







最近重新看了下mysql索引的相关知识,总结一下,下边以mysql的innodb存储引擎为例,其他的存储引擎会有差别,先简单说一下b+树,因为mysql的索引是以b+树的结构存储的,下边先上张b+树的结构图

这张图是我自己生成的,之前找了个网站可以看到动态出生成b+树的过程,有兴趣的可以研究一下,生成网址,B+树有以下特点:
- 每个节点中子节点的个数不能超过 N,也不能小于 N/2(不然会造成页分裂或页合并)
- 根节点的子节点个数可以不超过 m/2,这是一个例外
- m 叉树只存储索引,并不真正存储数据,只有最后一行的叶子节点存储行数据。
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找
说明:
- 有的资料显示的叶子节点中的指针是单向的,有的资料显示叶子节点中的指针是双向的,我觉得是双向指针,如果你能确定是那一种的话可以告诉我,咱们一起探讨一下。
- 上图中最后一个叶子节点上存了俩数据,其他的节点都存了一个数据,这个节点的大小可以自己设定,对应的是索引的长度,据说在长度为4的时候性能达到最优
mysql的索引结构和b+树相同,也就是生成的索引和上图的形状一样,mysql查找数据是以页为最小存储单元进行IO的,每页数据的大小为16kb(默认的,大小可以自己调),innodb的所有数据文件(后缀为ibd的文件),他的大小始终都是16384(16k)的整数倍。假如表中的每条数据大小是1kb,则每次IO可以取出16条数据,mysql的索引分为两种:
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行
innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,也就是咱们常说的回表操作,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值,如果没有定义主键,Innodb会选择第一个非空的唯一索引代替,如果没有非空唯一索引,Innodb会隐式定义一个6字节的rowid主键来作为聚集索引。,假如在字段A、B、C上建立了复合索引,则该索引生成的b+树的叶子节点上存放的东西有该条数据上ABC三个字段的值以及指向主键id的指针,下边对几种特殊查询是否会用到索引以及如何通过索引来查找数据进行一下分析:
先建个人信息表,主键id,复合索引建立在province、city、area三个字段上边,sql如下:
-- ----------------------------
-- Table structure for personal_info
-- ----------------------------
CREATE TABLE `personal_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`province` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`city` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`area` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `first_index`(`province`, `city`, `area`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of personal_info
-- ----------------------------
INSERT INTO `personal_info` VALUES (1, '张三', '河南', '郑州', '高新区');
INSERT INTO `personal_info` VALUES (2, '李四', '河南', '郑州', '二七区');
INSERT INTO `personal_info` VALUES (3, '王五', '河南', '焦作', '三阳区');
INSERT INTO `personal_info` VALUES (4, '赵六', '河南', '郑州', '金水区');
INSERT INTO `personal_info` VALUES (5, '小明', '河南', '焦作', '解放区');
INSERT INTO `personal_info` VALUES (6, '小红', '北京', '北京', '朝阳区');
INSERT INTO `personal_info` VALUES (7, '小绿', '北京', '北京', '通州区');
INSERT INTO `personal_info` VALUES (8, '小兰', '北京', '北京', '海淀区');
INSERT INTO `personal_info` VALUES (9, '小黄', '北京', '北京', '东城区');上边有两个索引,主键索引和符合索引first_index,存储结构分别如下


上边主键id的索引结构是按照从小到大的顺序排序的,下边first_index索引的排序是根据建立字段时候选择的排序方式进行排序的
一、先来个简单的sql,
SELECT * FROM personal_info WHERE id = 6;这个sql用到了主键索引,查找顺序应该是 5—>7—>6—>6,一共查找了4次就找到了想要的数据,如果没有使用索引的话就需要全表扫描,查询8次,这还是数据量不多的情况下,如果有一万条数据,全表扫描的话就需要查询一万次,所以查询时用索引字段会快,但也不是一定的,下边会有特殊情况出现
二、上边的sql升一下级,
SELECT * FROM personal_info WHERE id < 6;这个sql也用到了主键索引,同样是先查找id=6的数据的位置,查找顺序也是 5—>7—>6—>6,找到6在叶子节点上的位置后,根据叶子节点上存储的向左的指针从而查询到小于6的所有数据,如果你的where条件是id>6,那么就会顺着向右的指针查询下去,所以我觉得叶子节点上存储的指针是双向的,不是单向的
三、上边两条sql用到的是主键索引,下边用下复合索引,大家都知道复合索引的使用有个前提就是最左原则,在查询的where条件中只有使用了复合索引中最左边的字段才会生效,但是只要用到了最左边的字段就一定会用复合索引吗?可以先运行下下边的sql
SELECT * FROM personal_info WHERE province='河南' 按说用到了复合索引的第一个字段province,应该会用到复合索引,但是explain分析一下你会发现并没有用到索引,possible_keys只是可能用到的索引,key中并没有任何值,所以最后没有用到索引
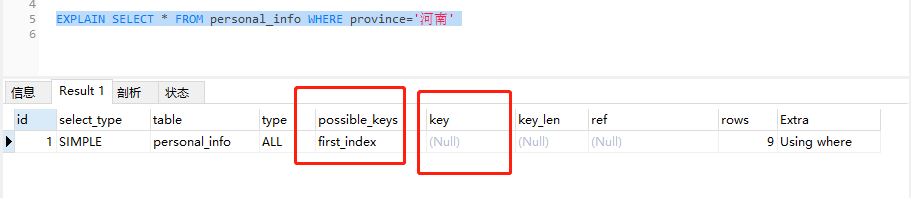
说下复合索引的查询顺序,其他的非聚集索引也是同样的查询顺序,按照b+树的结构一级一级往下找,发现叶子节点上第1,2,3,4,5条记录都符合要求,由于复合索引的叶子节点上只存储了索引字段的值以及指向主键索引的指针,而我们要查询的是所有字段,所以mysql知道id为1,2,3,4,5的数据都符合条件后又会拿着主键id通过主键索引去最终找到符合条件的记录,也就是传说中的回表操作,但是通过id去找记录,又会查找5遍主键索引,所以最后查询记录的次数就成了 查找符合索引的次数+主键索引查找*5,我就是全表扫描也就查询8次,但是用你这个复合索引的话就要查找二十多次,mysql有查询自动优化的机制,它发现不用索引会更快,就会在查询的时候不用索引
四、上边是select * 的情况,下边在来一条同样的sql
SELECT province,city,area,id FROM personal_info WHERE province='河南' 用explain解析一下该条sql
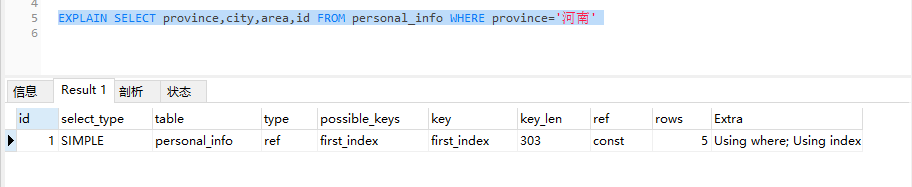
只是改变了一下select的字段而已,但是又用到了复合索引了,这是因为前边提到的复合索引的叶子节点上存储的信息有索引字段的数据和主键的数据,也就是叶子节点上存储了咱们查询需要的province,city,area,id这四个字段,不需要在通过id去进行回表查询操作了,只是查询复合索引就可以找到结果了,mysql发现这种情况下使用索引会比较快,所以就使用了复合索引
五、再说一种比较特殊的情况,模糊查询,一般情况下认为模糊查询不会用到索引,需要进行全表扫描,但是大家看下下边这条sql有没有用到索引
SELECT province,city,area,id FROM personal_info WHERE province like '河南%' 用explain解析一下该条sql

又使用到了索引,前边不是刚说模糊查询不会用到索引吗,怎么这里又用到了,难不成在搞我?这是因为复合索引排序时会先根据第一个字段进行排序,第一个字段相同时根据第二个字段排序,依次类推,查询时会拿着‘河南’俩字去b+树中找‘河南’俩字开头的数据,有与查询的字段叶子节点中全部存有,所以也不用回表操作了,这样就避开了全表扫描,所以mysql会选用复合索引。如果把字段换成‘%河南’,在索引树中查找时由于前缀是%,也就说可以是任意值,所以会将索引中的所有数据全部扫描一遍,mysql认为这样是低效率的,所以不会用到索引
六、sql中有用到in的情况
EXPLAIN SELECT province,name FROM personal_info WHERE id in (5,6,7)用explain解析一下该条sql
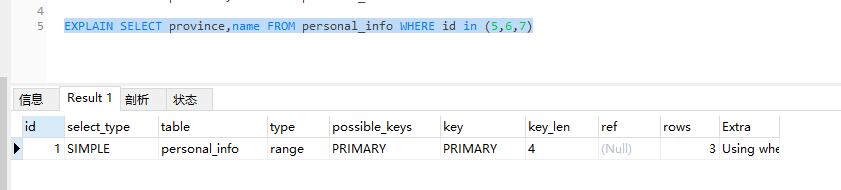
用到索引了,之前我一直以为in条件不会用到索引,后来查一下说是MySQL 在 5.5及以上 版本中,优化器对 in 操作符可以自动完成优化,针对建立了索引的列可以使用索引,没有索引的列还是会走全表扫描。
上边就是我最近复习时遇到的几种特殊情况,我写文章的水平有限,这玩意又比较抽象,如果你没看明白的话请给我评论,我在详细解释一下,如果以后遇到其他特殊的sql我会补充进来















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









