






注:Pagerduty作为报警系统,出镜率很高。
虽然收费,但对于企业来说很便宜。
一个月几十美金
不太支持中文,主要是语音方面。
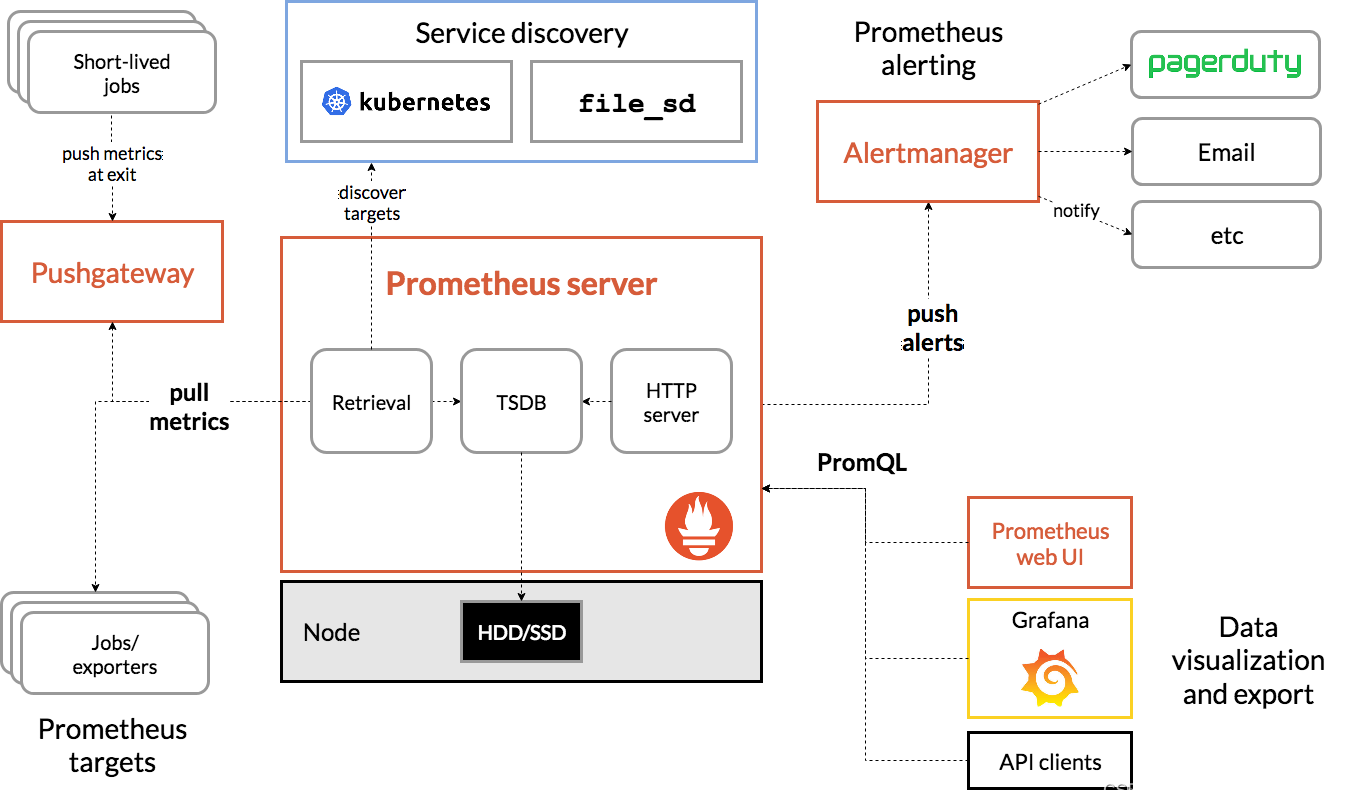
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie,webhook 等。
- 一些其他的工具。
组件详细介绍:
short-lived jobs:存在时间不足以被删除的短暂或批量业务,无法通过pull的方式拉取,需要使用push方式,与pushgeteway结合使用。
Service discovery:服务发现,prometheus支持多种服务发现机制。
Prometheus Server:用于收集和存储时间序列数据。
Client Library:客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
Exporters:prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端。
Alertmanager:从Prometheus server端接收到alerts后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉,slack等。
Grafana:监控仪表盘。
Pushgateway:各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
原理及工作流程
Prometheus server可定期从活跃的目标主机上拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据。
Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库。
Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到altermanager。
AlterManager通过配置报警接收方,发送报警到邮件,微信或者钉钉等。
Prometheus自带的web ui界面提供PromQL查询语言,可查询监控数据。
Grafana可接入prometheus数据源,把监控数据以图形化形式展示出来。
Prometheus
查询语句 , 基于数学运算模式的监控查询
我们计算一下一天多少秒
1 * 24 * 60 * 60
Console 会出现 86400
假如我想一分钟一次数据的模式获取监控数据
( 1 * 24 * 60 * 60 ) / 60
采集会是1440次
加入我想 5 秒中采集一次。
( 1 * 24 * 60 * 60 ) /5
17280
优缺点
集群搭建速度块,并且周边插件丰富。
可以嵌入到其他开源工具的内部,进行监控,数据更准确,更可信。
数据量如果特别大,那么成图的时候也会出现性能的瓶颈。
目前不支持集群化,只能自定义持久化。本身性能有一定的瓶颈。
要求硬盘消耗量比较大,和监控数据的保存周期也是关联的。
监控重点研究
监控系统设计
监控系统搭建
》监控稳定测试
数据采集编写
》监控自动化集成
》监控部署上线
》监控图形化工作
数据采集编写
监控数据分析/算法
业务监控
- 用户访问的QPS 每秒查询率(Queries Per Second)
它是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
通过曲线的变化去记录QPS的状态。业务级别监控的难点。 - 用户DAU指的是日活跃用户数量(Daily Active User)
- 访问状态(http code)
- 业务接口(登录、注册、聊条、上传、留言、短信、搜索)
- 产品转化率
- 充值额度
- 用户投诉
系统监控
- CPU
- 内存
- 硬盘
- I/O
- TCP链接
- 流量
网络监控
1.丢包率。
2.延迟。
3.IDC内网和外网的访问性(可用区)。
日志监控
ELK
往往是单独设计和搭建。
程序监控
一般需要与开发人员配合,程序中嵌入各种接口 直接获取数据或者特质的日志格式。
程序中嵌入各种接口,直接获取数据或者特质的日志格式。
数据采集编写
shell / python / awk / lua(nginx安全控制) / go 等
优点:后台采集程序,数据准确性高,采集密度精细 管理方便。
缺点:后台采集程序,如果开发过程不够仔细,可能会出现内存泄漏,僵尸进程,性能瓶颈等问题。
监控自动化
Puppet 配置文件部署
Jenkins CI持续集成部署
用户哭护短 -> 公网DNS域名 -> CDN技术 -> 云计算入口(入口机) -> 负载均衡 -> 智能负载均衡 -> 主程序集群 -> 缓存 -> 数据库。
数据库键值类型
K / V 模型
T-S 时间序列的组成方式。(prometheus命令行 可以支持 四则运算, -> 微积分 -> 代数 -> 数论)
数据采集是从 /proc 下获取数据
保存的信息会变成
block和chunk
CentOS7安装Promethous
# wget https://github.com/prometheus/prometheus/releases/download/v2.5.0/prometheus-2.5.0.linux-amd64.tar.gz
# tar xf prometheus-2.5.0.linux-amd64.tar.gz
# cp prometheus-2.5.0.linux-amd64/{prometheus,promtool} /usr/local/bin/
# prometheus --version
# cd prometheus-2.5.0.linux-amd64
# cp prometheus.yml prometheus.yml.orig
# mkdir -p /etc/prometheus
# cp prometheus.yml /etc/prometheus/
# promtool check config /etc/prometheus/prometheus.yml
# prometheus --config.file "/etc/prometheus/prometheus.yml"
docker安装
// 通过 docker 安装
# wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# docker run -d -p 9090:9090 prom/prometheus
# docker run -d -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
时序 4 种类型:Counter, Gauge, Histogram, Summary
Prometheus 时序数据分为 Counter, Gauge, Histogram, Summary 四种类型。
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用 delta, 很容易得到任意区间数据的增量,这个会在 PromQL 一节中细讲。
Gauge 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
Histogram 由 <basename>_bucket{le=“<upper inclusive bound>”},<basename>_bucket{le=“+Inf”}, <basename>_sum,<basename>_count 组成,主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
例如 Prometheus server 中 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
可以清楚的看到,正常状态有多少百分比的用户(或请求),多少属于急快的请求,多少处于慢请求,或者有问题的请求。
Summary 和 Histogram 类似,由 <basename>{quantile=“<φ>”},<basename>_sum,<basename>_count 组成,主要用于表示一段时间内数据采样结果(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
例如 Prometheus server 中 prometheus_target_interval_length_seconds。

















 4700
4700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









