







用来描述对象特征的各类信息,通常会被整合成记录,而记录使得信息组织、表示以及存储变得轻松。而记录由字段组成,不同的字段用来表示不同的信息,C中可以通过结构体来组合这些字段(成员)。
一、结构体的声明以及初始化
联合体实际上来说是特殊数据结构的一类,通过关键词struct来定义。定义结构体有几种方法:
struct FUNC1//仅声明一个模板
{
char* name;
uint32_t height;
uint32_t length;
};
第一种方法,将会定义一个名称为struct FUNC1的结构体模板,它里面包含了一个指向字符的指针,两个整形的变量。模板并不代表已经分配了空间,或许可以说定义了一个叫FUNC1的新类型。如果要声明一个这样的变量,那么需要借助关键词struct FUNC1 variable1来完成。
struct FUNC1//声明一个模板的同时声明一个变量
{
char* name;
uint32_t height;
uint32_t length;
}variable1;
这种写法,实际上与第一种方法没什么差别,只是在声明模板的过程中同时声明了一个变量,此时这个变量已经分配了相应的空间。
typedef struct FUNC1//声明一个模板并将这个模板的名称重定义
{
char* name;
uint32_t height;
uint32_t length;
}FUNC2;
第三种写法则是在第一种写法的基础上利用了关键词typedef,在看这段的时候,可以将其分解为两个步骤:
1、声明了一个名称为FUNC1的模板。
2、将类型 struct FUNC1 映射到FUNC2中。
由此一来,声明一个变量除了使用struct FUNC1 variable1以外,还能使用来FUNC2 variable1实现。
typedef struct//直接声明一个模板但名称为FUNC2
{
char* name;
uint32_t height;
uint32_t length;
}FUNC2;
这第四中写法,可以和其他几种进行对比,是常用的方法,省去了声明的struct FUNC1的功夫,新的类型名称也不需要前缀struct,变量类型更具隐蔽性。
说完了结构体的声明,那么对应的变量在空间中究竟是怎么样排放的?

结构体的空间排放由模板中成员的声明顺序决定,从低地址向高地址生长,而在STM32中内存使用的是小端模式,故变量variable1的内存情况如上图所示,一个指针的长度与地址总线长度一致,占用32bit,整形同理。但是这个模板并不是最佳的说明案例,先介绍联合体再进入主题。
结构体变量的初始化可以分为两种,第一种是全成员的赋值初始化,例如variable1变量:
FUNC2 variable1={"xx",20,20};
从C99之后,添加了一个新的初始化方案:标准C的标记化结构初始语法,实际上在Linux内核中这个用法比较常见,例如驱动程序中的file_operation结构体就是使用这个方案。
FUNC2 variable1={
.length = 20,
.height = 20
};
这个方案大幅度的灵活了初始化的操作,例如结构体的有些成员在一开始就有含义,那么就只需要初始化相应的成员。
顺便一提,结构体的成员一般情况下必须是大小确认的,即不允许可变长度的变量在结构体中。若是结构体中的最后一个成员,则允许该变量为可变数组。但是该结构体模板的空间大小并没有包含这个弹性可变数字成员,所以在使用malloc时,需要额外分配所需的空间:
FUNC2* variable1 = malloc(sizeof(FUNC2)+sizeof(float)*10);
二、结构体成员的内存对齐规则
结构体成员的内存对齐法则在此处不做详细介绍,位字段的内存对齐才是讨论的重点。
简言之就是结构体中成员的取址方式可能受到其他成员的影响:
typedef struct
{
char name;
uint32_t height;
uint16_t length;
}Type1;
typedef struct
{
char name;
uint16_t length;
uint32_t height;
}Type2;
Type1 variable3;
Type2 variable4;
Type1类型的变量,空间存放有稍许不同,规则规定第一个成员name无需任何的偏移。而第二个成员height的放置则和第一个成员的长度有关,height是一个32位(4个字节)的变量,它的地址必须满足是4的倍数,而第一个成员只占了一个字节,那么后面的3个字节都会被编译器填充(padding),所以height偏移了3个字节。第三个成员length长度为2个字节,当前的地址满足被2整除的要求,所以不用偏移。
照这么算起来,这个模板的总空间长度应该是10个字节,运行代码sizeof(Type1) 得到12个字节。这是由于编译器为了cpu能够保证所有的成员只通过一次地址访问就可以获得,所以整个结构体都默认以最大地址长度为单位,所以在尾部也填充了2个字节

需要留意的是系统填充的空间由于是匿名状态,所以访问不到,但是可以通过强制类型转换进行访问以及修改。
三、联合体以及嵌套结构体的用法
联合体是借助关键词union实现的,所谓联合体实际上就是共用一块内存,而联合体所占用的内存根据成员中占用的最大内存来确认。在声明和初始化上,联合体也支持结构体相关的操作。
typedef union
{
uint8_t data_8[5];
uint16_t data_16[2];
uint32_t data_32;
}FUNC2;
FUNC2 variable2;
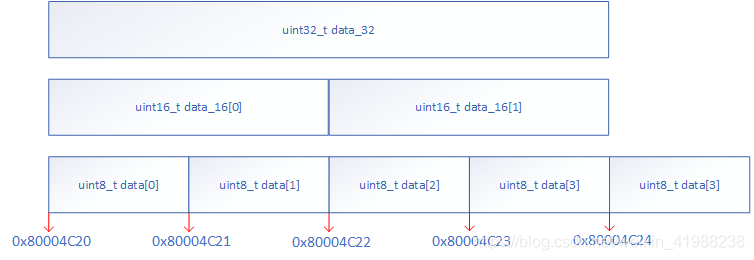
此时若对变量variable2使用函数sizeof可以得到它的长度为5。联合体在数据协议管理上有着重要的用途,通常在面对一些定制且复杂的协议,根据数据去一个个解析是相当麻烦的,但若是配合联合体嵌套则简化很多。例如:在一个字节中隐藏多个状态位:

若每次接收到这一帧数据时都通过位计算则过于繁琐,那么试一下嵌套以及位字段
typedef union
{
uint8_t data;
struct
{
uint8_t ERR_BIT : 1;
uint8_t STATUS_BIT : 3;
uint8_t IT_BIT : 1;
uint8_t OVER_BIT : 1;
uint8_t BUSY_BIT : 1;
uint8_t ENABLE_BIT : 1;
};
}STATUS;
这个嵌套结构体涉及到了两个概念,一个是位段的概念,另一个是小端模式的概念。
位段
在通常情况下,计算机处理的最小单元是字节,一个字节是8bit。但是有时候某些开关量的状态并不需要占用一个字节的空间,为了提高空间效率,便产生了位段的概念,位段可以指定一个变量占用的bit。
位段声明的方式为:
类型 成员名称: 宽度;
类型是用来解释该成员的方式,宽度则是这个成员占有的位数。实际上,在声明的过程中,成员名称是可选的,若是该成员匿名了,则在结构体中无法引用它,一般该方式用来填充空间(可以设成0宽度,编译器将默认从下一个可寻址内存地址来读取成员)。
例如上述STATUS联合体的匿名成员则指定了位,若将一个字节数据赋值给联合体中的data就可以等价于:
ERR_BIT = (uint8_t)(data & 0x01);
STATUS_BIT = (uint8_t)(data & (0x07<<1));
IT_BIT = (uint8_t)(data & (0x01<<4));
OVER_BIT = (uint8_t)(data & (0x01<<5));
BUSY_BIT = (uint8_t)(data & (0x01<<6));
ENABLE_BIT = (uint8_t)(data & (0x01<<7));
位段的操作可以放到任意的结构体中,包括联合体,但是表现出来的形式则不会一样
typedef union
{
uint8_t data;
uint8_t ERR_BIT : 1;
uint8_t STATUS_BIT : 3;
uint8_t IT_BIT : 1;
uint8_t OVER_BIT : 1;
uint8_t BUSY_BIT : 1;
uint8_t ENABLE_BIT : 1;
}STATUS_union;
若将一个字节数据赋值给联合体中的data就可以等价于:
ERR_BIT = (uint8_t)(data & 0x01);
STATUS_BIT = (uint8_t)(data & (0x07));
IT_BIT = (uint8_t)(data & (0x01));
OVER_BIT = (uint8_t)(data & (0x01));
BUSY_BIT = (uint8_t)(data & (0x01));
ENABLE_BIT = (uint8_t)(data & (0x01));
这是因为这两个数据类型的本质区别,结构体的成员内存地址是向上长的,而联合体的成员内存地址是固定的。
小端模式
与小端模式对应的是大端模式,他们代表两种相反的数据存放规律。以往最常用的是大端模式,即一组数据的高字节部分放在地址的最前面(起始地址),而低字节则放在地址的最后(最终地址),例如数据0xabcd,高字节是0xab,低字节是0xcd,若是大端模式:
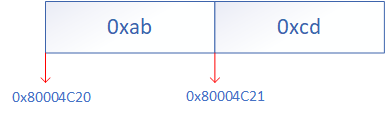
大端模式这样的排序方式比较符合人类的直觉。若是小段模式:
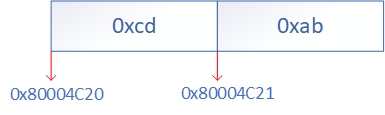
而stm32是小端模式,那么数据的低位将会被放在起始地址,根据结构体的定义,成员的空间排放顺序与声明顺序一致,也是从小到大。
三、位段数据跨字节单位导致的内存对齐现象
上述介绍的只是寻常的结构体、联合体的运用,如若出现某些有效的状态位需要跨越字节单位会怎样?例如:

测试代码(环境: vscode 64位,stm32 32位 ,ubuntu 64位):
typedef union
{
uint16_t code;
struct
{
uint8_t ENABLE : 1;
uint8_t Channel : 8;
uint8_t STATUS : 7;
};
}Type2;//热电偶配置结构体
Type2 v3;
void main(char argc,char* argv[])
{
v3.code = 0xa5da;
printf("v3.code = %x \n v3.ENABLE = %x \n v3.Chunnel = %x \n v3.STATUS = %x \n size of v3 = %d \n ",v3.code,v3.ENABLE,v3.Channel,v3.STATUS,sizeof(Type2));
}
输出:
v3.code = a5da
v3.ENABLE = 0
v3.Channel = a5
v3.STATUS = 0
size of v3 = 4
按照原本的想法:
code = 1010 0101 1101 1010 b,ENABLE = 0 ;Channel=0xed;STATUS=0x52; 造成差异的原因是在于第二个成员Channel占用了8位,但是当前字节只剩下7位了(第一个成员占了一位),由于当前空间不合适,所以编译器将会让这个成员从下一个字节开始取值。所以出现了运行结果的情况。为了进一步验证,对STATUS成员进行赋值并重新打印
void main(char argc,char* argv[])
{
v3.code = 0xa5da;
v3.STATUS = 0x75;
printf("v3.code = %x \n v3.ENABLE = %x \n v3.Chunnel = %x \n v3.STATUS = %x \n size of v3 = %d \n ",v3.code,v3.ENABLE,v3.Channel,v3.STATUS,sizeof(Type2));
}
输出:
v3.code = a5da
v3.ENABLE = 0
v3.Channel = a5
v3.STATUS = 75
size of v3 = 4
可以看到STATUS成员被成功赋值,但是联合体中code并没有体现出来,这是为什么?
实际上,从Type2类型的空间长度中可以窥见,联合体中的匿名体的空间排布应该是

从匿名体的角度去看,它只需要填充1位,因为他的成员中空间长度最大也只是一个字节,所以只需要保证内存长度被1整除即可。但是从联合体的角度去看,他的成员code是2个字节的空间长度,所以他不得不填充2个字节。而之所以打印code时没有表现出STATUS的改变,是因为code的限定词是2个字节的短整型。下面放开限定,直接输出v3的数值。读者有兴趣也可以直接在联合体中添加一个32位的成员,再打印验证。
void main(char argc,char* argv[])
{
v3.code = 0xa5da;
v3.STATUS = 0x75;
printf("v3.code = %x \n v3.ENABLE = %x \n v3.Chunnel = %x \n v3.STATUS = %x \n size of v3 = %d \n ",v3,v3.ENABLE,v3.Channel,v3.STATUS,sizeof(Type2));
}
输出:
v3.code = 75a5da
v3.ENABLE = 0
v3.Chunnel = a5
v3.STATUS = 75
size of v3 = 4
对于此性质,并没有太好的办法,大佬们可以分享自己的想法。















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









