管理操作
1.查看表的索引
show index from table;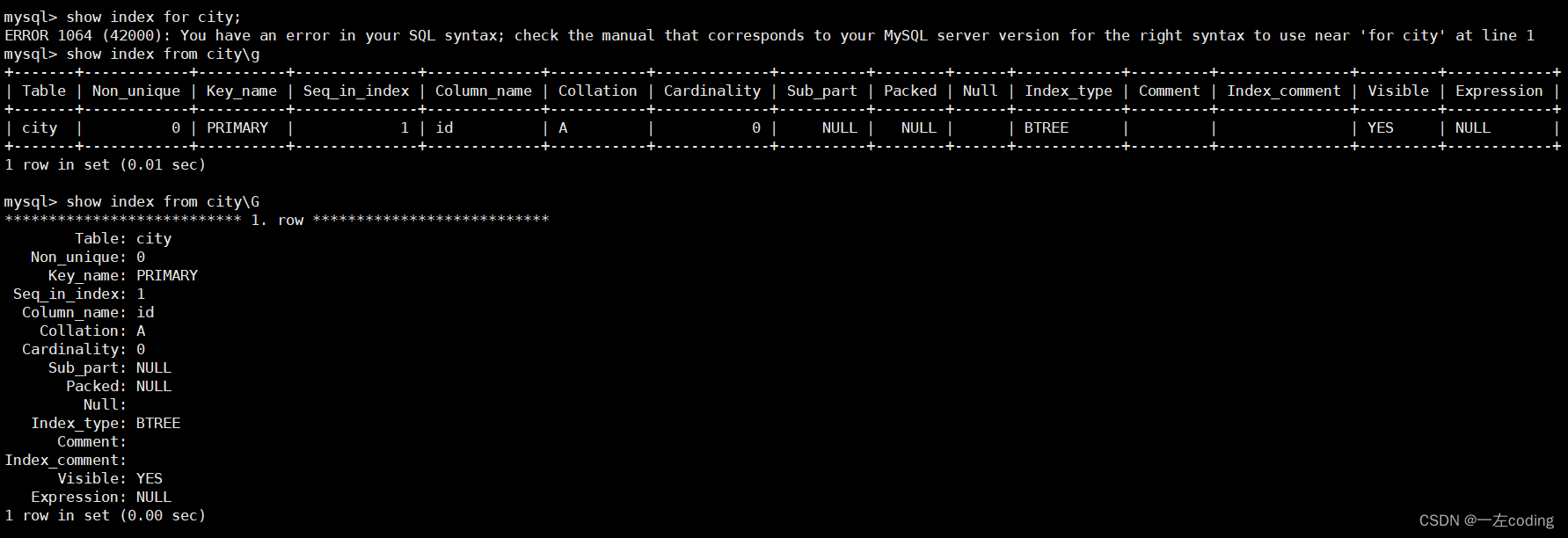
2.创建索引(DDL操作)
原则:将经常作为查询条件的列作为索引列
单列索引:alter table city add index idx_name(name);
联合索引:alter table city add index idx_npd(name,population,district);

3.创建前缀索引(DDL操作)
alter table city add index idx_nn(name(5));
只会截取name列的前五个字符做索引,可以减少索引树的高度

4.删除索引(DDL操作)
alter table city drop index idx_npd;















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









